http://lihengxu.cn/2021/03/08/MySQL%E5%9F%BA%E7%A1%80/
1.1 数据库相关概念
- 数据库的常见概念 ★
1、DB:数据库,存储数据的容器
2、DBMS:数据库管理系统,又称为数据库软件或数据库产品,用于创建或管理DB
3、SQL:结构化查询语言,用于和数据库通信的语言,不是某个数据库软件特有的,而是几乎所有的主流数据库软件通用的语言三者关系 -
三者关系。客户端通过DBMS,DBMS执行它自己的听得懂的语言即sql,sql去操作DB
- 数据库存储数据的特点
1、数据存放到表中,然后表再放到库中
2、一个库中可以有多张表,每张表具有唯一的表名用来标识自己
3、表中有一个或多个列,列又称为“字段”,相当于java中“属性”
4、表中的每一行数据,相当于java中“对象”
- 常见的数据库管理系统
mysql、oracle、db2、sqlserver
1.2 MySQL介绍
-
MySQL的背景
前身属于瑞典的一家公司,MySQL AB
08年被sun公司收购
09年sun被oracle收购 -
MySQL的优点
- 开源、免费、成本低
- 性能高、移植性也好
- 体积小,便于安装
-
MySQL服务的启动和停止
- 方式一:通过命令行
1
2net start 服务名
net stop 服务名 - 方式二:计算机——右击——管理——服务
- 方式一:通过命令行
-
MySQL服务的登录和退出
-
登录:
1mysql 【-h 主机名 -P 端口号】 -u 用户名 -p密码 -
退出:
1exit 或 ctrl+C
-
-
MySQL的常见命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 1.查看当前所有的数据库
show databases;
# 2.打开指定的库
use 库名
# 3.查看当前库的所有表
show tables;
# 4.查看其它库的所有表
show tables from 库名;
# 5.创建表
create table 表名( #mysql>create table stuinfo(id int,name varchar(20))
列名 列类型,
列名 列类型,
...
);
# 6.查看表结构
desc 表名;
# 7.查看服务器的版本
# 方式一:登录到mysql服务端
select version();
# 方式二:没有登录到mysql服务端
mysql --version
# 或
mysql --V -
MySQL的语法规范
-
不区分大小写,但建议关键字大写,表名、列名小写
-
每条命令最好用分号结尾
-
每条命令根据需要,可以进行缩进 或换行
-
注释
-
单行注释:#注释文字
-
单行注释:– 注释文字
-
多行注释:/* 注释文字 */
-
-
-
SQL的语言分类
- DQL(Data Query Language):数据查询语言
select - DML(Data Manipulate Language):数据操作语言
insert 、update、delete - DDL(Data Define Languge):数据定义语言
create、drop、alter - TCL(Transaction Control Language):事务控制语言
commit、rollback
- DQL(Data Query Language):数据查询语言
2. DQL语言
2.1 基础查询
1
|
|
2.2 条件查询
1
|
|
经典面试题 :
1
|
|
2.3 排序查询
1
|
|
2.4 常见函数
- 功能:类似于java中的方法
- 好处:提高重用性和隐藏实现细节
- 调用:select 函数名(实参列表);
单行函数
1
|
|
分组函数(统计函数\聚合函数)
1
|
|
2.5 分组查询
1
|
|
2.6 连接查询
1
|
|
2.7 子查询
1
|
|
2.8 分页查询
1
|
|
2.9 联合查询
1
|
|
2.10 查询语句总结
1
|
|
3. DML语言
数据操作语言:
插入:insert
修改:update
删除:delete
3.1 插入语句
方式一:
1
|
|
方式二:
1
|
|
对比两种方式:
1
|
|
3.2 修改语句
语法:
1
|
|
示例:
1
|
|
3.3 删除语句
方式一:
1
|
|
示例:
1
|
|
方式二:
1
|
|
示例:
1
|
|
delete 对比 truncate [面试题]
delete 可以加where 条件,truncate不能加
truncate删除,效率高一丢丢
假如要删除的表中有自增长列,如果用delete删除后,再插入数据,自增长列的值从断点开始,而truncate删除后,再插入数据,自增长列的值从1开始。
truncate删除没有返回值,delete删除有返回值
truncate删除不能回滚,delete删除可以回滚.
