动态内存分配
前几节讲过,加载程序时,bss区域是映射到匿名文件的,其大小包含在目标文件中,堆和栈也是映射到二进制0的,但初始长度为0。类似于栈指针,也有堆指针,brk,指向堆顶,由内核维护,堆向上(高地址)增长,栈向下(低地址)增长。
动态内存分配主要针对堆操作,会把堆看作许多个块来维护,将空闲的块分配给需要的应用程序,已分配的块需要程序显式执行释放(如free),或利用垃圾收集机制隐式释放。那为什么需要动态内存分配呢?因为有些时候需要在程序运行时才能决定要申请的内存空间的大小,比如根据输入创建,程序加载并刚开始运行时,堆大小为0,此时堆大小可以随运行时的动态内存分配而改变。
介绍一下malloc函数:
其参数为需要申请的内存字节数,返回值为指向分配的内存块的指针。注意申请到内存块大小的不一定就等于需要的字节数,由于有对齐需求,可能会得到更大一些的内存块,申请失败返回NULL并设置errno。malloc不初始化返回的内存,要初始化为0可以用类似的函数calloc,此外有个realloc函数可以改变一个已分配块的大小。
可以看到,malloc实际就是返回一部分的块的指针给申请的应用程序,同时修改堆的大小,因此底层的实现应该涉及到堆指针brk。那么有什么函数能操控堆指针呢?
答案是 void *sbrk(intptr_t incr),此函数将堆指针增加incr,返回brk的旧值,失败返回-1并设置errno,incr为正则是扩展堆,为负则是收缩堆。
碎片
动态内存分配容易出现一种问题,就是明明仍有足够的内存,却无法满足分配请求,这是由“碎片”导致的。碎片分内部碎片和外部碎片,前者引发原因就是之前说的,当申请一块指定大小的内存时,由于一些原因,比如对齐要求,会分配比申请大小更大的内存,这就是内部碎片。外部碎片则是当空闲内存合起来能满足分配要求,但任一单一的空闲内存块都比需求的内存小时,引发的。
隐式空闲链表
一个好的动态内存分配器,必须能解决之前提到的种种问题,比如如何记录空闲块?如何选择合适的空闲块并进行分配?当空闲块比申请空间大很多时,如何处理剩余部分?当一个已分配块被释放时,如何将它与周围的空闲块合并?
要解决这些问题,需要为每个块设计合理的数据结构,比如最简单的一种:隐式空闲链表,如下图所示:
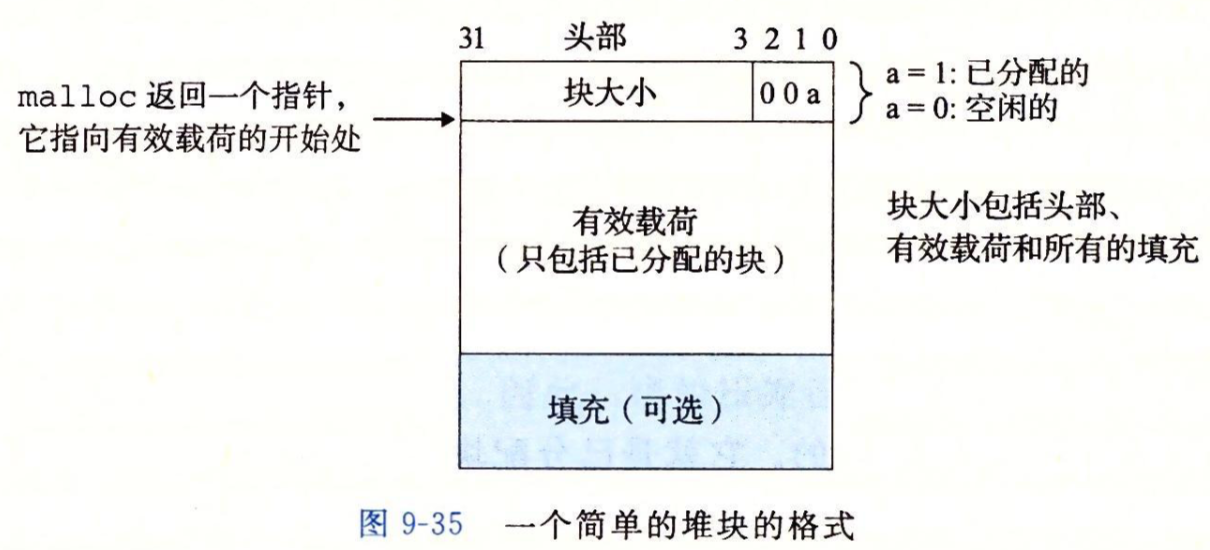
此时,一个块分三个部分,首先是一个8字节(双字)的头部,头部会记录整个块(包括头部,有效载荷和填充)的大小,之所以用了8字节是因为我们这里采用了双字对齐要求,此外,由于双字对齐要求,所以整个块的大小一定是8字节的倍数,因此最低3位一定是0,为了更好地利用低3位,可以用它来标记当前块是已分配块还是空闲块,这里采用最低位作为已分配位。
举个例子,有一个已分配的块,其大小为24字节,则头部为0x00000018 | 0x1 = 0x00000019
有效载荷就是分配块中用来给应用程序使用的空间,填充可以用来对付外部碎片或满足对齐要求。
当要响应申请内存的请求时,分配器会遍历此链表,找到大小合适的空闲块并进行分配,直到遍历到一个含有特殊标记的结束块,这里对结束块的定义是头部记录的块大小为0,且设置了已分配位的块。之所以称其为隐式空闲链表,是因为它里面没放指针,我们仅仅通过头部就可以知道这个块的大小,从而找到下一个块,这种数据结构的缺点是每次分配都要重新遍历链表,花费的时间与块的总数线性相关。
看个案例:

这题的主要知识点是双字对齐,以malloc(1)为例,头部占4字节,申请1字节空间,为了满足双字对齐,会分配8字节空间,所以块大小为8字节,块头部为0x8 | 0x1 = 0x9,后面的分析方法类似,看书后答案即可。
具体设计动态分配器时要考虑以下几点细节:
那么遍历并找到了合适大小的空闲块后该怎么办呢?
有几种适配策略:首次适配,下一次适配和最佳适配,这个比较好理解,看书即可。
那么确定了适配的空闲块后,如何分配内存?
可以整个空闲块分配出去,也可以选择分割,通常会选择后者,即把一个大的空闲块分成两个小的,一个分配出去,剩下一个小的空闲块。
如果空闲块不够,怎么办?
可以合并相邻的空闲块创建更大的空闲块,若仍无法满足要求,可以调用之前提到的sbrk函数,向内核请求额外的堆内存,申请的内存被放到空闲链表的末尾,随后将其中的块分配出去。
何时合并空闲块?
两种方案,一是在每个块被释放时,合并所有相邻空闲块,二是推迟合并,直到某个分配请求失败,再扫描整个堆,合并空闲块。立即合并可能会导致抖动现象,比如先申请某个大小的块,导致了对某个空闲块的分隔,随后又释放它,导致了合并,随后又申请同样大小的块,又导致分割,马上又释放,导致合并。。。如此往复,会产生大量不必要的分割与合并。
如何实现合并空闲块?
合并空闲块面临的最大问题是如何合并当前释放块前面的空闲块,因为合并的时候需要将两个块的大小相加并赋给新的块,假如传递一个指针进来,指向要释放的块,此时没有办法得到前面那个块的头部信息。一种解决办法是搜索整个链表,记住前面块的位置,直到抵达当前块,但这太蠢了。。。
一种更好的办法是“边界标记”,即在块的结尾处添加一个“脚部”,它是头部的一个副本,如下图:
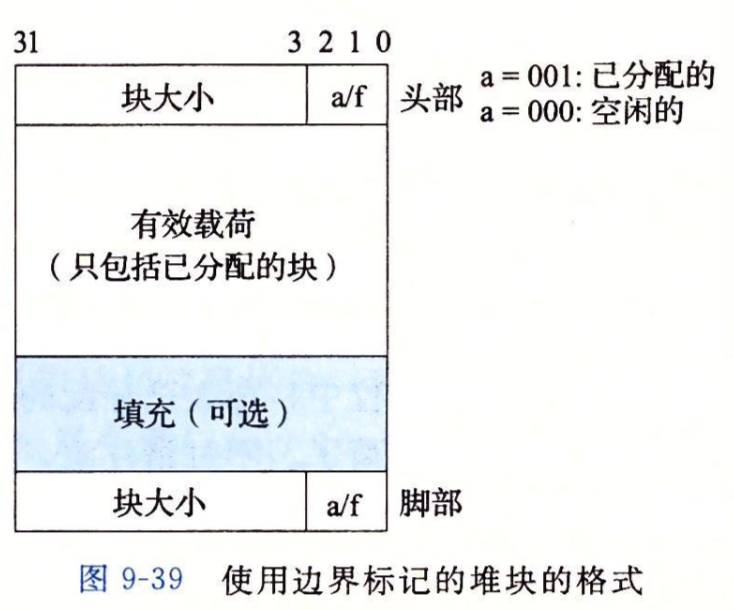
这样,当指针指向被释放块的头部时,我们可以通过减一个字(4字节)的距离,将指针指向上一个块的脚部,此时若从脚部读出此块是空闲块,则可根据从脚部独处的大小移到此块的头部进行修改。
合并分四种情况:

四种情况图中已经标得很明白,需要注意的是合并的同时要修改新块的头部和脚部。
举个例子:


这个例子和上面那个基本一样的思路,只不过现在多了个脚部,比如分析一下第3个,双字对齐要求下,已分配的块头部和脚部,需要4+4=8个字节,又因为是已分配的,所以申请的空间至少1字节,又因为双字对齐要求,因此已分配块的最小块大小为4+4+8=16个字节,空闲块未分配字节,最小为4+4=8字节,而一个块在不同时候可以被分配和释放,因此最小块大小要同时满足两种形态下的最小块要求,因此总最小块为16字节。其余的分析类似,不再列举。
简单分配器的实现
上面介绍了具体设计动态分配器时要考虑几点细节,下面根据这些细节,看一下一个简单分配器具体实现:
先介绍memlib.c包提供的两个工具函数:

其中,mem_init函数负责用malloc将所有可用的虚拟内存化为大的字节数组,注意,这并不是把它变成了堆的空间,malloc分配时是利用分配器向堆申请空间的。mem_sbrk函数与之前提到的sbrk系统函数功能基本一致,只是多了个incr的判定,去掉了收缩堆的功能。
随后介绍一下隐式空闲链表组织形式:
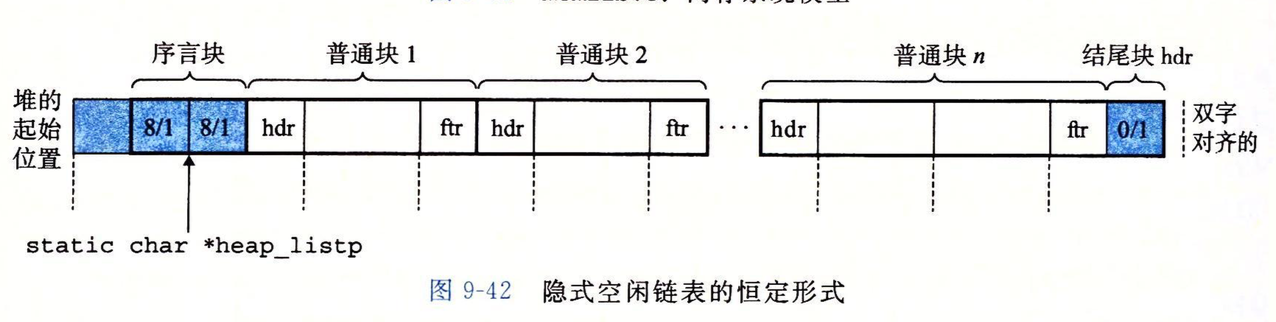
图中每个方框代表一个4字节的字,第一个字是不使用的填充字,随后有一个序言块,8/1代表块总大小为8字节,且是已分配的,很明显,序言块是有头部与脚部的,且没有申请任何字节,它在初始化时被创建,永不释放。后面的普通块,hdr代表头部,ftr代表尾部,最后以一个块大小为0,已分配的块作为结尾块,它只有一个头部,初始时分配器会让一个指针heap_listp指向序言块(不是序言块的头部)。
再介绍一下要用到的宏与参数:

WSIZE和DSIZE定义了字和双字的大小,CHUNKSIZE定义了初始空闲块的大小扩展堆时的默认大小,这里是212=4KB
重点是几个工具宏:
PACK:用于返回头部信息,传入块大小和已分配位,返回的值就是用来存在头部和脚部中的信息
GET:传入一个指针p,返回的是该指针指向的4个字节的unsigned int值,这里用unsigned int*作转换,明显是为了获取块的大小用的,当传入的指针指向块的头部时,可以用GET获取头部存储的块的大小和分配位信息。
PUT:与GET相反,传入一个指针p和一个值val,把val存放在p指向的4个字节中。
GET_SIZE: 显然它负责把GET取出的4字节的字的低3位置0,可以用于从头部/脚部取出块的大小和分配位信息后进一步提取出其中的块大小信息。
GET_ALLOC: 类似GET_SIZE,不过这里提取的是最后一位的分配位信息。
HDRP: 它可以根据传入的指向块的指针,找到相应的指向头部的指针。(注意,这里的指向块是指向该块头部后的起始地的,就如指向序言块的heap_listp指针那样,显然,块指针和头部指针就相差一个字的距离)
FRTP: 它可以根据传入的指向块的指针,找到相应的指向脚部的指针,实现的思路是:先利用GET_SIZE得到该块的大小,当前块指针加上它就会指向下一个块的块指针,它和上一个块的脚部差了一个头部(4字节)和一个脚部(4字节),所以减1个双字的大小即可指向当前块的脚部。
NEXT_BLKP:它可以得到下一个块的块指针,具体不再分析。
PREV_BLKP:它可以得到前一个块的块指针,具体不再分析。
下面实现分配器的基本功能,实现的时候要注意,完成之前细节讨论中要注意的地方。
首先是对分配器的初始化,具体任务是创建新的空闲链表。

具体操作手法:先使堆扩大4个字的空间(注意一开始堆大小为0),随后如9-42的图所示,先设置一个字的填充块,随后是序言块的头部和脚部,随后是结束块,设置完后将heap_listp指向图中所示的序言块的头部后起始的地方(这里因为序言块申请字节为0,所以相当于指向脚部)。最后要进一步扩大堆的空间,扩大的堆空间被标记为空闲块,这由extend_heap函数完成,其实现如下图所示:

extend_heap函数功能就是为堆申请指定大小的新空间,它会将传入的大小进行双字对齐,并进行扩展,扩展后返回块指针,指针指向的空间已经被扩展了,它是跟在结尾块的后面的,因此结尾块不再是结尾块,需要将它变成新空闲块的头部,同理要将扩展空间的最后一个字设置为结尾块,相当于做了一个挪移效果,这几步在第12-14行被设置完成,很有意思。最后的coalesce函数负责合并空闲块,它的实现如下图所示:

它对应处理的是之前图中展示的4种合并情况,这里不再具体解释。
实际供外部调用的分配函数是mm_malloc,如下图所示:

首先主程序里调用之前说的mm_init函数,来将堆进行基本的扩展,并创建必要的结构块,如序言块,结尾块,以及基本的空闲块,当需要申请分配空间时,调用mm_malloc函数,它会先检测请求的块的大小,使之满足双字对齐条件,随后搜索堆中的空闲链表,找到合适的空闲块进行放置并进行合理的分割,最后返回新分配块的地址。如果没找到合适的空闲块,说明向堆申请空间时,堆的空间已经无法满足要求了,此时需要用之前的扩展堆的函数,对堆进行扩展,将请求的块放置在堆扩展后的块中。
放置和寻找匹配块的函数如下图所示:
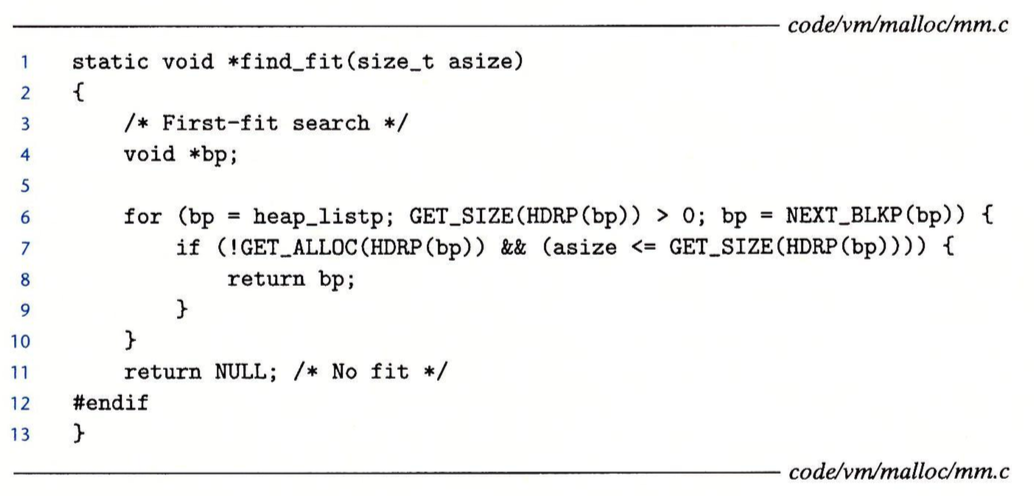

寻找匹配块的策略比较简单,只要该空闲块的大小大于申请的空间大小即可,放置采用首次匹配的策略,需要注意的是,这里要判断放置后剩余的块大小是否大于最小块大小(这里因为有头部和脚部,最小块大小为双字,即8字节),不是则直接放置,是则需要进行分割,分割只要多造出一个头部和脚部即可。
最后是释放已分配的块的功能的实现,如下图所示:

只需把对应的块的头部和脚部标为空闲,随后进行合并即可。
后面的显式空闲链表及垃圾收集机制讲得太少,不记录了,下次参考了其它资料专门作专题记录吧。
最后是一些C程序里的常见的和内存有关的错误:
大部分已经知道了,没什么记录意义,有两个有点意思,记录一下:
1.引用不存在的变量:

这段代码返回了局部变量的地址,还记得第三章讲述的吗?因为在代码中用到了val的地址,所以val不会被放在寄存器里,而是会放在栈上,此时函数执行结束后,返回的地址虽然是合法的,但可能会有这样一种情况:程序调用了其它函数,并再次用了栈帧,这样,这个地址指向的数据是属于其它函数的数据,而后面当我们对这个地址的内容进行修改时,会直接改掉其它函数中的数据,会带来麻烦的后果。
2.引用空闲堆块中的数据:

这里向堆申请的块已经被释放了,然而我们后面又引用了指向这个块的指针,对其指向的内容修改,从之前的讲述中我们知道,被释放的块是空闲块,会再次被分配给其它的向堆申请块的程序,这时候修改显然会影响到那个程序。
这个错误本质和上面那个是一样的,只不过一个发生在栈中,一个发生在堆中,所以当初学C语言的时候,书里经常会讲,当我们用free释放某个块时,还需要把对应的指向块的指针设为null,当时的理由是防止出现野指针,实质就是上面讲述的问题。