
导读:为什么要使用机器来理解音频内容呢?一个重要的出发点就是在大量数据存在的情况下,由人来完成音频内容的理解是一件较为困难的事情,在图片和文本处理方面,快速理解尚有一定实现的可能,古代有一个形容人记忆力很好的成语叫做走马观碑,描述一个人骑着快马路过一个石碑,看到石碑上密密麻麻的小字一瞬间就能够全部记下来。但是对于音频与视频这种内容,即使在加速的情况下也需要一定的时间来听完、看完音频和视频内容才能够进一步理解它。如果采取人力处理这些问题会遇到困难,我们就可以借助于机器辅助人来进行处理。
机器在理解音频的过程中需要理解哪些内容呢?就需要我们来分析场景问题。
--

01 内容安全
在18年的时候,红极一时的一名主播因为在直播过程中发表一些不当的言论而遭到封杀。同样的案例还有因主播在直播过程中发表涉政相关的言论而被封杀。今年是建国70周年,很多境外的反动组织为了扩散他们的言论在某些直播平台或者社交平台散播宣传音频或者视频。他们通常用录音机等播放设备将提前录制好的音频和视频连续不断地进行播放,这是一个典型的社交问题。
此外,直播中还存在较多的色情问题,包括视频、图像方面的色情,也包括音频方面的色情。有时也会有广告导流行为,所谓广告导流就是在某一个直播平台上,大家在音视频交流过程中有人发类似于我们私下加个微信聊吧,这样这个平台的流量就会被导走。我们的工作就是要在音频中识别出这些行为,为这些行为打上标签,让运营平台知道这些音频中存在这样或者那样的问题。以上所分析的问题完全属于截流问题。
