集群配置
1. 集群部署规划
表2-3
|
|
hadoop002 |
hadoop003 |
hadoop004 |
|
HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
2. 配置集群
(1)核心配置文件
配置core-site.xml
[root@hadoop002 hadoop]# vim core-site.xml [root@hadoop002 hadooop]#
<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop002:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> </configuration>
(2)HDFS配置文件
配置hdfs-site.xml
[root@hadoop002 hadoop]# vim hdfs-site.xml [root@hadoop002 hadoop]#
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop004:50090</value> </property> </configuration>
(3)YARN配置文件
配置yarn-site.xml
[root@hadoop002 hadoop]# vim yarn-site.xml
[root@hadoop002 hadoop]#
在该文件中增加如下配置
<configuration> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop003</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
(4)MapReduce配置文件
配置mapred-site.xml
[root@hadoop102 hadoop]$ cp mapred-site.xml.template mapred-site.xml
<configuration> <!-- 指定MR运行在YARN上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop001:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop001:19888</value> </property> </configuration>
3.在集群上分发配置好的Hadoop配置文件
[root@hadoop102 hadoop]$ xsync /opt/module/hadoop-2.7.2/
4.查看文件分发情况
[root@hadoop103 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
4.3.4 集群单点启动
(1)如果集群是第一次启动,需要格式化NameNode
[root@hadoop102 hadoop-2.7.2]$ hadoop namenode -format
(2)在hadoop102上启动NameNode
sbin/hadoop-daemon.sh start datanode
[root@hadoop102 hadoop-2.7.2]$ jps
3461 NameNode
(3)在hadoop002、hadoop003以及hadoop004上分别启动DataNode
[root@hadoop002 hadoop-2.7.2]$ hadoop-daemon.sh start datanode [root@hadoop002 hadoop-2.7.2]$ jps 3461 NameNode 3608 Jps 3561 DataNode [root@hadoop003 hadoop-2.7.2]$ hadoop-daemon.sh start datanode [root@hadoop003 hadoop-2.7.2]$ jps 3190 DataNode 3279 Jps [root@hadoop004 hadoop-2.7.2]$ hadoop-daemon.sh start datanode [root@hadoop004 hadoop-2.7.2]$ jps 3237 Jps 3163 DataNode
其中要群起集群的话,可以看这边博客,要设置一下SSH:https://www.cnblogs.com/dalianpai/p/12194726.html
