机器学习相关概念理解
利用机器学习处理一个实际的问题就不仅仅是我们得学会怎么使用机器学习算法,更重要的是如何对整个问题建模。
机器学习主要是由三部分组成,即:表示(模型)、评价(策略)和优化(算法)。
模型
具体对于一个分类问题而言,我们希望能够找到一个映射,这样的映射是将输入空间投影到输出空间中。而这样的映射的集合我们便把它称为假设空间(hypothesisspace)。我们其实是在这样的假设空间中寻找满足具体问题的一个映射。对于分类问题而言,映射主要分为:
概率模型:主要是条件概率()
非概率模型:主要是决策函数()
泛化能力
模型对未知数据的预测能力便称为泛化能力(Generalization ability),这是机器学习成功与否的一个很重要的评价指标。同时,预测误差便成为评价学习方法的泛化能力的指标。
机器学习算法中有很多的参数,算法成功往往源自对这些参数的精细调节。尽管我们能够获得的数据越来越多,但是始终我们不能把所有数据都得到,要像调节好这些参数,我们就必须充分利用训练数据。
cross-validation
交叉验证是充分利用数据最好的方式,其中交叉验证的基本想法就是要重复地使用数据。交叉验证的基本思想是:将数据集划分成训练数据和验证数据,在训练数据上训练整个模型,利用验证数据模拟实际的数据,对整个模型进行调整,最终我们选择在验证数据上表现最好的模型。常用的交叉验证的方法有:
简单交叉验证:与上面类似,简单的划分
S折交叉验证:将数据随机划分成S份,其中的S-1份作为训练,剩下的1份作为验证,重复进行,最终选择平均验证误差最小的模型
留一交叉验证:S折交叉验证的特殊情况()
过拟合问题(Over-fitting)
1.过拟合的含义
过拟合是指学习时选择的模型包含的参数过多,以至于出现这一模型对已知数据预测很好,但是对未知数据预测得很差的现象。
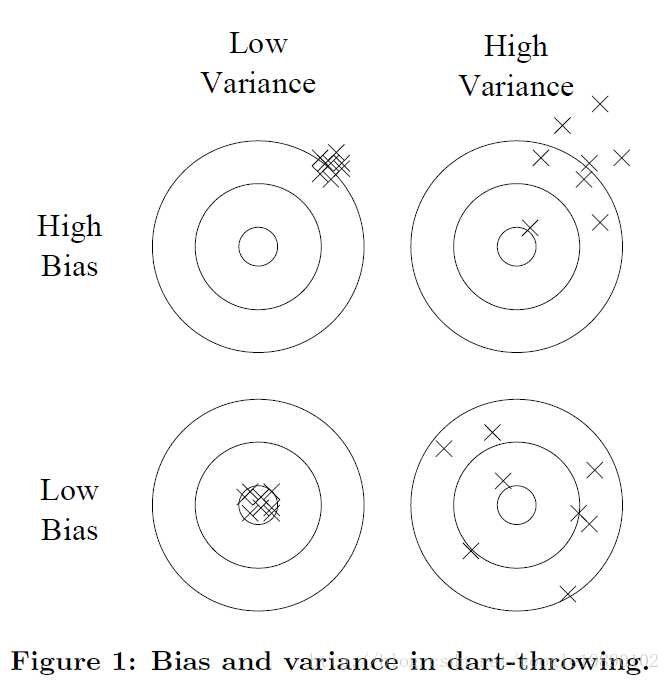
2、对过拟合的理解
一种理解过拟合的方式是将泛化误差分解成偏置(bias)和方差(variance):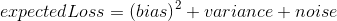
其中,noise为常数。偏置度量了学习器倾向于一直学习相同错误的程度;方差则度量了学习器倾向于忽略真实信号,学习随机事物的程序。其实,在我的理解中,这里很像演化计算中的那些启发式算法的更新公式,如何协调好这两个因素是算法成功的关键。
3、避免过拟合的方法
避免过拟合的方法主要有两种:
交叉验证(cross-validation)
给评价函数加上正则项
以上的两种方法在数据量比较小的时候还是比较有优势的,其中交叉验证有的时候也不能彻底解决问题,因为加入我们利用交叉验证做了太多的参数选择,那么本身这样的过程就开始有过拟合的可能。加上正则项的目的是惩罚那些包含更多结构的分类器,去选择较少结构的分类器,起到降低过拟合的可能。
开始在算法上花很大的功夫,研究各种变种,力图使一个算法变得更通用,但是结果却发现,将算法进行融合,会表现的更好,而且只需花费很少的精力。
1、三种集成模式
Bagging(最简单的一种)
Boosting
Stacking
第一种(Bagging)采用的方法是:通过重采样随机产生若干个不同的子训练集,然后在每个集合上训练一个分类器,最终用投票的方式将结果合并。
第二种(Boosting)采用的方法是:每个训练样例都有一个权重,并且权重会不断变化,每次训练新分类器的时候都集中在那些分类器之前倾向于分错的样例上。
第三种(Stacking)采用的方法是:每个单独的分类器的输出作为更高层分类器的输入,更高层分类器可以判断如何更好地合并这些来自低层的输出。
2、Bagging和Boosting方法的比较