02 内容运营
内容理解的优势在于可以进行内容推荐,一个典型的例子就是在交友的社交平台上,如果通过声音识别出是一位大叔,就可以给他推荐一位萝莉,如果声音识别是一位御姐,就可以推荐给她一个正太,这样就有希望延长他们之间的交流时间。
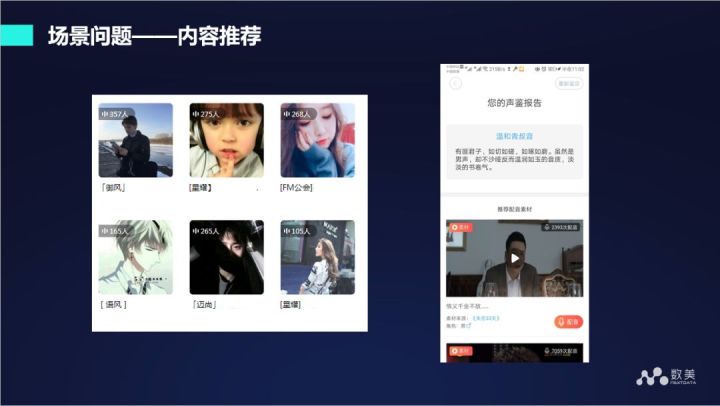
内容理解核心的解释就是将非结构化的内容结构化,其中重要的途径是标签,通过各种手段为音频或者视频打上各种标签,方便后面去做各种处理。比如拦截和推荐。
--
03 解决方案
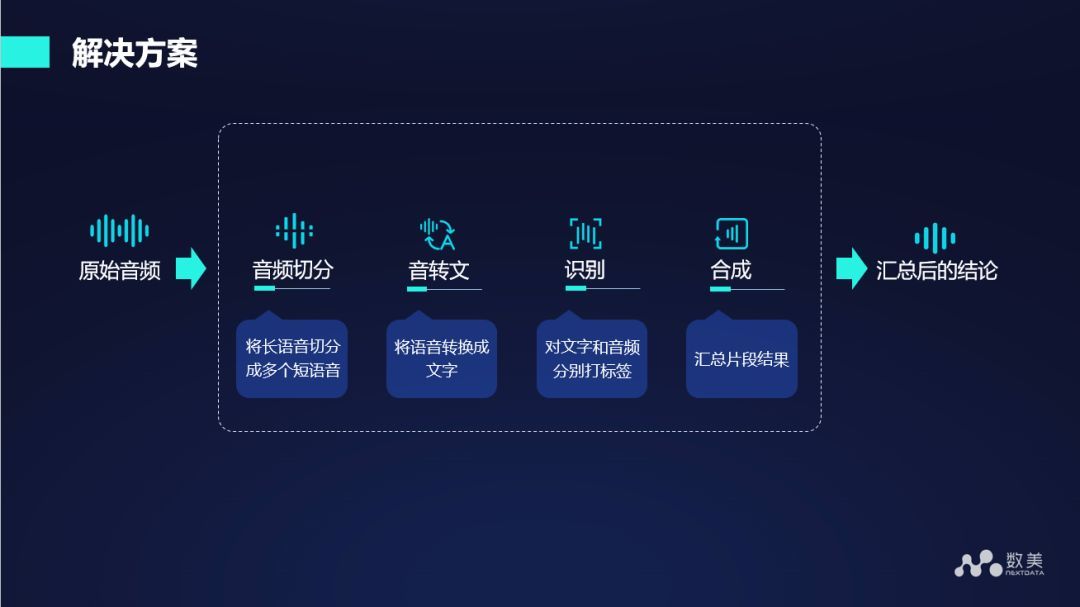
对于上述问题,我们的解决方案主要包括四个步骤:
- 音频切分:在得到原始音频之后首先对音频进行切分,将长语音切分为多个短语音
- 音转文:将语音转换成文字
- 识别:对文字和音频分别打标签
- 合成:汇总片段结果,并给出最终的整条语句或者整个视频。
内容理解的过程中存在一定的困难,比如远场识别,对于直播来说识别过程中最大的困难是混响和噪声。主播在直播过程中为了吸引更多的人观看通常会唱歌,唱歌一般都会加混响来使歌声听起来有绕梁三日的感觉。但是这种情况就会对语音识别产生较大的影响。此外,我们在使用语音搜索和语音输入法的过程中为了获得更加正确的结果会故意放慢说话速度,表达相对更加清晰。而直播过程中为了获得良好的互动,说话都会比较随意。唱歌也是一个比较难解决的问题,在语音识别建模的过程中,很多情况下都是使用带音调的音素来进行建模,但是在唱歌的过程中语音的声调会发生变化。这样也会引起识别不准确的问题。目前已经有很多有效的方法来解决这些问题。

