数值类型
整数型 tinyint smallint mediumint int|integer bigint
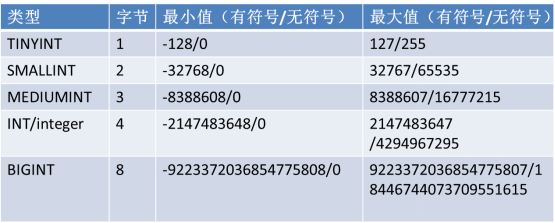
注意:
1, 如何选择数据类型,我们的原则是:够用就行!尽量的选择占用内存小的整型,而且效率也更快!
2,可以使用unsigned来控制是否有符号位,如果不写,缺省值是有符号的
MySQL不会进行自动类型转换,如果超出了指定类型的范围,就直接报错!
3,可以指定数据显示的最小宽度,以达到统一显示的目的,通常的做法就是使用zerofill来进行填充
如果插入的数据,超出了指定的显示宽度,不影响原有的数据,该怎么显示就怎么显示:
4,其实,在MySQL中,也有bool型,但其实就是tinyint(1)的别名!
小数型 又可以分成浮点数和定点数!

浮点数 分成了单精度型和双精度型!其中单精度占4个字节,而双精度占8个字节!
单精度的有效位在6-7位之间,而双精度的有效位在16-17位之间!所以,我们在插入浮点数的时候也要注意,有时候没有超过浮点数的范围,但是超出了浮点数的精度!
注意: 1,浮点数还支持控制数字的范围,语法形式为:type(M,D)这里的type是指float或double!
M:表示是所有数值位的范围(包括整数和小数部分,不包括小数点)D:表示小数的位数的范围,小数超出的部分会四舍五入
2,同php一样,浮点数也支持科学计数法
定点数 采用定点数存储!关键字:decimal
定点数策略:每当出现连续的9位数的时候,用4个字节单独存储,而且整数部分和小数部分分开存储!
定点数优缺点: 优点:所有的数据都会被精确的存储,不会造成数据的丢失! 缺点:占用的空间较大
注意:1, decimal同样支持decimal(M,D)语法此时,M指的是总位数,D代表小数的位数,默认的情况下,M为10,D为0
2, decimal同样也支持zerofill语法由于货币值往往都是decimal型,所以decimal型也叫作货币型!
日期时间型

datetime 和 timestamp
datetime和timestamp的显示形式和插入形式基本上是一样的,只是存储形式和能表示的日期的范围不一样,在timestamp中存储是整型,但是其显示形式和插入形式和datetime一样都是年月日时分秒
注意: 插入数据的时候可以支持任意的格式,使用什么分隔符不重要,日期的范围和格式才重要!
另外,还可以使用mysql内部的一个函数now()来插入,意思就是当前的年月日时分秒
date 相当于datetime的一个“子集”,只有年与日没有时分秒!
time time型有两个含义:1, 一天中的时间(也就是datetime中的一个“子集”,只有时分秒)
2, 表示时间间隔,表示时间的间隔的时候,格式为,D HH:MM:SS也就是 天 时:分:秒
year 只表示年份,但是年份可以简写,比如现实中98年认为是1998年!范围比较小,只能是1901年到2155年,因为只占一个字节!
注意: 如果年份只写两位,大于等于70的就代表19XX年,小于等于69的代表20XX年!


字符串类型
char和varchar
在定义的时候,都需要指定字符串的长度!char(M),varchar(M)
但是,varchar中的M仅仅表示一个范围,在实际的存储中,实际的长度是可变,只要不超过M就行了!理论上最多M的最大值是65535个字节,但是,由于需要占用1-2个字节来保存其他的信息,同时整条记录也有一个限制,也不能超过65535个字节!
由于创建表的时候,默认的字符集是utf8,所以varchar中的M的最大值是21844
总结:
1, varchar中的M只是一字节范围
2, 如果是utf8编码,这里的M的最大值也就是2万多,如果gbk编码,这里的M的最大值也就是3万多!
char中的M的范围是一个字符数,不超过255个字符!
