环境要求:
Linux
JDK 1.8
Python 3.6.5
一、下载压缩包
方法一:下载页面地址:https://github.com/alibaba/DataX
不要在【Clone or download】处下载,那里下载的是源码;对于Java不是很在行的人来说,自行编译显得有点困难。
而是在:【Quick Start】--->【Download DataX下载地址】进行下载。下载后的包名:datax.tar.gz 解压后{datax}目录下有{bin conf job lib log log_perf plugin script tmp}几个目录。
方法二:使用命令:wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
二、安装
1、首先:解压datax.tar.gz到相应的安装目录: $ sudo tar -zxf ~/下载/datax.tar.gz -C /usr/local
2、修改文件权限:$ sudo chmod -R 755 /usr/local/datax
3、由于我的python版本是3以上,官方datax只能使用python2.7版本,是因为语法问题,需要下载相应的文件:https://github.com/365taole/DataX_Python3
解压放置在datax/bin目录,环境切换到py3即可启动,亲测可用
4、进入bin目录 $ cd /usr/local/datax/bin
三、同步作业测试
例一、 hadoop@hadoop-master:/usr/local/datax/bin$ python3 datax.py /usr/local/datax/job/job.json
1 结果:
2 2020-02-29 12:29:32.717 [job-0] INFO JobContainer -
3 任务启动时刻 : 2020-02-29 12:29:22
4 任务结束时刻 : 2020-02-29 12:29:32
5 任务总计耗时 : 10s
6 任务平均流量 : 253.91KB/s
7 记录写入速度 : 10000rec/s
8 读出记录总数 : 100000
9 读写失败总数 :
例二、mysql数据同步到hive中(hive是hadoop内的一个数据仓库,进入hive之前,要先打开hadoop)
1 hadoop@hadoop-master:/usr/local/hive$ cd /usr/local/hadoop
2 hadoop@hadoop-master:/usr/local/hadoop$ sbin/start-dfs.sh
3 *****
4 hadoop@hadoop-master:/usr/local/hadoop$ cd /usr/local/hive/bin
5 hadoop@hadoop-master:/usr/local/hive/bin$ ./hive
1.进入mysql--建表--插入数据
进入mysql:mysql -u root -p
查看数据库:show databases;
新建数据库:create database db_name;
进入数据库:use dn_name;
新建表:create table dim_area( id int(20) not null auto_increment primary key, name varchar(32) not null, parent_id int(20) );
插入数据:nsert into dim_area(id,name,parent_id) values (110000,'beijing',null);
查看表数据:select * from dim_area;
查看表结构:desc dim_area;
查看数据库端口:show global variables like 'port';
2.进入hive并建表
查看数据库:show databases;
新建数据库:create database db_name;
进入数据库:use dn_name;
创建表:create table dim_area(id int,name string,parent_id int) row format delimited fields terminated by '/t';
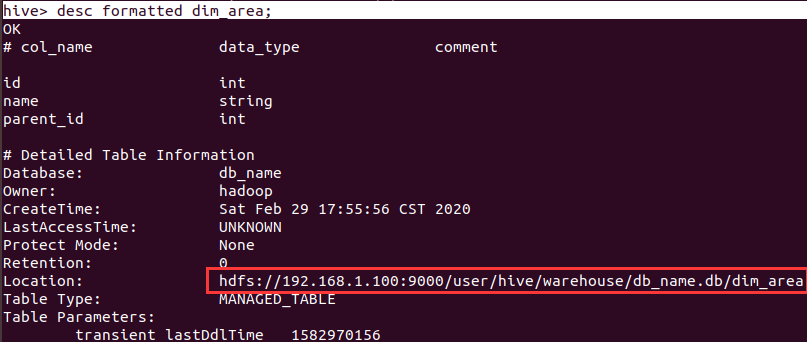
查看数据库基本信息:desc formatted dim_area;
3.编辑.json文件
大多数情况下,mysql的本地ip均为127.0.0.1,端口号为3306
查找hive表的路径:命令:desc formatted dim_area;
1 { 2 "content":[ 3 { 4 "reader":{ 5 "name":"mysqlreader", 6 "parameter":{ 7 "connection":[ 8 { 9 "jdbcUrl":[ 10 "jdbc:mysql://127.0.0.1:3306/db_name" 11 ], 12 "querySql":[ 13 "SELECT id, name, parent_id FROM dim_area;" 14 ] 15 } 16 ], 17 "password":"*******", 18 "username":"root" 19 } 20 }, 21 "writer":{ 22 "name":"hdfswriter", 23 "parameter":{ 24 "column":[ 25 { 26 "name":"id", 27 "type":"int" 28 }, 29 { 30 "name":"name", 31 "type":"string" 32 }, 33 { 34 "name":"parent_id", 35 "type":"int" 36 } 37 ], 38 "compress":"", 39 "defaultFS":"hdfs://192.168.1.100:9000/", 40 "fieldDelimiter":" ", 41 "fileName":"tmp", 42 "fileType":"text", 43 "path":"/user/hive/warehouse/db_name.db/dim_area", 44 "writeMode":"append" 45 } 46 } 47 } 48 ], 49 "setting":{ 50 "speed":{ 51 "channel":10 52 } 53 } 54 }
例二结果同例一