Bagging采用重复取样,每个个体分类器所采用的训练样本都是从训练集中按等概率抽取的,因此Bagging的各子训练集能够很好的覆盖训练样本空间,从而有着良好的稳定性。
Boosting注重分类错误的样本,将个体子训练集分类错误的训练样本的权重提高,降低分类正确的样本权重,并依据修改后的样本权重来生成新的训练样本空间并用来训练下一个个体分类器。然而,由于Boosting算法可能会将噪声样本或分类边界样本的权重过分累积,因此Boosting很不稳定,但其在通常情况下,其泛化能力是比较理想的集成算法之一。
关于分类器的选择:
没有最好的分类器,只有最合适的分类器。
随机森林平均来说最强,但也只在9.9%的数据集上拿到了第一,优点是鲜有短板。
SVM的平均水平紧随其后,在10.7%的数据集上拿到第一。
神经网络(13.2%)和boosting(~9%)表现不错。
数据维度越高,随机森林就比AdaBoost强越多,但是整体不及SVM[2]。
数据量越大,神经网络就越强。
随机森林
提到决策树就不得不提随机森林。顾名思义,森林就是很多树。
严格来说,随机森林其实算是一种集成算法。它首先随机选取不同的特征(feature)和训练样本(training sample),生成大量的决策树,然后综合这些决策树的结果来进行最终的分类。
随机森林在现实分析中被大量使用,它相对于决策树,在准确性上有了很大的提升,同时一定程度上改善了决策树容易被攻击的特点。
适用情景:
数据维度相对低(几十维),同时对准确性有较高要求时。
因为不需要很多参数调整就可以达到不错的效果,基本上不知道用什么方法的时候都可以先试一下随机森林。
回归方法的核心就是为函数找到最合适的参数,使得函数的值和样本的值最接近。例如线性回归(Linear regression)就是对于函数f(x)=ax+b,找到最合适的a,b。
LR拟合的就不是线性函数了,它拟合的是一个概率学中的函数,f(x)的值这时候就反映了样本属于这个类的概率。
适用情景:
LR同样是很多分类算法的基础组件,它的好处是输出值自然地落在0到1之间,并且有概率意义。
因为它本质上是一个线性的分类器,所以处理不好特征之间相关的情况。
虽然效果一般,却胜在模型清晰,背后的概率学经得住推敲。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。也是一个理解数据的好工具。
LDA的核心思想是把高维的样本投射(project)到低维上,如果要分成两类,就投射到一维。要分三类就投射到二维平面上。这样的投射当然有很多种不同的方式,LDA投射的标准就是让同类的样本尽量靠近,而不同类的尽量分开。对于未来要预测的样本,用同样的方式投射之后就可以轻易地分辨类别了。
使用情景:
判别分析适用于高维数据需要降维的情况,自带降维功能使得我们能方便地观察样本分布。它的正确性有数学公式可以证明,所以同样是很经得住推敲的方式。
但是它的分类准确率往往不是很高,所以不是统计系的人就把它作为降维工具用吧。
同时注意它是假定样本成正态分布的,所以那种同心圆形的数据就不要尝试了。
神经网络 (Neural network)
神经网络现在是火得不行啊。它的核心思路是利用训练样本(training sample)来逐渐地完善参数。还是举个例子预测身高的例子,如果输入的特征中有一个是性别(1:男;0:女),而输出的特征是身高(1:高;0:矮)。那么当训练样本是一个个子高的男生的时候,在神经网络中,从“男”到“高”的路线就会被强化。同理,如果来了一个个子高的女生,那从“女”到“高”的路线就会被强化。
最终神经网络的哪些路线比较强,就由我们的样本所决定。
神经网络的优势在于,它可以有很多很多层。如果输入输出是直接连接的,那它和LR就没有什么区别。但是通过大量中间层的引入,它就能够捕捉很多输入特征之间的关系。卷积神经网络有很经典的不同层的可视化展示(visulization),我这里就不赘述了。