因为这里的长度M是定长的,因为就是这里定义成多少个字符,在实际存储的时候就占用多少个字符
char与varchar的比较
1, varchar对存储空间的使用更加灵活
2, char的效率更高
3, 如果存储的字符串的长度是已知固定的,就用char,如果是可变的,就用varchar
text
也叫作文本类型,又可以分成四种:
tinyText,text,mediumText,longtext,其中longtext一般认为长度没有限制!
text类型使用起来跟varchar差不过,只不过这里不用指定长度,在实际的开发中,一般文本框和其他自由输入区域(比如一篇文章,一个新闻等)都是用text类型来存储!
enum
也叫作枚举类型,类似于单选!
在定义enum类型的时候,需要把所有可能的选项都罗列出来!
并且,用户在插入数据的时候,也只能插入单选项中的选项值:
注意:
单选项在内存中实际存储的其实是整型数据:
所以,在插入数据的时候,也可以直接插入该选项对应的编号:
就是说,各个选项实际在内存中的编号是,从左往右存储的是:
1,2,3,4,5
最多可以存储65535个选项!用一两个字节就够了!
set
也叫作集合类型,类似于多选项!
同enum一样,在定义set类型的时候一样需要把所有可能的值罗列出来!
既然是多选项,所以在插入的时候可以插入多个选项,并且插入选项的顺序可以和表中定义的顺序不一样:
注意:
set类型的值在内存中存储的一样是这些选项在定义表的时候的位置
这里的选项代表的位置从左往右依次是:
1,2,4,8,16
多选项最多只可以有64个!
Binary,varbinary,blob
这三个都称为二进制文本类型,也就是说,里面实际存储的就是二进制形式,也就是所谓的字节流(相当于我们前面学习都是字符流)
Binary,varbinary,blob就是二进制流的char、varchar和text
在实际的应用中,二进制文本类型基本不使用!比如,图片(二进制)一般也不用直接以二进制的形式存储到数据库中,而是仅仅保存该图片的路径或该图片的名字!
列属性
所谓的列属性,就是在定义一个列(字段)的时候对该列设置的额外的信息或约束!
所以,一个列属性也往往对应着一个列约束!列属性和列约束其实是不同方向上的不同理解而已(本质是一样的)
null和not null
默认情况下,字段都允许为空(缺省值为null),如果加上not null,意思就是这个字段不能为空,所以,not null也叫作非空约束!
也就是说,当我们没有给一个not null属性的字段插入值的时候,系统会首先判断该字段有没有一个默认值,如果没有,就报错!
default
自定义默认值属性,也叫作自定义默认值约束,通常就是配合not null一起使用!
也就是说,在给一个字段加上not null属性的时候,也往往给它设置一个default属性,这样一来,如果给这个字段插入值的时候,就以插入的值为标准,如果没有给该字段插入值,就以默认值为标准!
在插入数据的时候,也可以直接插入default关键字,注意这里的关键字不能用引号括起来!
primary key
简称PK,也叫作主键属性或者主键约束!主要的键,主要的字段!
主键的概念:
可以唯一标识某条记录的字段或字段的组合(组合主键)!
在实际的运用中,很少使用组合主键,而往往都是利用一个和实体信息完全不相关的属性作为唯一的主键,这样做的好处就是主键与业务逻辑不发生任何的关系,只是用来标识记录
设置主键有两种方式:
第一种:在定义一个字段的时候直接在后面进行设置primary key
需要注意的几点:
1,定义一个字段为主键后,该字段就不能重复!
2,主键不能为空null
事实上,当我们定义一个字段为主键之后,系统会自动的给该字段加上非空约束:
第二种:定义完字段后再定义主键
效果是一样的,但是如果定义组合主键的话,只能用第二种方式:
注意:
组合主键的含义是两个或多个字段组合在一起形成一个主键!而不是所有的字段都是主键,因为主键只能有一个!
unique key
也叫作唯一键属性或唯一键约束!增加该属性后,该字段的值就不能重复!
定义的方式和主键是类似的:
也就是说,唯一键可以有很多个!
另外,唯一键和主键的一个区别是:唯一键允许为空,但是主键不能为空!
另外:unique key 可以简写成unique
auto_increment
自增长属性,或者自增长约束!
