本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. 各种Connector
1.1Connector是什么鬼
Connectors是数据进出Flink的一套接口和实现,可以实现Flink与各种存储、系统的连接
注意:数据进出Flink的方式不止Connectors,还有:
1.Async I/O(类Source能力):异步访问外部数据库
2.Queryable State(类Sink能力):当读多写少时,外部应用程序从Flink拉取需要的数据,而不是Flink把大量数据推入外部系统(后面再讲)
1.2哪些渠道获取connector
预定义Source和Sink:直接就用,无序引入额外依赖,一般用于测试、调试。
捆绑的Connectors:需要专门引入对应的依赖(按需),主要是实现外部数据进出Flink
1.Apache Kafka (source/sink)
2.Apache Cassandra (sink)
3.Amazon Kinesis Streams (source/sink)
4.Elasticsearch (sink)
5.Hadoop FileSystem (sink)
6.RabbitMQ (source/sink)
7.Apache NiFi (source/sink)
8.Twitter Streaming API (source)
Apache Bahir
1.Apache ActiveMQ (source/sink)
2.Apache Flume (sink)
3.Redis (sink)
4.Akka (sink)
5.Netty (source)
1.3预定义Source
预定义Source包含以下几类:
1.基于文件
readTextFile
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviro nment();
DataStream<String> lines = env.readTextFile("file:///path");
readFile
DataStream<String> lines = env.readFile(inputFormat, "file:///path");
2.基于Socket
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviro nment();
DataStream<String> socketLines = env .socketTextStream("localhost", 9998);
3.基于Elements 和Collections
fromElements
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviro nment();
DataStream<String> names = env.fromElements("hello", "world", "!");
fromCollections
List<String> list = new ArrayList<String>(); list.add("Hello"); list.add("world");
list.add("!");
DataStream<String> names = env.fromCollection(list);
使用场景: 应用本地测试,但是流处理应用会出现Finished的状态
1.4预定义Sink
stream.print() /printToErr()(注: 线上应用杜绝使用,采用抽样打印或者日志的方式)
stream.writeAsText("/path/to/file")/ TextOutputFormat
stream.writeAsCsv(“/path/to/file”)/ CsvOutputFormat
writeUsingOutputFormat() / FileOutputFormat
stream.writeToSocket(host, port, SerializationSchema)
1.5队列系统Connector(捆绑)
支持Source 和 Sink
需要专门引入对应的依赖(按需),主要是实现外部数据进出Flink
1.Kafka(后续专门讲)
2.RabbitMQ
1.6存储系统Connector(捆绑)
只支持Sink
1.HDFS
2.ElasticSearch
3.Redis
4.Apache Cassandra
1.7 Source容错性保证

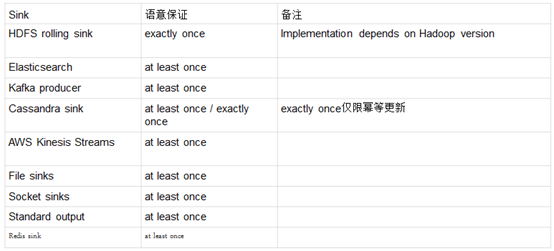
1.8 Sink容错性保证
2. 自定义Source与Sink
2.1自定义Source
1.实现SourceFunction(非并行,并行度为1)
1)适用配置流,通过广播与时间流做交互
2)继承SourceFuncion, 实现run 方法
3)cancel 方法需要处理好(cancel 应用的时候,这个方法会被调用)
4)基本不需要做容错性保证
2.实现ParallelSourceFunction
1)实现ParallelSourceFunction类或者继承RichParallelSourceFunction。
2)实现切分数据的逻辑
3)实现CheckpointedFunction接口,来保证容错保证。
4)Source 拥有回溯读取,可以减少的状态的保存。
3.继承RichParallelSourceFunction
2.2自定义Sink
1)实现SinkFunction 接口或者继承RichSinkFunction。
2)实现CheckpointedFunction, 做容错性保证。