4. DDL语言
数据定义语言 –> 库和表的管理
一、库的管理
创建、修改、删除二、表的管理
创建、修改、删除
创建: create
修改: alter
删除: drop
4.1 库的管理
1
|
|
4.2 表的管理
1
|
|
4.3 数据类型
常见的数据类型
数值型:
整型
小数:
定点数
浮点数
字符型:
较短的文本:char、varchar
较长的文本:text、blob(较长的二进制数据)
日期型
整型
-
分类:
tinyint、smallint、mediumint、int/integer、bigint
1 2 3 4 8 -
特点:
① 如果不设置无符号还是有符号,默认是有符号,如果想设置无符号,需要添加unsigned关键字
② 如果插入的数值超出了整型的范围,会报out of range异常,并且插入临界值
③ 如果不设置长度,会有默认的长度
长度代表了显示的最大宽度,如果不够会用0在左边填充,但必须搭配zerofill使用!
1
|
|
小数
-
分类:
- 浮点型
float(M,D)
double(M,D) - 定点型
dec(M,D)
decimal(M,D)
- 浮点型
-
特点:
①
M:整数部位+小数部位
D:小数部位
如果超过范围,则插入临界值②
M和D都可以省略
如果是decimal,则M默认为10,D默认为0
如果是float和double,则会根据插入的数值的精度来决定精度③
定点型的精确度较高,如果要求插入数值的精度较高如货币运算等则考虑使用
-
原则:
所选择的类型越简单越好,能保存数值的类型越小越好
1
|
|
字符型
-
较短的文本:
char varchar
-
其他:
binary和varbinary用于保存较短的二进制
enum用于保存枚举
set用于保存集合 -
较长的文本:
text
blob(较大的二进制) -
char/varchar 对比
| 写法 | M的意思 | 特点 | 空间的耗费 | 效率 | |
|---|---|---|---|---|---|
| char | char(M) | 最大的字符数,可以省略,默认为1 | 固定长度的字符 | 比较耗费 | 高 |
| varchar | varchar(M) | 最大的字符数,不可以省略 | 可变长度的字符 | 比较节省 | 低 |
- enum和set不区分大小写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16CREATE TABLE tab_char(
c1 ENUM('a','b','c')
);
INSERT INTO tab_char VALUES('a');
INSERT INTO tab_char VALUES('b');
INSERT INTO tab_char VALUES('c');
INSERT INTO tab_char VALUES('m');
INSERT INTO tab_char VALUES('A');
SELECT * FROM tab_char;
CREATE TABLE tab_set(
s1 SET('a','b','c','d')
);
INSERT INTO tab_set VALUES('a');
INSERT INTO tab_set VALUES('A,B');
INSERT INTO tab_set VALUES('a,c,d');
日期型
- 分类:
date只保存日期
time 只保存时间
year只保存年
datetime保存日期+时间
timestamp保存日期+时间