作用是每次插入记录的时候,自动的为某个字段的值加1(基于上一个记录)
注意:
使用这个属性有两个条件:
1, 该字段类型必须为整型
2, 该字段上必须存在索引(后面讲,主键也叫作主键索引,唯一键也叫作唯一键索引)
型的,
在真实的项目中,首先,用一个id字段作为主键(和记录上的主体没有任何的关系,仅仅表示一条不同的记录而已),其次,就是在该主键上增加auto_increment属性!
这样一来,每次插入主键字段的时候,就可以直接插入null!这里的插入null不是真正的将null这个值插入到主键(主键不允许为null),而是告诉系统这里开启自动加载机制!
注意:
1,开启了自动增长机制,并不代表不能手动插入!
2,自动增长是以前面出现的最大值自动增长!
3,delete from表中所有的数据之后,并不会重置自动增长机制!
如果想重置自动增长,可以使用truncate 表名语法!
comment
是专门为列做注释的(描述的),与其他的注释符不同之处在于,这里的注释内容属于列定义的一部分:
实体与实体关系
现实生活中,实体与实体之间肯定是有关系的,我们在设计数据表的时候,也应该体现出这种表与表之间的关系,我们把这种关系总结成三种:
一对一
一对多(多对一)
多对多
外键
概念
关键字:foreign key 也叫作外键属性或外键约束!外面(其他表)的主键!
如果一个实体A的某一个字段,刚好指向或引用另一个实体B的主键,那么实体A的这个字段就叫作外键,所以简单来说,外键就是外面的主键,就是其他表的主键!
作用
外键的意义就是用来约束关系内的实体!
假如上面学生表中有一个学生的班级字段是11,就不符合正常的业务逻辑!
所以,外键约束主要体现在以下的两个方面:
1, 增加子表记录的时候,是否有与之对应的父表记录!
2, 当删除或更改父表记录的时候,从表应该如何处理相关的记录!
定义
语法格式如下:
foreign key(子表字段) references 父表名(父表主键)
应该先创建父表:
再创建子表:
设置级联操作
所谓的级联操作,就是在操作父表的时候,会以什么样的形式影响到子表,也叫作关联操作或者关联动作!
此时,主表操作主要体现在以下两个方面:
主表更新
语法形式为:on update[级联操作]
主表删除
语法形式为:on delete[级联操作]
这里的级联操作常见的有三种形式:
cascade:同步操作,或者串联操作!也就是当主表记录删除或更新的时候,从表也进行相应的删除或更新!
set null:设置为null,也就是当主表记录删除或更新的时候,从表中的外键字段设置为空
restrict:拒绝主表的更新或删除
现在,先把上面itcast_student表的外键删除掉:
删除外键的语法
alter table 表名drop foreign key 外键名;
注意:这里的外键名并不是字段名,一般如果在创建外键的时候没有给该外键起一个名字,系统会自动分配一个外键名字!
增加外键的语法:
alter table 表名 add foreign key 外键定义
关于外键,还有两点需要注意的地方:
1, 外键约束只有InnoDB存储引擎才支持!
2, 在实际项目中,往往会用到外键的设计思想,但往往不会真正的从语法上进行外键约束,因为外键约束的级联操作可能会带来一些现实的逻辑问题!另外,使用外键会较低mysql的效率!
存储引擎
表的存储引擎,也叫作表类型,指的是数据表的存储机制、索引方案等配套相关功能,不同的存储引擎,由于处理方式不同,会带来不同的功能或相应的优化,也就是,各有各的优点
所以,用户在创建表的时候,要根据实际需要合理的选择存储引擎,在windows下,默认的存储引擎为InnoDB,当然,可以在数据库的配置文件my.ini中进行修改:
范式
还有一个创建表的规范:范式!
这里的范就是规范的意思,范式就是我们设计数据表的基本规范!
范式的主要作用就是通过合理的数据存储,从而使得数据的冗余度最小化以及运行效率的最大化!
范式是分层的!
所谓的分层,就是根据不同的需求划分不同的标准,范式本身是数学上的概念,本来可以分6层,被引入到数据库之后,由于后面的层次实在是太严格,很难实现,所以,Mysql只引入了三层范式!而且是一层一层的严格递进!
我们一般认为,满足了三层范式的数据库,就是比较合理优秀的数据库!
第一范式1NF
NF:normal format
第二范式2NF
第二范式就是在满足第一范式的基础之上再满足以下的两个条件:
1, 表中的一行都具有唯一的可以区分的特性
第一个比较容易满足,也就是表中不能有完成相同的记录,而且一般表都有主键!
