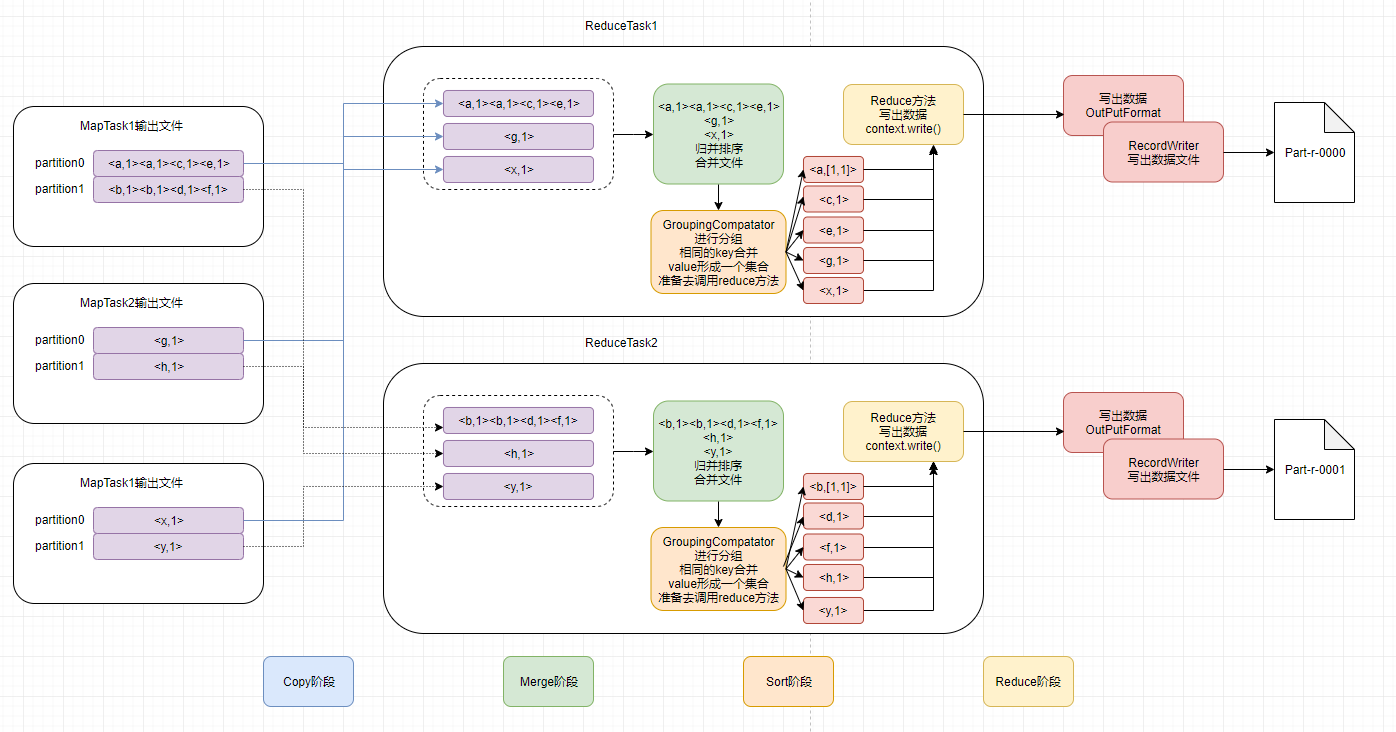
Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,如果其大小超过一定的阈值,则写道磁盘上,否则直接放到内存中;
Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多;
Sort阶段:与Merge阶段同时进行,用户编写reduce函数输入数据是按key进行聚集的一组数据,为了将相同key聚集在一起,hadoop采用了基于排序策略。由于MapTask对自己的结果已经进行了局部排序,因此ReduceTask只需要对所有数据进行一次归并排序即可;
Reduce阶段:reduce函数将计算结果写到hdfs上;