生成类标数据:
import pandas as pd # 生成类别数据 df = pd.DataFrame([ ["green", "M", 10.1, "class1"], ["red", "L", 13.5, "class2"], ["blue", "XL", 15.3, "class1"] ]) df.columns = ["color", "size", "price", "classlabel"] print(df)
运行结果:
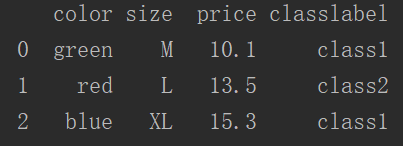
有序特征的映射:
1 size_mapping = { 2 "XL": 3, 3 "L": 2, 4 "M": 1, 5 } 6 df["size"] = df["size"].map(size_mapping) 7 print(df)
运行结果:

可以通过size_mapping映射回去
1 # 通过size_mapping映射回去 2 inv_size_mapping = {v: k for k, v in size_mapping.items()} 3 df["size"] = df["size"].map(inv_size_mapping) 4 print(df)
运行结果:

类标的编码:
可以简单地从0开始设置类标
1 import numpy as np 2 class_mapping = {label: idx for idx, label in enumerate(np.unique(df["classlabel"]))} 3 print(class_mapping) 4 df["classlabel"] = df["classlabel"].map(class_mapping) 5 print(df)
运行结果:
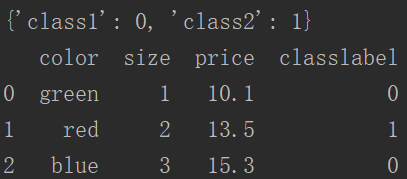
同样我们可以使用键值对倒置还原类标
1 inv_class_mapping = {v: k for k, v in class_mapping.items()} 2 df["classlabel"] = df["classlabel"].map(inv_class_mapping) 3 print(df)

使用scikit-learn中的LabelEncoder类完成类标的编码
1 from sklearn.preprocessing import LabelEncoder 2 class_le = LabelEncoder() 3 df["classlabel"] = class_le.fit_transform(df["classlabel"].values) 4 print(df) 5 # 可以使用inverse_transfrom()还原类标 6 df["classlabel"] = class_le.inverse_transform(df["classlabel"]) 7 print(df)
遇到警告可以使用下面的代码忽略警告:
1 import warnings 2 warnings.filterwarnings('ignore')
运行结果:

标称特征上的独热编码
1 from sklearn.preprocessing import OneHotEncoder 2 x = df[["color", "size", "price"]].values 3 color_le = LabelEncoder() 4 x[:, 0] = class_le.fit_transform(x[:, 0]) 5 # categorical_features来选定矩阵的列;toarray方法将其转化为一个numpy数组 6 ohe = OneHotEncoder(categorical_features=[0]) 7 x = ohe.fit_transform(x).toarray() 8 print(x)
运行结果:

我们可以使用get_dummies更加方便地实现独热编码
1 print(df) 2 print(pd.get_dummies(df))
运行结果:
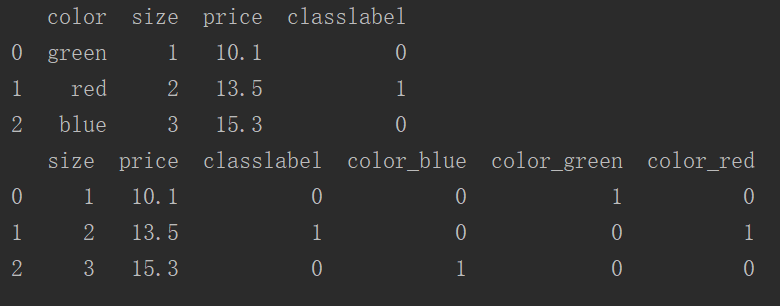
这里要注意如果类标classlael也是和标称特征一样,则 get_dummies 会使类标也进行独热编码,而这不是我们希望做的!!!