5.2 基于压缩的高效存储
(仅包括技术25,和技术26)
数据压缩可以减小数据的大小,节约空间,提高数据传输的效率。在处理文件中,压缩很重要。在处理Hadoop的文件时,更是如此。为了让Hadoop更高效处理文件,就需要选择一个合适的压缩编码器,加快作业运行,增加集群的数据存储能力。
技术25 为待处理数据选择正确的压缩编码器
在HDFS上使用压缩并不像ZFS文件系统上那样透明,特别是在处理那些可分块的压缩文件时。(这些将在本章中稍后介绍。)由于Avro和SequenceFiles等文件格式提供了压缩的内置支持,使用它们就相对透明。但是如果使用它们,会导致没有办法使用其他的文件格式。
问题
需要为待处理数据评估并选择最优压缩格式。
方案
Snappy,一个来自于Google的压缩编码器,在压缩大小和读写时间上取得了最佳平衡。然而,如果要考虑到处理超大文件时对可分块特性的支持,LZOP将是最佳的编码器。
讨论
首先看看Hadoop中可用的压缩编码器,如表5.1所示:
表5.1 压缩编码器
| 编码器 | 背景 |
| Deflate |
Deflate和zlib类似,使用gzip的压缩算法,但不包含gzip的文件头。 |
| gzip |
gzip文件格式包含一个文件头和文件体。文件体的压缩算法和defalte一样。 |
| bzip2 |
bzip2是空间优先的压缩编码器。 |
| LZO |
LZO是基于块的压缩算法。压缩文件可以分块。 |
| LZOP |
LZOP是在LZO上加上一个文件头。曾经LZO和LZOP都是Hadoop的一部分。后来由于GPL授权限制被移除了。 |
| Snappy |
Snappy是Hadoop中新近支持的编码器选项。(参考http://code.google.com/p/hadoop-snappy/。)它是Google的开源压缩算法。Google在MapReduce和BigTable中使用它来压缩数据。它的最大问题是无法分块。如果文件和HDFS块大小相当,那么就可以使用Snappy。如果文件大于HDFS块,那么效率就会很低。CDH3中提供了Snappy。但是Apache Hadoop中对Snappy的支持还不完全能满足生产环境的要求。(参考 https://issues.apache.org/jira/browse/HADOOP-7206。) |
在评估编码器之前,先要明确评估标准。评估标准是基于功能性需求和性能需求制定的。评估标准可能包括如下内容:
- 空间/时间取向 —— 一般来说,压缩文件越小(并且消耗时间越长),压缩比率越好。
- 可分块特性 —— 压缩文件是否能够被分块,以便在多个map任务中处理?如果压缩文件不能分块,那么只有一个map任务可以处理它。如果文件占据了很多HDFS块,将损失数据的本地性。也就是说,map任务很可能需要从远程数据节点读取苦块,增大网络IO的负担。
- 是否是本地库内置的压缩支持 —— 采用的压缩编码器是否是本地的库。如果采用非本地的JAVA编码器,性能很可能下降。
|
运行自定义测试 在进行评估的时候,最好能够编写测试压缩性能的测试。测试环境与生产环境类似为佳。通过测试可以了解压缩率和编码器的压缩时间。 |
接下来看看可用的压缩编码器的横向对比。如表5.2所示:(空间/时间的比较将在下一部分)
表5.2 压缩编码器横向比较
| 编码器 | 扩展名 | 版权 | 可分块 | 只支持JAVA压缩 | 本地库压缩支持 |
| Deflate | .deflate | zlib | No | Yes | Yes |
| gzip | .gz | GNU GPL | No | Yes | Yes |
| bzip2 | .gz | BSD | Yes | Yes | No |
| lzo | .lzo_deflate | GNU GPL | No | No | Yes |