群起集群
1. 配置slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[root@hadoop002 hadoop]# cat slaves hadoop002 hadoop003 hadoop004 [root@hadoop002 hadoop]#
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[root@hadoop002 hadoop]# xsync slaves fname=slaves pdir=/opt/module/hadoop-2.7.2/etc/hadoop ------------------- hadoop3 -------------- sending incremental file list slaves sent 119 bytes received 41 bytes 106.67 bytes/sec total size is 30 speedup is 0.19 ------------------- hadoop4 -------------- sending incremental file list slaves sent 119 bytes received 41 bytes 320.00 bytes/sec total size is 30 speedup is 0.19 [root@hadoop002 hadoop]# jps 24551 NameNode 24475 DataNode 25868 Jps
2. 启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@hadoop002 hadoop]# cd ../../ [root@hadoop002 hadoop-2.7.2]# sbin/hadoop-daemon.sh stop datanode stopping datanode [root@hadoop002 hadoop-2.7.2]# sbin/hadoop-daemon.sh stop namenode stopping namenode
[root@hadoop003 hadoop-2.7.2]# sbin/hadoop-daemon.sh stop datanode stopping datanode [root@hadoop003 hadoop-2.7.2]# jps 26702 Jps
[root@hadoop004 hadoop-2.7.2]# sbin/hadoop-daemon.sh stop datanode stopping datanode [root@hadoop004 hadoop-2.7.2]# jps 20994 Jps
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)启动HDFS
root@hadoop002 hadoop-2.7.2]# sbin/start-dfs.sh Starting namenodes on [hadoop002] hadoop002: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop002.out hadoop002: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop002.out hadoop003: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop003.out hadoop004: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop004.out Starting secondary namenodes [hadoop004] hadoop004: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-hadoop004.out [root@hadoop002 hadoop-2.7.2]# jps 26023 NameNode 26152 DataNode 26361 Jps
[root@hadoop004 hadoop-2.7.2]# jps 21122 SecondaryNameNode 21029 DataNode 21163 Jps
(3)启动YARN