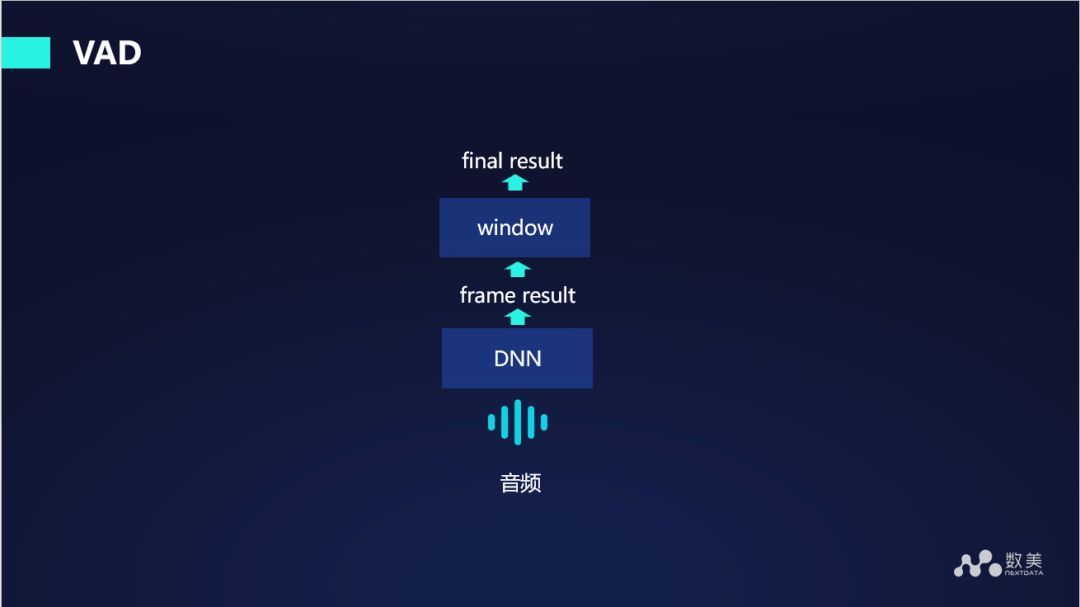
下面介绍下解决上述问题的相关工作,首先是音频切割(VAD),这种技术是比较主流的一种方法,先通过深度学习 DNN 来预测出一段音频是静音还是非静音。然后通过加窗得到最终的结果。
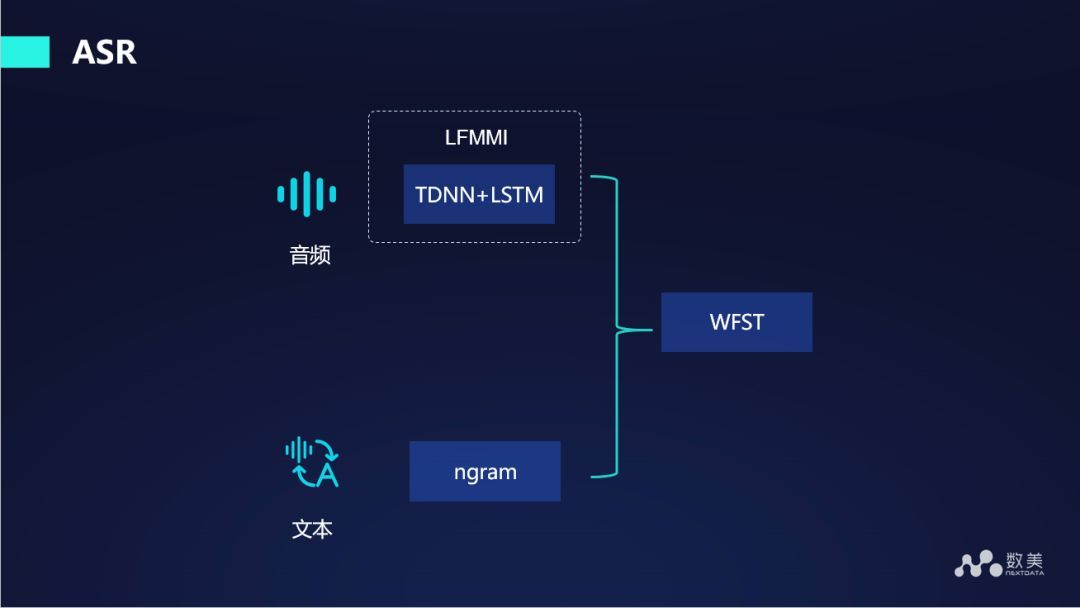
在语音转写文字的过程中,采用 DNN+LSTM,然后使用 lattice-free MMI 方法训练现有模型,我们使用的语言模型是 ngram 方式。这是一个相对比较主流的框架。目前 ASR 主要解决的是把音频中的文字提取出来。
前面我们提到还有一部分语音识别不能通过转文字获得。比如是否有音乐,播放音乐的名称,是否存在色情声音等等。我们采用声音分类的框架来解决这个问题。首先需要对音频进行数据增强,因为在音频分类条件下数据的 label 并不均衡,特别是存在一些小众的声音,非常稀少,所以需要对这些数据进行增强。我们使用 TDNN+bi-GRU+Attention 框架。

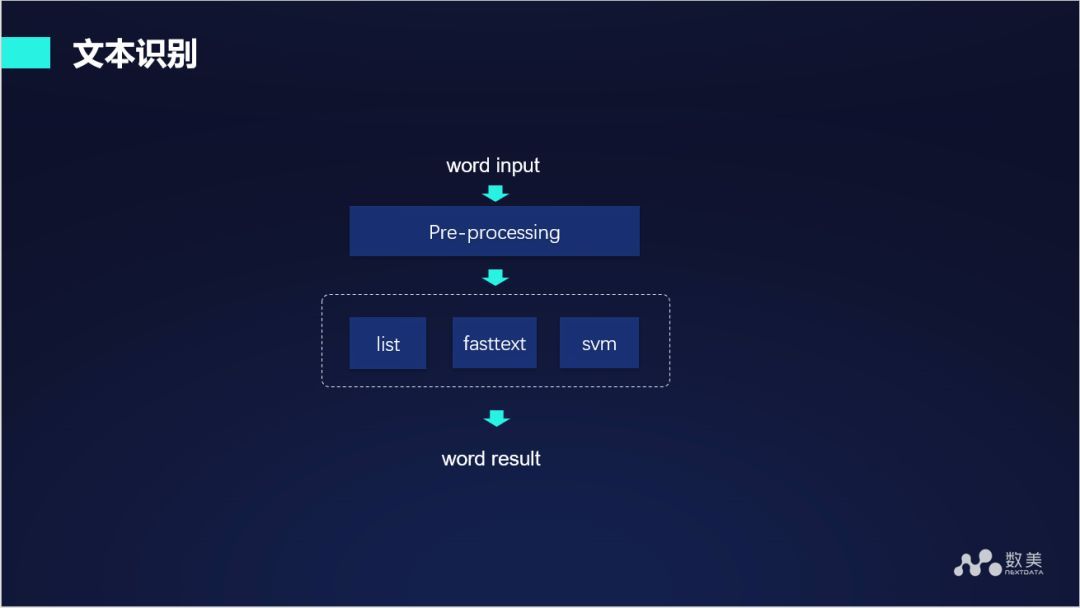