| lzop | .lzo | GNU GPL | Yes | No | Yes |
| Snappy | .gz | New BSD | No | No | Yes |
那么在考虑空间/时间取向的时候,这些编码器表现如何呢?以下是基于128MB文本文件的压缩性能测试。结果见表5.3:
表5.3 基于128MB文本文件的压缩性能测试横向比较
| 编码器 | 压缩时间(秒) | 解压缩时间(秒) | 压缩文件大小 | 压缩比率 |
| Deflate | 6.88 | 6.80 | 24,866,259 | 18.53% |
| gzip | 6.68 | 6.88 | 24,866,271 | 18.53% |
| bzip2 | 3,012.34 | 24.31 | 19,270,217 | 14.36% |
| lzo | 1.69 | 7.00 | 40,946,704 | 30.51% |
| lzop | 1.70 | 5.62 | 40,946,746 | 30.51% |
| Snappy | 1.31 | 6.66 | 46,108,189 | 34.45% |
图5.3用柱状图描述了压缩文件大小。

图5.4用柱状图表示压缩时间。由于硬件差异,这些时间差别很大。给出这些时间只是为了说明它们之间的相关性。
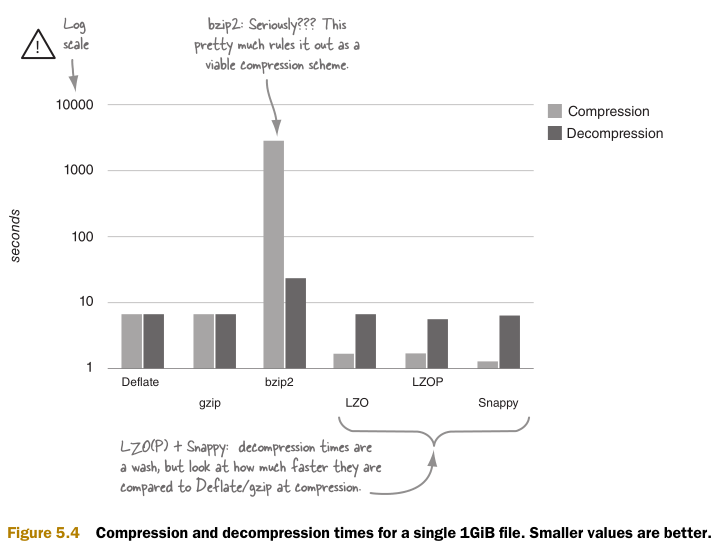
那么可以从时间空间的结果数据中得到什么呢?如果需要在集群中处理尽可能多的数据,并可以忍受很长的压缩时间,那么bzip2是最佳选择。如果需要尽可能减少读写压缩文件时的CPU消耗,那么应该选择Snappy。如果需要在空间和时间中取得平衡。那么就要考虑bzip2之外的选择了。
如果可分块特征非常重要,那么就需要在bzip2和LZOP之间选择。由于bzip2实在太慢,可能就要选择LZOP了。另外,在hadoop中使用LZOP不如bzip2方便。接下来将介绍如何使用bzip2。
小结
最优的解码器的选择完全取决于选择标准。如果不考虑可分块性,Snappy是最佳选择。如果考虑可分块性,LZOP是很不错的选择。
文本文件和二进制文件的压缩大小不同。不同文件内容的压缩不同。在使用压缩前进行测试得到压缩比率是很有必要的。
在HDFS中压缩数据有很多好处,减小文件大小,加快MapReduce作业运行。在Hadoop中有多个压缩编码器可以选择。它们的特性和性能各部相同。接下来就介绍如何在MapReduce,Pig和Hive中使用数据压缩。
技术26 在HDFS,MapReduce,Pig和Hive中使用数据压缩
由于HDFS并不提供对压缩的内置支持,在Hadoop中使用压缩就不那么容易,需要手动实现数据压缩。另外,可分块压缩并不适合心灵脆弱的人,因为Hadoop并不直接支持它。如果只是处理和HDFS块大小相当的中等大小的文件,本技术将是即快又简单。
问题
需要在HDFS中读写压缩文件,并在MapReduce,Pig和Hive中使用它们。
方案
在MapReduce中处理压缩文件需要配置Mapred-site.xml,注册压缩编码器。然后可以在MapReduce将压缩文件作为输入文件。如果需要在MapReduce中输出压缩文件,需要配置MapReduce属性mapred.output.compress和mapred.output.compression.codec。
讨论
第一步是如何在MapReduce中用前述的编码器读取并写入文件。除了LZO,LZOP和Snappy,其它的编码器都都由Hadoop提供了。如果需要使用没有提供的编码器,就需要手动下载并编译。
表5.4种给出了可以用到的编码器的类名。
表5.4 编码器的类
| 编码器 | 类名 |
