6.2.4 任务一般性能问题
这部分将介绍那些对map和reduce任务都有影响的性能问题。
技术37 作业竞争和调度器限制
即便map任务和reduce任务都进行了调优,但整个作业仍然会因为环境原因运行缓慢。
问题
需要判断作业是否运行得比集群中其它作业要慢。
方案
将正在执行的reduce任务数和Hadoop集群的最大reduce任务数相比较。
讨论
如果根据前几节的技术,发现作业已经正确配置,任务的吞吐量也正确,那么作业的缓慢就有可能是集群的资源竞争了。下面将介绍如何诊断集群的资源竞争。
JobTracker可以查看正在运行的作业的map和reduce任务的并发数,以及集群的最大并发负载能力(Capacity)。图6.21说明了如何将这些数据进行比较。
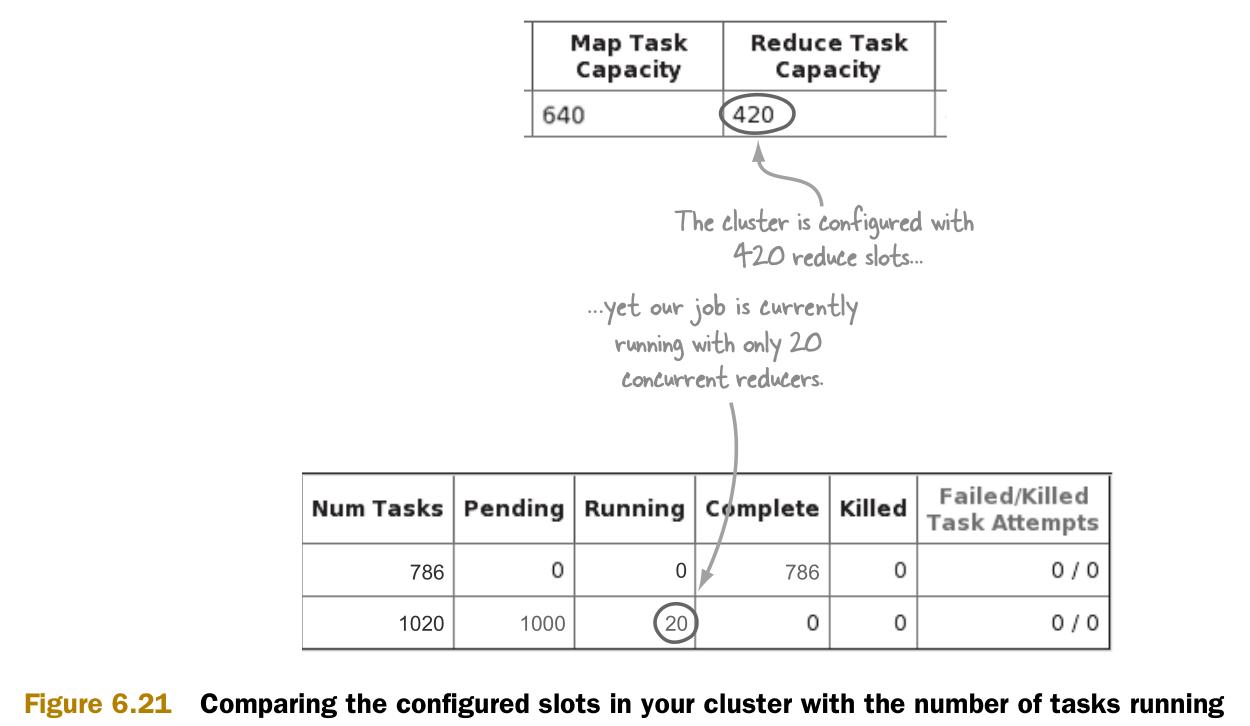
图中显示了正在运行的reduce实例数远远小于集群的最大并发负载能力。
小结
集群提供的并发能力将会倍所有正在运行的作业,调度器等共享。这些信息可以用JobTracker UI查看。如果存在同时运行的作业,那么对作业的吞吐量的优化就变得较为复杂。
默认情况下,MapReduce使用一个先进先出(FIFO)的调度器来分配并发作业间的资源。也就是说,先提交的作业将会被先执行。后提交的作业需要等待先提交的作业执行完毕。在有的情况下,为了让资源可以被更好的分配,需要根据作业的重要性来使用公正(Fair)调度器或处理能力(Capacity)调度器。此外,还可以自定义调度器,让有的作业得到比其他作业更多的资源。
技术38 使用堆转存(stack dump)来查找未优化的用户代码
效率低下的用户代码会拖累整个作业。例如,在JAVA中常见的字符令牌化技术实际上很没效率,很容易延长作业的运行时间。
问题
需要确定是否因为用户代码导致作业运行缓慢。
方案
对堆转存进行分析,找到用户代码中的性能瓶颈。这需要确认正在运行的任务的主机和进程ID。获取一系列的堆转存。
讨论
在MapReduce1.0.0和更早的版本中并不提供Map和Reduce任务中的用户代码的执行时间的指标。在这种情况下也许需要更新代码,记录用户代码的执行时间。不过在这个技术中,也许不一定需要更新代码。
在技术30(6.2.2)中介绍了如何计算map任务的吞吐量。本技术中的计算基于map的执行时间和输入数据的大小。基本计算方法和技术35(6.2.3)类似。
如果用户代码效率不够,那么吞吐量也会随之下降。但吞吐量偏低并不意味着用户代码效率低下。这就要依靠前几节介绍方法排除其它的可能。
同时,还可以根据任务进程的堆转存来诊断用户代码的效率。图6.22介绍了如何得到作业和任务的细节信息。
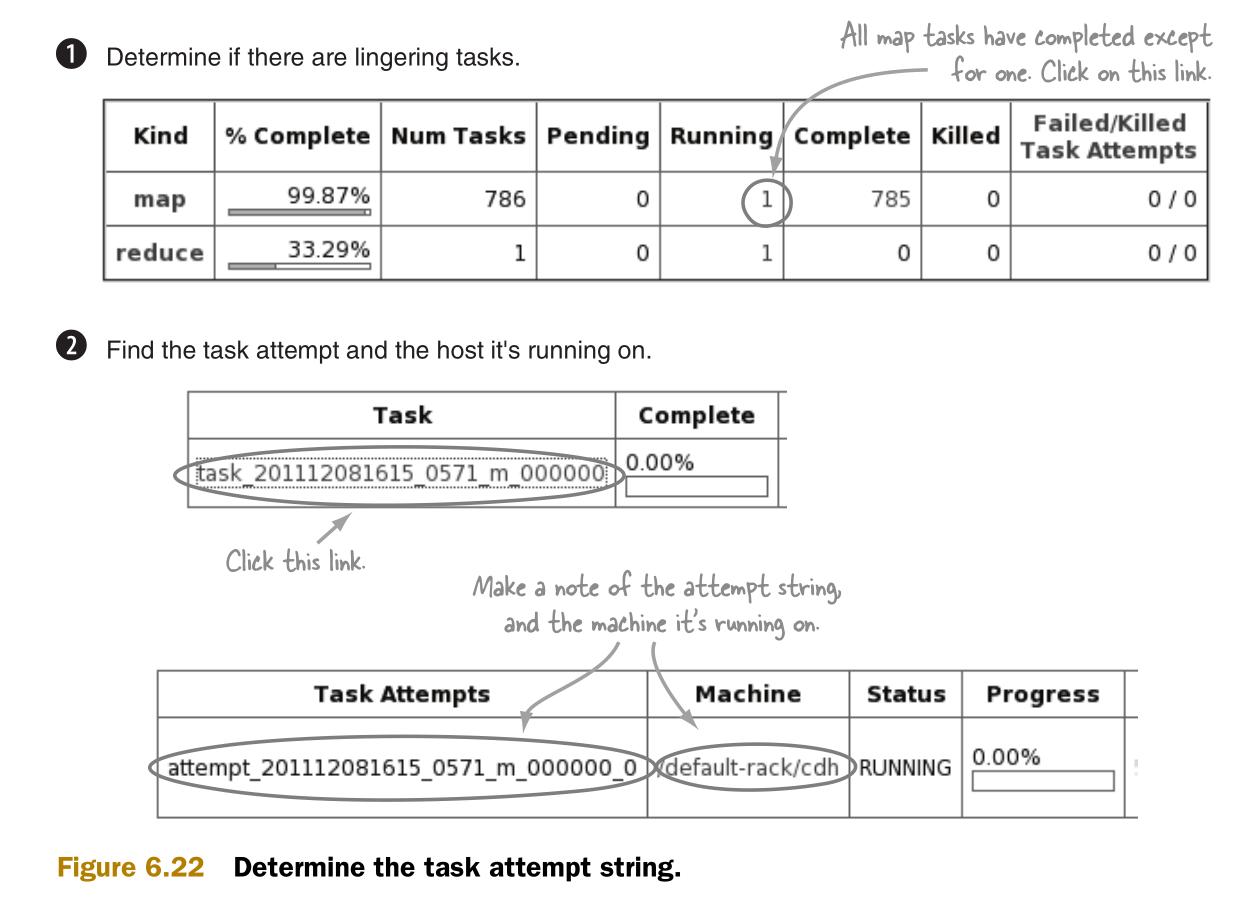
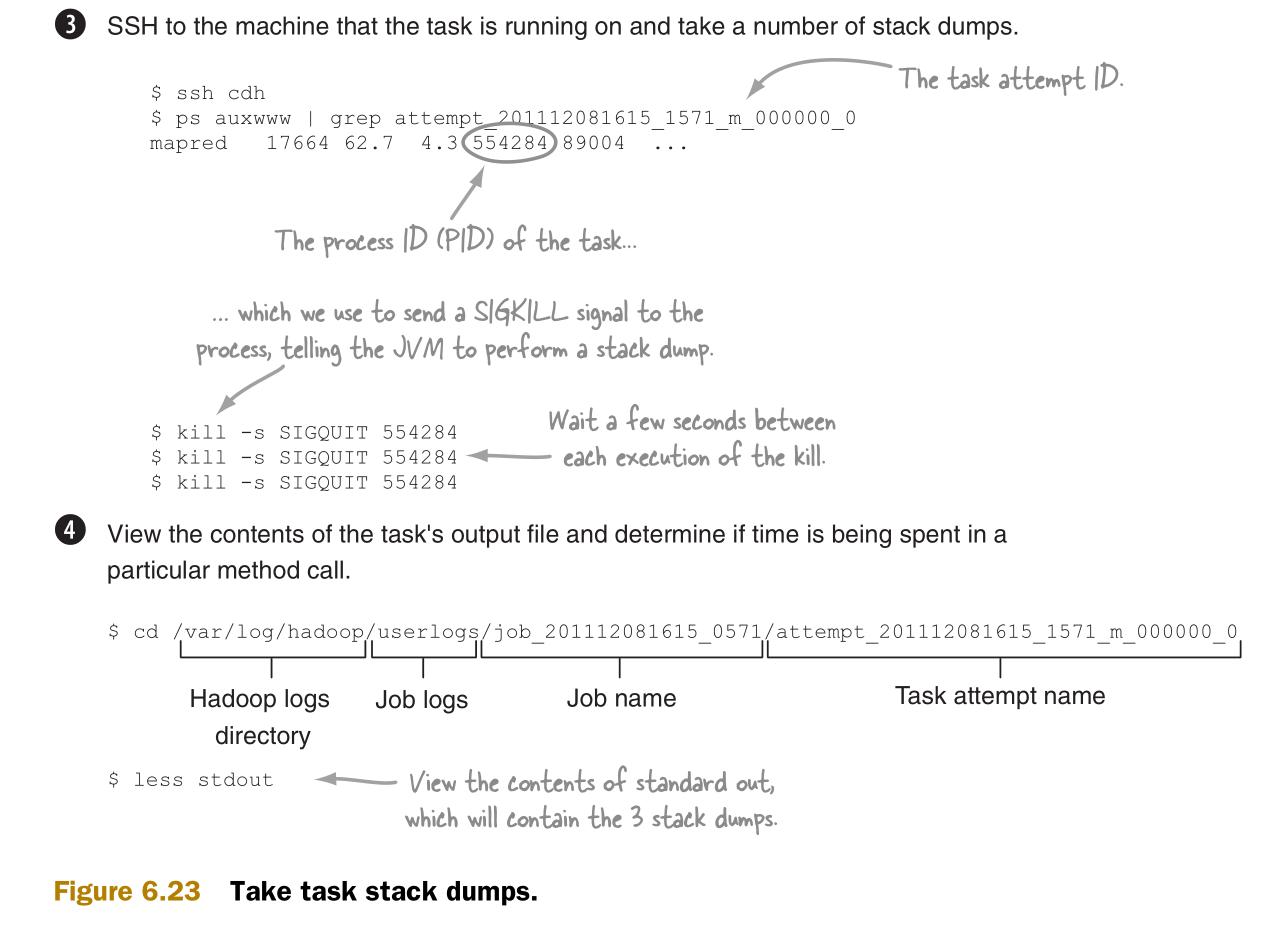
图6.23介绍了如何获取堆转存。
小结
使用堆转存查看JAVA进程的运行时间看起来很原始,其实很高效。对于那些CPU绑定的进程更是如此。不得不说堆转存没有探查器(profiler)更有效,更精确。然而相比于探查器需要配置并重启JVM,堆转存就不需要在MapReduce中很麻烦的这一步了。因此它应用领域更广泛。
当获取堆转存的时候,最好能够每隔一段时间获取一次。这样,就可以通过比较这些堆转存来查找原因。如果发现了不同的堆转存中存在相同的正在执行的代码,那么这些代码就很有可能是拖累整体速度的原因。
如果没有发现上述状况,也不代表不存在低效的代码。那么接下来就需要在代码中加入一些计时器来获取精确的执行时间了。