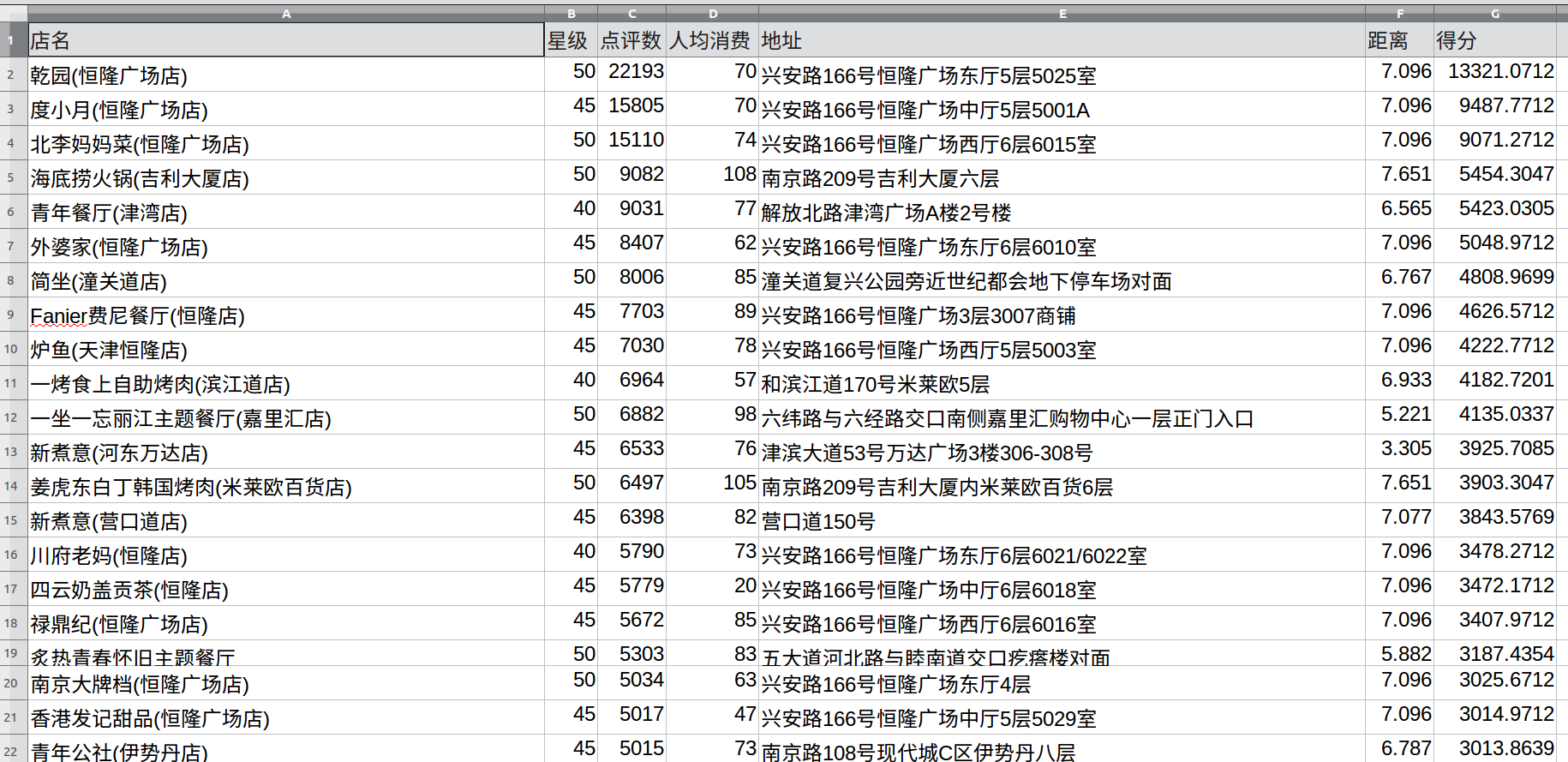
0x00 需求与思路##
和老板去天津出差,为老板定制美食攻略。老板要求吃饭的地方最好别离下榻的酒店(位于河东区)太远。
为了体现吃货本质,又来去方便,在点评网上抓取中心城区以内邻近的几个行政区的餐厅信息,通过添加过滤条件初步筛选出符合我们要求的餐厅,再对这些餐厅的一些属性值进行加权,计算每个餐厅的得分并排名。
0x01 过滤条件##
- 行车距离:以我们住宿的酒店为原点,行车距离半径8公里以内的餐厅
- 星级:大于等于4星
- 行政区:河东区、河西区、河北区、和平区以内的餐厅
0x02 网页解构分析##
2.1 策略###
选择【天津】【美食】【行政区】【点评最多排序】
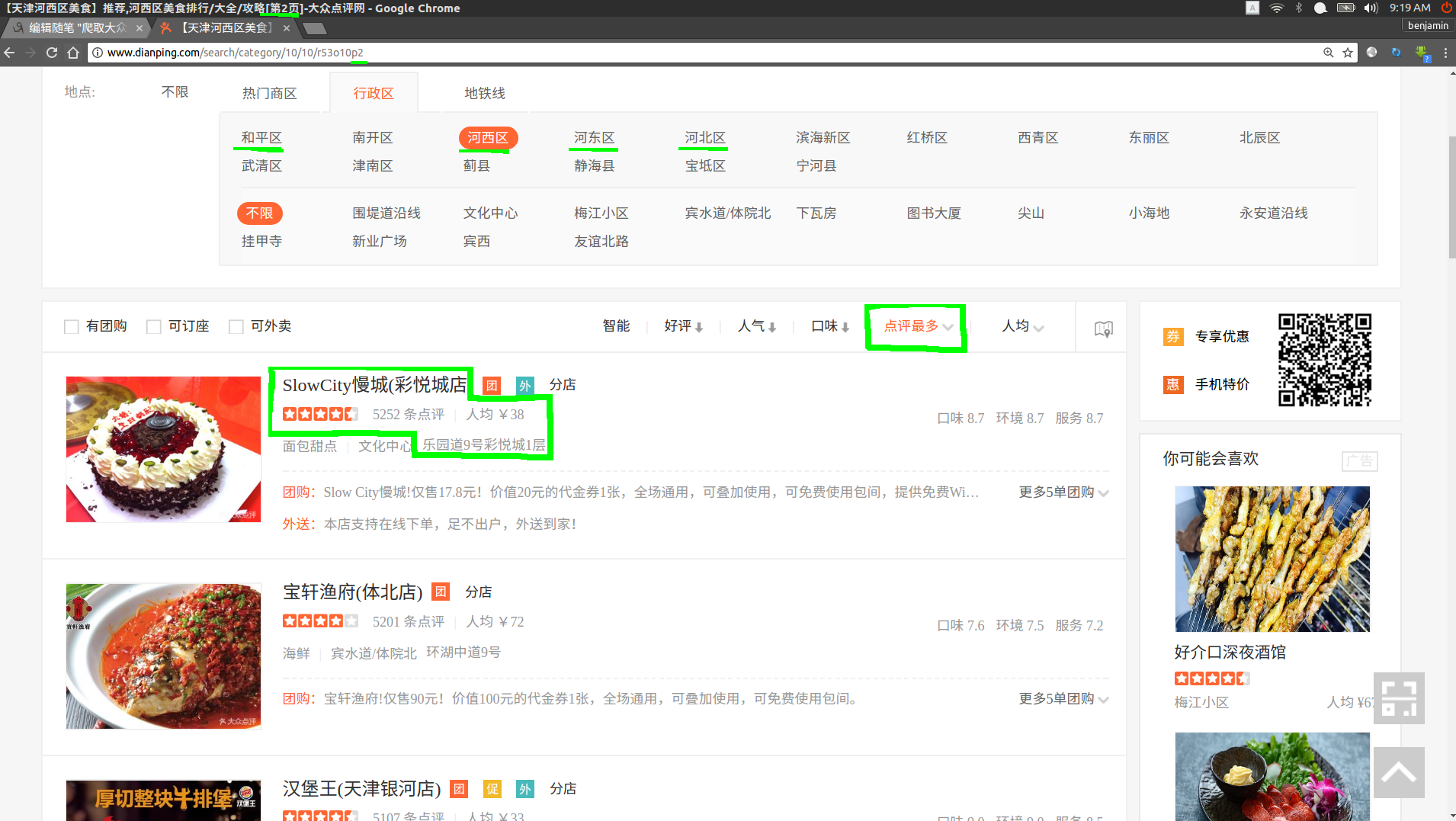
观察页面,可以看到每一个行政区从第2页开始,url=第1页的URL+p+页码
每一页默认有15家餐厅,每一家餐厅都有星级、点评数量、人均消费、地理位置,这些信息我们都需要抽取出来。
2.2 操作###
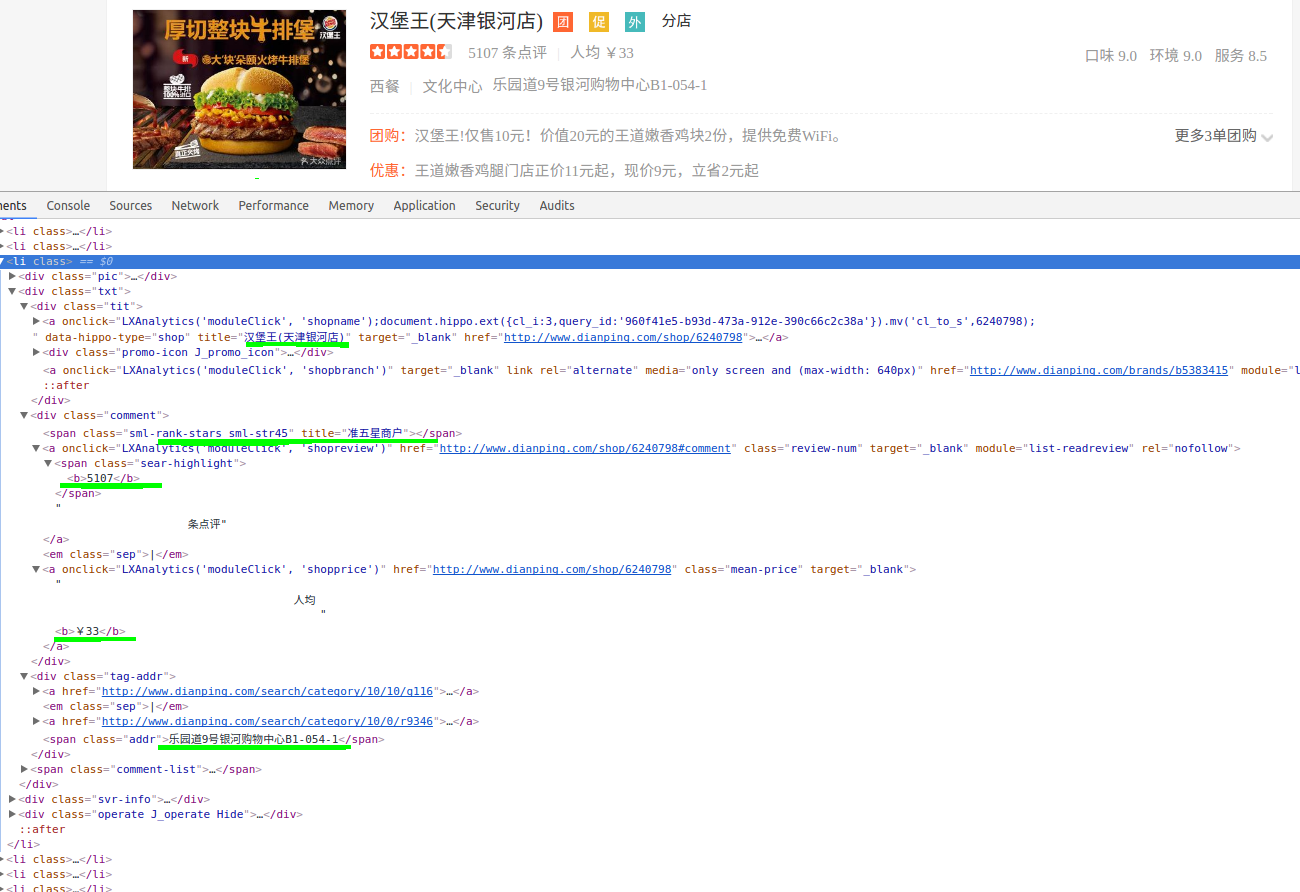
使用python的requests包发送页面请求,通过BeautifulSoup来解析。获得页面的html之后,通过正则来抽取以上信息。
0x03 获取行车距离##
使用百度提供了LBS的API(需要申请开发者认证),使用python的requests包进行接口调用。
0x04 源码实例##
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
import requests
import time
from bs4 import BeautifulSoup as bs
import re
import json