[root@hadoop003 hadoop-2.7.2]# sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-resourcemanager-hadoop003.out hadoop004: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop004.out hadoop002: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop002.out hadoop003: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop003.out [root@hadoop003 hadoop-2.7.2]# jps 26963 NodeManager 26739 DataNode 27256 Jps 26862 ResourceManager
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
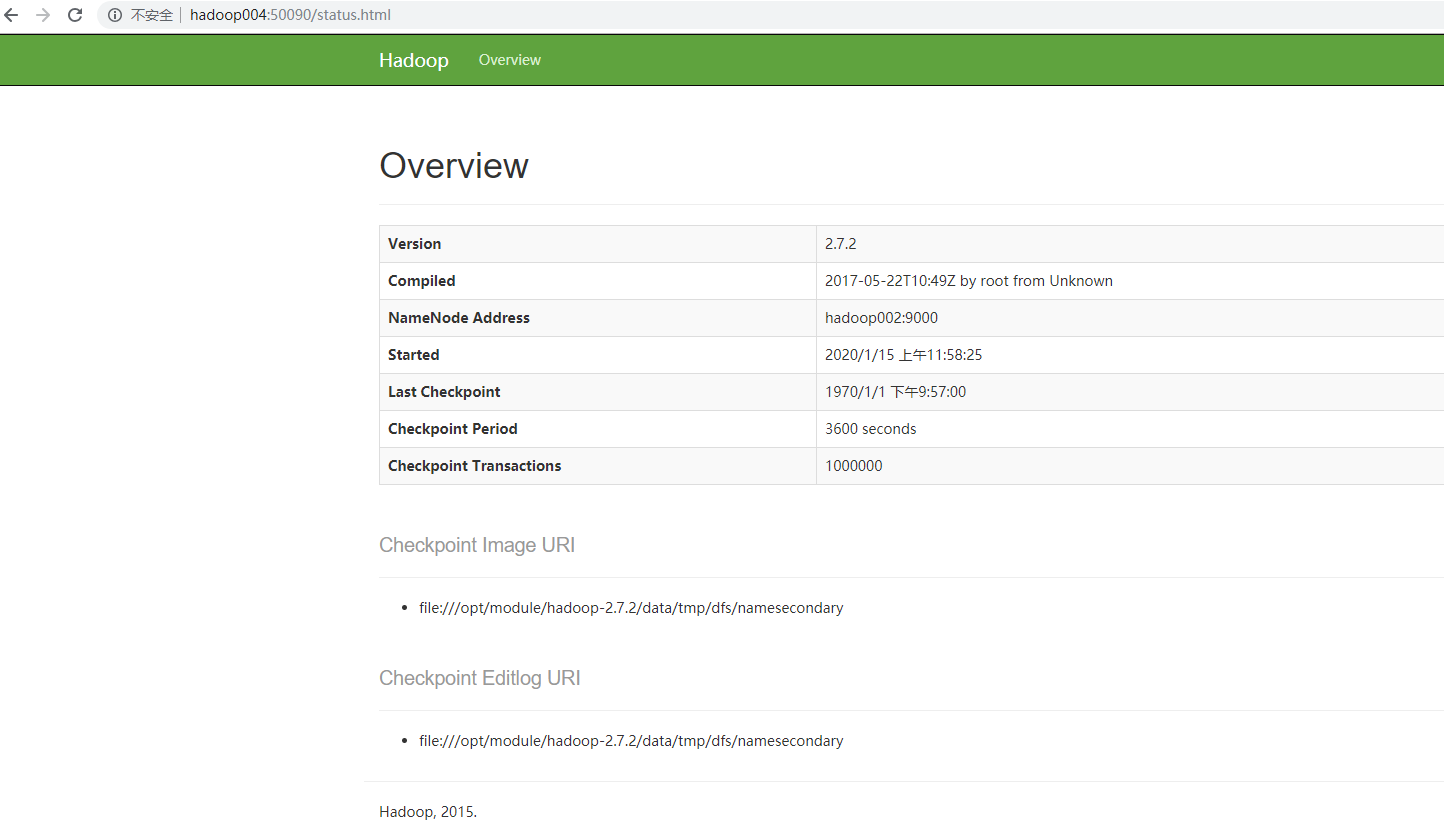
(4)Web端查看SecondaryNameNode
(a)浏览器中输入:http://hadoop004:50090/status.html
(b)查看SecondaryNameNode信息,如图
集群基本测试
(1)上传文件到集群
上传小文件
[root@hadoop002 hadoop-2.7.2]# bin/hdfs dfs -put wcinput/wc.input / [root@hadoop002 hadoop-2.7.2]# ll
上传大文件
[root@hadoop002 hadoop-2.7.2]# bin/hdfs dfs -put /opt/module/jdk1.8.0_144/lib/tools.jar / 20/01/15 12:11:08 WARN hdfs.DFSClient: Slow waitForAckedSeqno took 39284ms (threshold=30000ms)
(2)上传文件后查看文件存放在什么位置
[root@hadoop002 hadoop-2.7.2]# cd data/tmp/dfs/data/current/BP-1442086029-172.16.25.74-1579016149783/current/ [root@hadoop002 current]# ll total 16 -rw-r--r-- 1 root root 19 Jan 15 11:55 dfsUsed drwxr-xr-x 3 root root 4096 Jan 15 12:05 finalized drwxr-xr-x 2 root root 4096 Jan 15 12:11 rbw -rw-r--r-- 1 root root 132 Jan 15 11:58 VERSION [root@hadoop002 current]# cd finalized/subdir0/ [root@hadoop002 subdir0]# ll total 4 drwxr-xr-x 2 root root 4096 Jan 15 12:11 subdir0 [root@hadoop002 subdir0]# cd subdir0/ [root@hadoop002 subdir0]# ll total 18008 -rw-r--r-- 1 root root 48 Jan 15 12:05 blk_1073741825 -rw-r--r-- 1 root root 11 Jan 15 12:05 blk_1073741825_1001.meta -rw-r--r-- 1 root root 18284613 Jan 15 12:11 blk_1073741826 -rw-r--r-- 1 root root 142859 Jan 15 12:11 blk_1073741826_1002.meta
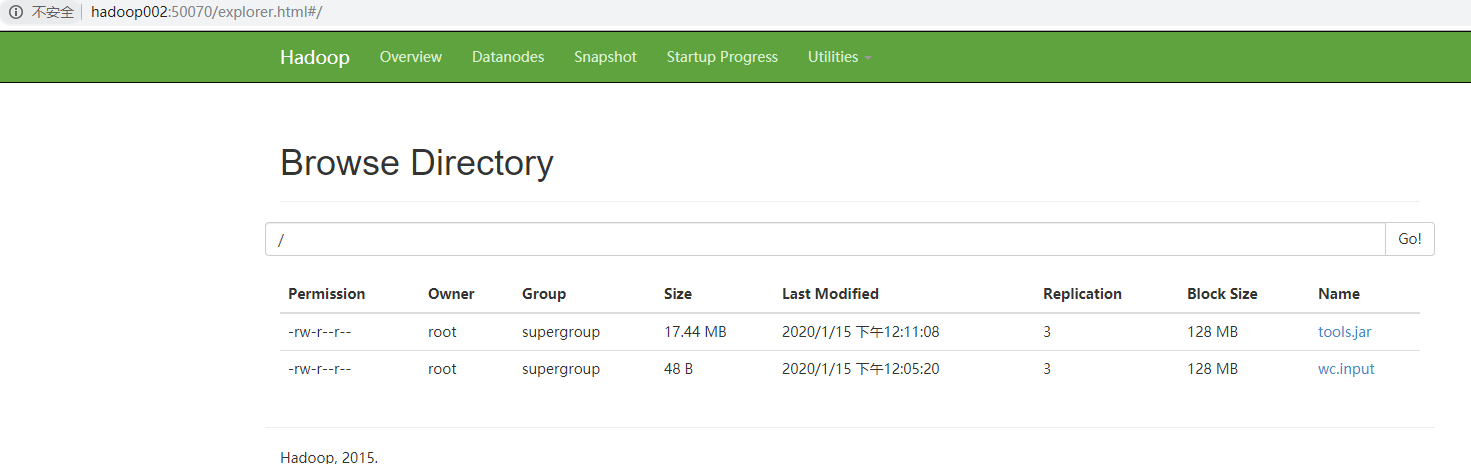
假如文件大于128M,存储的时候会进行切分。
4.3.7 集群启动/停止方式总结
1. 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2. 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh