上一篇中,主要说的就是词袋模型。回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示。首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的向量。这样每个文本在分词之后,就可以根据我们之前得到的词袋,构造成一个向量,词袋中有多少个词,那这个向量就是多少维度的了。然后就把这些向量交给计算机去计算,而不再需要文本啦。而向量中的数字表示的是每个词所代表的权重。代表这个词对文本类型的影响程度。
在这个过程中我们需要解决两个问题:1.如何计算出适当的权重。2.如何把词袋给缩小,后面会说到的其实就是降维的思想
先来解决第一个问题:如何计算权重?
上篇说过,使用词频来计算权重是个没什么人去用的方法。而我们大都会使用地球人都知道的算法:TF/IDF
TF/IDF 用来评估一个词在训练集中对某个文本的重要程度。其中TF表示的是某个词在文本中出现的频率也就是词频啦,用公式表示就是:
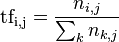
那IDF是什么呢?IDF叫做逆向文件频率: 计算公式是:
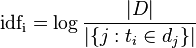
|D| 表示训练集的总文档数|{j:t¡Εdj}|表示包含词ti的所有文档
一般由于|{j:t¡Εdj}|可能会为0,所以分母+1,这么表示:

意思就是文档总数除以包含该词的文档数再取对数。具体意思是啥呢,就是说如果包含某个词的文档很少很少,那么这个词就非常具有区分度。这个道理很好理解,大多数文章都会包含"的" ,而大部分关于搜索引擎的文章才会包含"索引",那么"索引"这个词就比"的"更具有区分度。
而TF/IDF的方法是将TF/IDF结合起来也就是TF*IDF 的值越大,代表这个词的权重就越大,这个词对于文档来说就越重要。所以一个词在某个文档中的出现次数越大,而在别的文档中出现的次数又很少,这个时候就会得出一个很高的权重了。
而在搜索引擎中对文档的排序也有用到TF/IDF方法。
这样的话我们就可以得到一个TF/IDF权重的表示的向量。但是词袋(字典)向量的维度是在太高了,有几万维,很浪费计算机的资源。 高纬度的特征向量中每一维都可以看做是特征(特征也可以用词来表示,其实就是组成文章的一个一个词)。接下来就要介绍特征提取这个概念。我们从高维度特征向量中选取最具代表性的一些特征,从而达到把维度降低的同时也可以很好预测文章的类型。所以特征提取就可以叫做降维。一个维度不高,又能很好预测文章的词袋我们何乐而不为呢?
那么特征提取总体上来说有两类方法:
第一类可以称作特征抽取,它的思想是通过特征之间的关系,组合不同的特征得到新的特征,这样就改变了原始的特征空间,构成了新的特征。而新的特征更具有代表性,并消耗更少的计算机资源。主要方法有:
1.主成成分分析(PCA)
2.奇异值分解
3.Sammon映射
第二类叫做特征选择,它的思想是在原有的特征集合中选出一个更具代表性的子集,主要方法有三类:
1. 卡方检验,信息增益 通过给每一维的特征进行打分,然后进行排序,选择那些排名靠前的特征
2. 递归特征消除算法 将子集的选择看做是一个搜索优化的问题,通过启发式的搜索优化算法来解决
3. 岭回归 确定模型的过程中,挑选出那些对模型的训练有重要意义的属性
后面会对卡方检验和信息增益以及主成成分进行学习和讨论。再见咯。