def getDistance(apiurl):# 获取两个地点间的行程距离
res = requests.get(apiurl)
js = json.loads(res.text)
if js["status"] == 0:
try:
if js["result"]["error"] == 0:
return js["result"]["taxi"]
except Exception as e:
print('CannotGetDistance:' + apiurl, e)
return 0
else:
return 0
def getInfo(targeturl):# 解析网页,抽取信息
starpattern = re.compile(r'sml-strdd') # 星级
npattern = re.compile(r'<b>[0-9]{1,}</b>') # 点评数
with open('result.csv', 'a') as f:
response = requests.get(targeturl, headers=myheaders)#
soup = bs(response.text, "lxml")
shoplist = soup.find_all(class_='txt')
for eachshop in shoplist:
try:
stars = re.search(starpattern, str(eachshop)).group(0)[7:]
commentnum = re.search(npattern, str(eachshop)).group(0).split('<b>')[-1].split('</b>')[0]
except:
continue
else:
if int(stars) >= 40:
expense = str(eachshop).split('¥')[-1].split('</b>')[0]
shopname = str(eachshop).split(r'<h4>')[-1].split('</h4>')[0]
addr = str(eachshop).split(r'class="addr">')[-1].split('</span>')[0]
origin = '索亚风尚酒店'# 酒店位置
ak='这里是你的百度应用AK'
# 设置起点即酒店、终点即餐厅、起点所在城市、终点所在城市
apiurl = "http://api.map.baidu.com/direction/v1?mode=transit&origin=%s&destination=%s&origin_region=%s&&destination_region=%s&output=json&ak=%s" % (origin, addr, '天津', '天津', ak)
queryrslt=getDistance(apiurl)
if 0==queryrslt or None==queryrslt:
continue
else:
if 8.0 >(queryrslt["distance"] / 1000):
newline = '' + shopname + ',' + stars + ',' + commentnum + ',' + expense + ',"' + addr + '",'+str(queryrslt["distance"] / 1000)
f.write(newline+'
')
else:
continue
if __name__=='__main__':
myheaders = {
"Host": "www.dianping.com",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36",
"Referer": "http://www.dianping.com/tianjin/food"
}
hedongbaseurl = 'http://www.dianping.com/search/category/10/10/r54o10'#河东区url
hexibaseurl = 'http://www.dianping.com/search/category/10/10/r53o10'#河西区url
hepingbaseurl = 'http://www.dianping.com/search/category/10/10/r51o10'#和平区url
hebeibaseurl = 'http://www.dianping.com/search/category/10/10/r55o10'#河北区url
baseurllist = []
baseurllist.append(hepingbaseurl)
baseurllist.append(hexibaseurl)
baseurllist.append(hedongbaseurl)
baseurllist.append(hebeibaseurl)
f = open('result.csv', 'a')
f.write('店名,星级,点评数,人均消费,地址,距离
')
f.close()
for eacharea in baseurllist:
getInfo(eacharea)
for page_index in range(2, 51):
#time.sleep(2)必要的时候控制一下速度
getInfo(eacharea + 'p' + str(page_index))# 构造每个行政区的从第2页到第50页的url
0x05 结果##