| 写法 | 范围 | 时区等的影响 | |
|---|---|---|---|
| datetime | 8 | 1000-9999 | 不受 |
| timestamp | 4 | 1970-2038 | 受 |
1
|
|
4.4 常见约束
-
含义:一种限制,用于限制表中的数据,为了保证表中的数据的准确和可靠性
-
分类:六大约束
-
NOT NULL:非空,用于保证该字段的值不能为空
比如姓名、学号等 -
DEFAULT:默认,用于保证该字段有默认值
比如性别 -
PRIMARY KEY:主键,用于保证该字段的值具有唯一性,并且非空
比如学号、员工编号等 -
UNIQUE:唯一,用于保证该字段的值具有唯一性,可以为空
比如座位号 -
CHECK:检查约束【mysql中不支持】
比如年龄、性别 -
FOREIGN KEY:外键,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值
在从表添加外键约束,用于引用主表中某列的值
比如学生表的专业编号,员工表的部门编号,员工表的工种编号
-
-
添加约束的时机:
1.创建表时 2.修改表时 -
约束的添加分类:
- 列级约束:
六大约束语法上都支持,但外键约束没有效果 - 表级约束:
除了非空、默认,其他的都支持1
2
3
4
5CREATE TABLE 表名(
字段名 字段类型 列级约束,
字段名 字段类型,
表级约束
)
- 列级约束:
- 主键和唯一的对比【面试题】
| 保证唯一性 | 是否允许为空 | 一个表中可以有多少个 | 是否允许组合 | |
|---|---|---|---|---|
| 主键 | √ | × | 至多有1个 | √,但不推荐 |
| 唯一 | √ | √ | 可以有多个 | √,但不推荐 |
-
外键
-
要求在从表设置外键关系
-
从表的外键列的类型和主表的关联列的类型要求一致或兼容,名称无要求
-
主表的关联列必须是一个key(一般是主键或唯一)
-
插入数据时,先插入主表,再插入从表;删除数据时,先删除从表,再删除主表
1
2
3
4
5# 可以通过以下两种方式来删除主表的记录
# 方式一:级联删除
ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE CASCADE;
# 方式二:级联置空
ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE SET NULL;
-
-
约束的增删改
1
|
|
-
自增长列(标识列)
-
含义:可以不用手动的插入值,系统提供默认的序列值
-
特点:
1、标识列必须和主键搭配吗?不一定,但要求是一个key
2、一个表可以有几个标识列?至多一个!
3、标识列的类型只能是数值型
4、标识列可以通过SET auto_increment_increment=3;设置步长
可以通过 手动插入值,设置起始值
-
1
|
|
4.5 表与表之间的关系
- 一对一
- 一对多
- 多对多
5. TCL语言
Transaction Control Language 事务控制语言
5.1 事务的含义
事务:
一个或一组sql语句组成一个执行单元,这个执行单元要么全部执行,要么全部不执行。
5.2 事务的特点
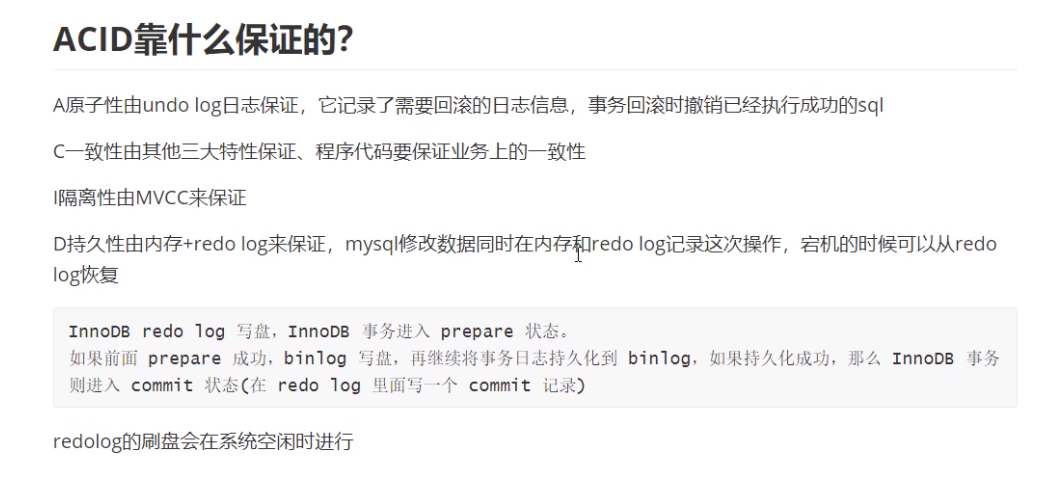
事务的特性:ACID [面试题]
- 原子性:一个事务不可再分割,要么都执行要么都不执行.
- 一致性:一个事务执行会使数据从一个一致状态切换到另外一个一致状态.