上述第一步将音频转换成文字,第二步将分类信息标签集,第三步需要对转换出来的文字进行文字识别,文字识别主要包括文字的分类:基于一段文字判断它所属的类别,比如这段文字是不是属于色情话题或者是带有辱骂性等。模型不能完全解决这方面的问题,还需要有关键词类比。我们给出的框架通过 fasttext 模型或者一些传统的机器学习算法来进行模型分类,同时联合关键词信息进行处理。在使用模型训练之前首先对文本进行预处理,比如分词、归一化等。
最后一步是行为识别,例如境外反动组织要去散播反动言论会在平台上开很多账号,对于每个账号不会雇佣不同的人去宣传言论,而是使用录制好的音频来播放相同的言论内容,这样他的行为就会有一定的聚集性,在这种设备或者 IP 上的具体行为可以通过一个逻辑回归模型来打分。通过分数判断这个行为是不是存在问题。行为识别也可以检测出一些有问题的内容。

下图是我们整个框架的架构图,将上述我们分析的各个模块整合在一起。在模型层面包括 ASR 模型、文字相关模型、声音相关模型、行为相关模型、名单库等。通过引擎层输出各种各样的分数,最后我们有一套规则,规则引擎会对所有模型层面和画像层面输出的结果进行汇总,最终得到结论。

下面是我们真实的一个价值体现,某直播平台同时采用用户举报、人工抽审、数美智能审核三种方案监测平台直播内容。用户举报平均每天抓出1个违规音频,人工抽审平均每天抓出20个违规音频(审核团队30人),数美智能审核系统平均每天抓出160个违规音频,同时数美智能审核系统反馈音频转文字结果、自动记录违规音频位置、发生时间等信息。

今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”
注:欢迎转载,转载请留言或私信。