神经网络的提出其实很早了,但是它的准确率依赖于庞大的训练集,原本受限于计算机的速度,分类效果一直不如随机森林和SVM这种经典算法。
使用情景:
数据量庞大,参数之间存在内在联系的时候。
当然现在神经网络不只是一个分类器,它还可以用来生成数据,用来做降维,这些就不在这里讨论了。
接下来的一系列模型,都属于集成学习算法(Ensemble Learning),基于一个核心理念:当我们把多个较弱的分类器结合起来的时候,结果会比一个强的分类器更
提升算法(Boosting)
典型的例子是AdaBoost。
AdaBoost的实现是一个渐进的过程,从一个最基础的分类器开始,每次寻找一个最能解决当前错误样本的分类器。用加权取和(weighted sum)的方式把这个新分类器结合进已有的分类器中。
它的好处是自带了特征选择(feature selection),只使用在训练集中发现有效的特征(feature)。这样就降低了分类时需要计算的特征数量,也在一定程度上解决了高维数据难以理解的问题。
最经典的AdaBoost实现中,它的每一个弱分类器其实就是一个决策树。这就是之前为什么说决策树是各种算法的基石。
使用情景:
好的Boosting算法,它的准确性不逊于随机森林。因为自带特征选择(feature selection)所以对新手很友好,是一个“不知道用什么就试一下它吧”的算法。
装袋算法(Bagging)
同样是弱分类器组合的思路,相对于Boosting,其实Bagging更好理解。它首先随机地抽取训练集(training set),以之为基础训练多个弱分类器。然后通过取平均,或者投票(voting)的方式决定最终的分类结果。
因为它随机选取训练集的特点,Bagging可以一定程度上避免过渡拟合(overfit)。
最强的Bagging算法是基于SVM的。如果用定义不那么严格的话,随机森林也算是Bagging的一种。
使用情景:
相较于经典的必使算法,Bagging使用的人更少一些。一部分的原因是Bagging的效果和参数的选择关系比较大,用默认参数往往没有很好的效果。
虽然调对参数结果会比决策树和LR好,但是模型也变得复杂了,没有特别的原因就别用它了。
Stacking
这个我是真不知道中文怎么说了。它所做的是在多个分类器的结果上,再套一个新的分类器。
这个新的分类器就基于弱分类器的分析结果,加上训练标签(training label)进行训练。一般这最后一层用的是LR。
Stacking在实战里面的表现不好,可能是因为增加的一层分类器引入了更多的参数,也可能是因为有过渡拟合(overfit)的现象。
最大熵模型 (Maximum entropy model)
最大熵模型本身不是分类器,它一般是用来判断模型预测结果的好坏的。
对于它来说,分类器预测是相当于是:针对样本,给每个类一个出现概率。比如说样本的特征是:性别男。我的分类器可能就给出了下面这样一个概率:高(60%),矮(40%)。
而如果这个样本真的是高的,那我们就得了一个分数60%。最大熵模型的目标就是让这些分数的乘积尽量大。
LR其实就是使用最大熵模型作为优化目标的一个算法。
EM
就像最大熵模型一样,EM不是分类器,而是一个思路。很多算法都是基于这个思路实现的。
隐马尔科夫 (Hidden Markov model)
这是一个基于序列的预测方法,核心思想就是通过上一个(或几个)状态预测下一个状态。
之所以叫“隐”马尔科夫是因为它的设定是状态本身我们是看不到的,我们只能根据状态生成的结果序列来学习可能的状态。
适用场景:
可以用于序列的预测,可以用来生成序列。
条件随机场 (Conditional random field)
典型的例子是linear-chain CRF。