- 隔离性:一个事务的执行不受其他事务的干扰.
- 持久性:一个事务一旦提交,则会永久的改变数据库的数据.
存储引擎:
- 概念: 在mysql中的数据用各种不同的技术存储在文件(或者内存)中.
- 通过
show engines;来查看mysql支持的存储引擎.- 在mysql中用的最多的存储引擎有: innodb, myisam, memory等. 其中innodb支持事务,而myisam和memory不支持事务.
5.3 事务的使用
-
事务的创建
-
隐式事务:事务没有明显的开启和结束的标记
比如insert、update、delete语句 delete from 表 where id =1;
-
显式事务:事务具有明显的开启和结束的标记
前提:必须先设置自动提交功能为禁用set autocommit=0;
-
-
显式事务的使用
① 开启事务
set autocommit=0;
start transaction;#可以省略② 编写一组逻辑sql语句
注意:sql语句支持的是insert、update、delete设置回滚点:
savepoint 回滚点名;③ 结束事务
提交:commit;
回滚:rollback;
回滚到指定的地方:rollback to 回滚点名; -
delete和truncate在事务使用时的区别:
- delete支持回滚
- truncate不支持
5.4 并发事务
-
事务的并发问题是如何发生的?
多个事务 同时 操作 同一个数据库的相同数据时
-
并发问题都有哪些?
- 脏读:一个事务读取了其他事务还没有提交的数据,读到的是其他事务“更新”的数据
- 不可重复读:一个事务多次读取,结果不一样
- 幻读:一个事务读取了其他事务还没有提交的数据,只是读到的是其他事务“插入”的数据
- 更新丢失:当两个或者多个事务选择同一行,然后基于最初的选定的值更新该行时,由于每一个事务都不知道其他事务的存在,就会发生更新问题。最后的更新覆盖了其他事务所做的更新。
-
如何解决并发问题
通过设置隔离级别来解决并发问题
-
事务的隔离级别
| 读数据一致性 | 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|---|
| read uncommitted: 读未提交 | 最低级别,只能保证不读取物理上损坏的数据 | × | × | × |
| read committed: 读已提交 | 语句级 | √ | × | × |
| repeatable read: 可重复读 | 事务级 | √ | √ | × |
| serializable: 串行化 (每次读都需获得表级共享锁,读写相互都会阻塞,性能低下) | 最高级别,事务级 | √ | √ | √ |
1
|
|
1
|
|
6. 其他
6.1 视图
含义:虚拟表,和普通表一样使用
mysql5.1版本出现的新特性,是通过表动态生成的数据, 只保存了sql逻辑, 不保存查询结果
-
应用场景:
- 多个地方用到相同的查询结果
- 该查询结果使用的sql语句比较复杂
-
好处:
- 重用sql语句
- 简化复杂的sql操作,不必知道它的查询细节
- 保护数据,提高安全性(只提供对方需要的信息)
-
创建视图
1
|
|
- 修改视图
1
|
|
- 删除视图
1
|
|
- 查看视图
1
|
|
- 更新视图
视图可以增删改,示例如下
1
|
|
具备以下特点的视图不允许更新
1
|
|
- 表和视图的对比
创建语法的关键字 是否实际占用物理空间 使用 视图 create view 只是保存了sql逻辑 增删改查,只是一般不能增删改 表 create table 保存了数据 增删改查
6.2 变量
- 系统变量:
- 全局变量:
-
会话变量:
服务器为每一个连接的客户端都提供了系统变量,作用域为当前的连接(会话)
- 自定义变量:
- 用户变量
- 局部变量
- 系统变量
说明:变量由系统定义,不是用户定义,属于服务器层面
注意:全局变量需要添加global关键字,会话变量需要添加session关键字,如果不写,默认会话级别
使用步骤:
1
|
|
示例:
1
|
|
- 自定义变量
说明:变量由用户自定义,而不是系统提供的
使用步骤:
1、声明
2、赋值
3、使用(查看、比较、运算等)
示例:
1
|
|
用户变量和局部变量的对比:
| 作用域 | 定义位置 | 语法 | |
|---|---|---|---|
| 用户变量 | 当前会话 | 会话的任何地方 | 加@符号,不用指定类型 |
| 局部变量 | 定义它的BEGIN END中 | BEGIN END的第一句话 | 一般不用加@,需要指定类型 |
6.3 存储过程和函数
- 存储过程和函数:类似于java中的方法
- 好处:
1、提高代码的重用性
2、简化操作
- 存储过程
含义:一组预先编译好的SQL语句的集合,理解成批处理语句
1、提高代码的重用性
2、简化操作
3、减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率
示例:
1
|
|
- 函数
含义:一组预先编译好的SQL语句的集合,理解成批处理语句
1、提高代码的重用性
2、简化操作
3、减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率
区别:
存储过程:可以有0个返回,也可以有多个返回,适合做批量插入、批量更新
函数:有且仅有1 个返回,适合做处理数据后返回一个结果
示例:
1
|
|
6.4 流程控制结构
顺序、分支、循环
- 分支结构
1
|
|
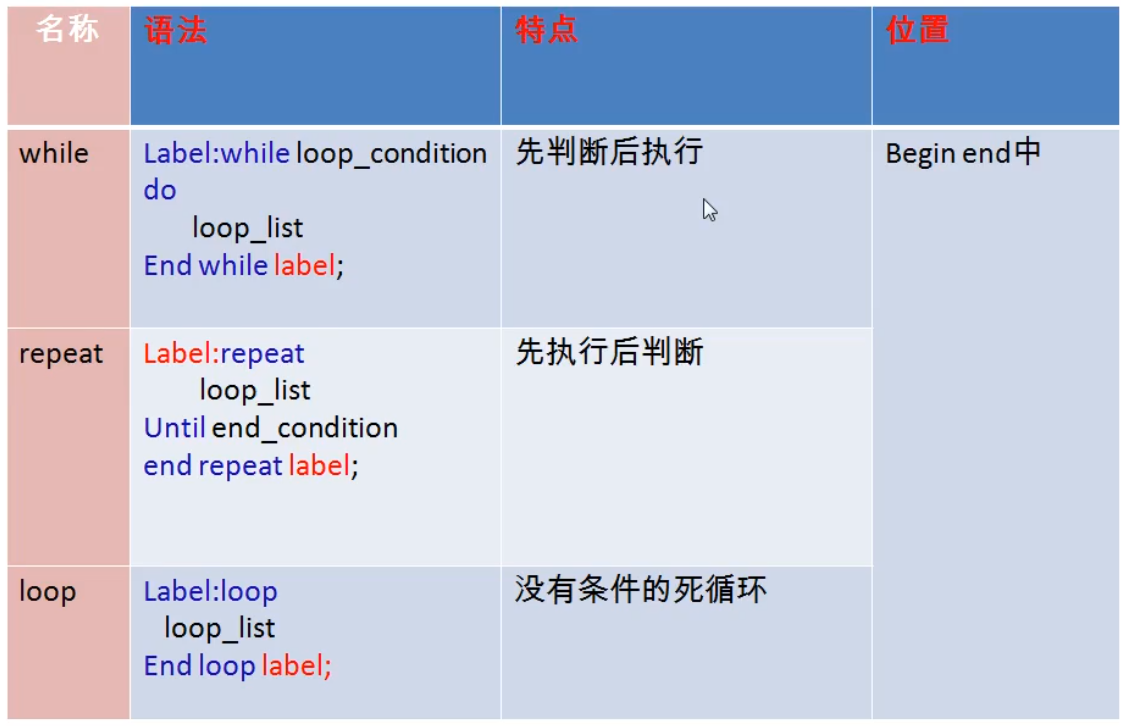
- 循环结构
分类:
while、loop、repeat
循环控制:
iterate 【标签】 类似于 continue,继续,结束本次循环,继续下一次
leave 【标签】 类似于 break,跳出,结束当前所在的循环
语法:
示例:
1
|
|