| Deflate | org.apache.hadoop.io.compress.DeflateCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| lzo | com.hadoop.compression.lzo.LzoCodec |
| lzop | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
HDFS
以下代码给出了如何压缩一个已经在HDFS中的文件:
1 Configuration config = new Configuration(); 2 FileSystem hdfs = FileSystem.get(config); 3 Class<?> codecClass = Class.forName(args[2]); 4 CompressionCodec codec = (CompressionCodec) 5 ReflectionUtils.newInstance(codecClass, config); 6 InputStream is = hdfs.open(new Path(args[0])); 7 OutputStream os = hdfs.create(new Path(args[0] + codec.getDefaultExtension())); 8 OutputStream cos = codec.createOutputStream(os); 9 IOUtils.copyBytes(is, cos, config, true); 10 IOUtils.closeStream(os); 11 IOUtils.closeStream(is);
| 缓存编码器
压缩编码器的创建成本很高。使用Hadoop的ReflectionUtils类可以缓存创建的实例,以加速后续的编码器实例创建。一个更好的选项是使用CompressionCodecFactory。它提供了编码器的缓存功能。 |
以下代码实现了读取HDFS中的压缩文件:
1 InputStream is = hdfs.open(new Path(args[0])); 2 Class<?> codecClass = Class.forName(args[1]); 3 CompressionCodec codec = (CompressionCodec) 4 ReflectionUtils.newInstance(codecClass, config); 5 InputStream cis = codec.createInputStream(is); 6 IOUtils.copyBytes(cis, System.out, config, true); 7 IOUtils.closeStream(is);
接下来介绍如何在MapReduce中使用压缩文件。
MAPREDUCE
在MapReduce中使用压缩文件,需要设置作业的一些参数。简单起见,假定map和reduce之间没有任何过滤和转换。
1 Class<?> codecClass = Class.forName(args[2]); 2 conf.setBoolean("mapred.output.compress", true); // Compress the reducer output. 3 conf.setBoolean("mapred.compress.map.output", true); // Compress the mapper output 4 conf.setClass("mapred.output.compression.codec", codecClass, CompressionCodec.class); 5 // The compression codec for compressing mapper output.
在MapReduce作业中处理压缩文件和非压缩文件的区别在于上述代码中的三行注释。
不仅仅是作业的输入和输入可以被压缩,中间过程的map输出也可以被压缩。因为map先输出到磁盘上,然后通过网络传输给reduce。压缩map的输出的效率的高低取决于被压缩对象的数据类型。一般来说,数据压缩都可以带来一定程度的效率提升。
为什么在代码中不需要指定输入文件的压缩编码器?FileInputFormat类使用CompressionCodecFactory来根据输入文件扩展名决定使用相匹配的已注册编码器。
MapReduce如何知道使用哪个编码器?相应的配置文件时mapred-site.xml。以下代码说明了如何注册前述编码器。注意,除了gzip,Deflate和bzip2,其他的编码器在注册前都需要手动编译并存放在集群上。
1 <property> 2 <name>io.compression.codecs</name> 3 <value> 4 org.apache.hadoop.io.compress.GzipCodec, 5 org.apache.hadoop.io.compress.DefaultCodec, 6 org.apache.hadoop.io.compress.BZip2Codec, 7 com.hadoop.compression.lzo.LzoCodec, 8 com.hadoop.compression.lzo.LzopCodec, 9 org.apache.hadoop.io.compress.SnappyCodec 10 </value> 11 </property> 12 <property> 13 <name> 14 io.compression.codec.lzo.class 15 </name> 16 <value> 17 com.hadoop.compression.lzo.LzoCodec 18 </value> 19 </property>
到这里就是全部的如何在MapReduce中处理压缩文件了。Pig和Hive是高层次语言,抽象了MapReduce中的一些底层细节。接下来介绍如何在Pig和Hive中使用压缩文件。
PIG
和MapReduce不同的是,Pig并不需要额外的代码来处理压缩文件。在使用Pig的本地库时,要保证Pig的JVM的java.library.path包括了本地库的地址。下列脚本用于为Pig设置正确的路径以读取本地库:
$ bin/pig-native-opts.sh
export PIG_OPTS="$PIG_OPTS -Djava.library.path=/usr/lib/..."
$ export PIG_OPTS="$PIG_OPTS -Djava.library.path=/usr/..."
为了让Pig能够处理压缩文件,还需要为压缩文件添加正确的扩展名。以下例子给出了如何压缩文件并读取到Pig中:
$ gzip -c /etc/passwd > passwd.gz $ hadoop fs -put passwd.gz passwd.gz $ pig grunt> A = load 'passwd.gz' using PigStorage(':'); grunt> B = foreach A generate $0 as id; grunt> DUMP B; (root) (bin) (daemon) ...
Pig中输出到gzip文件的过程类似,同样需要指定文件扩展名。以下例子将Pig的关系B的结果存储到HDFS的一个文件中,并把它们复制到本地文件系统中以查看内容:
grunt> STORE B INTO 'passwd-users.gz'; # Ctrl+C to break out of Pig shell $ hadoop fs -get passwd-users.gz/part-m-00000.gz . $ gunzip -c part-m-00000.gz root bin daemon ...
很简单。希望Hive中也是一样。
HIVE
和Pig中一样,需要做的就是在定义文件名时制定和编码器相匹配的扩展名:
hive> CREATE TABLE apachelog (...); hive> LOAD DATA INPATH /user/aholmes/apachelog.txt.gz OVERWRITE INTO TABLE apachelog;
上述例子讲gzip压缩文件装载到了Hive中。在这个例子中,Hive将装载的文件移动到了Hive的仓库目录中,并使用raw文件作为表的存储。如何创建另外一个表,并制定表必须被压缩。以下代码通过Hive的配置启用了MapReduce压缩:(MapReduce作业将在最后一个语句中被调用来读取新表)
hive> SET hive.exec.compress.output=true; hive> SET hive.exec.compress.intermediate = true; hive> SET mapred.output.compression.codec = org.apache.hadoop.io.compress.GzipCodec; hive> CREATE TABLE apachelog_backup (...); hive> INSERT OVERWRITE TABLE apachelog_backup SELECT * FROM apachelog;
通过以下脚本可以检测Hive中apachelog_backup表的压缩结果(在HDFS上):
$ hadoop fs -ls /user/hive/warehouse/apachelog_backup
/user/hive/warehouse/apachelog_backup/000000_0.gz
需要注意的是,Hive推荐使用SequenceFile作为表的输出格式,因为SequenceFile可以分块压缩。
小结
这个技术提供了在Hadoop中压缩了的简便方法。对于不大的文件,这也是一个相对透明的方法。
如果压缩文件大小大于HDFS块的大小,就需要参考技术27中的分块压缩技术了。
(译注:本节原文较长,剩余部分将在下一篇文章翻译。)