2, 不能有部分依赖
什么叫依赖?
如果确定了表中的某个字段A,就能确定该表张的另一个字段B,那么我们就说B依赖于A!
很显然,所有的字段都依赖于主键!
什么叫部分依赖?
主键可以是组合主键,比如现在有一个组合主键(A,B),此时,其他所有的字段都应该依赖于这个组合主键,但是,此时如果有某个字段C,它只依赖于A,我们就说,此时,产生了部分依赖
第三范式3NF
第三范式就是在满足第二范式的基础上,消除传递依赖!
什么是传递依赖?
如果一个表中某个字段不直接依赖于主键,而是先依赖于其他的字段,就叫作传递依赖!
比如:
主键是A,B依赖于A,而C又依赖于B!
注意:并不是C不依赖于A,而是C只能等B确定后才依赖于A!
其他数据操作
数据的操作也叫作crud: C:create R:read U:update D:delete
插入数据
标准语法:insert into 表名[字段列表] values(值列表)
蠕虫复制 就是在已有的数据的基础之上,将原来的数据进行复制,插入到相对应的表中!
语法规则:insert into 表名 select *|字段列表from 表名
注意:当一个表中的数据复制到另一个表中的时候,需要注意数据的来源要与被插入的表的字段数量和类型要保持一致!
蠕虫复制的优点:1, 可以以最快的速度复制另外一张表的数据 2, 在短期内产生大量的数据,以测试服务器的压力
主键重复
策略一:语法:insert into 表名[字段列表] values(值列表) on duplicate key update 字段1=值1,字段2=值2……
当主键不冲突的时候,相当于一条插入语句,当主键有冲突的时候,相当于一条更新语句!
策略二:如果主键重复,直接删除原纪录再插入 语法:replace into 表名[字段列表] values(值列表);
在插入之前进行一次判断,判断有没有主键重复,如果没有,跟普通的插入语句没有区别,如果有主键冲突,先删除以前的记录,再插入新记录!
修改数据
标准语法:update 表名 set 字段1=值1,字段2=值2……where条件;
还可以加上orderby子句和limit子句:update 表名 set 字段1=值1,字段2=值2……[where条件][order by 字段名 asc|desc][limit 数据量]
删除数据
标准语法:delete from 表名 [where条件] [order by 字段名 asc|desc][limit 数据量]
还有一个类似删除功能的语法:truncate table 表名; 或 truncate 表名;
注意:该语句不属于DML,属于DDL
相当于做了两件事情: 1, 先把原表drop掉! 2, 再按以前的原表的结构重新创建一次!
查询数据 查询数据可以说是整个业务逻辑中使用的最多也是最复杂的!
以前的语法:select * |字段列表 from 表名 [where子句];
一个比较完整的语法:select [select选项] *|字段列表 [as 字段别名] from 数据源 [where子句][group by子句][having子句][order by子句][limit子句];
以上的语法一般只是单表查询,另外还有多表查询,多表查询又有联合查询、子查询、连接查询(左连接,右连接,内连接,外连接,自然连接)
注意:1, from后面的子句往往称之为:五子句,也叫五子查询! 2, 五子查询都可以没有,但是,如果要有,就必须按顺序写!
select选项 含义:就是系统在查询到相关数据之后,如何显示!
这里的select选项有两个值:all:也是缺省值(默认值),保留所有的查询结果! distinct:去重,去掉重复的查询结果
别名 所谓的别名,就是给字段或其他表达式等标识符另起一个名字, 基本语法如下:字段|表达式|表|子查询 [as] 别名
这里的as可以省略,但是为了增加可读性,一般还是写上!
虚拟表 查询语句的比较完整的语法:
select [select选项] *|字段列表 [as 字段别名] from 数据源 [where子句][group by子句][having子句][order by子句][limit子句];
一条真实的sql语句,有可能连字段没有!典型的,select语句可以当计算器使用:
where子句
语法和使用流程 语法:where 表达式
功能:通过限定的表达式的条件对数据进行过滤,得到我们想要的结果
流程:逐一取出每一条记录,先通过当前记录来计算where后面表达式的值,如果计算的结果为真(非0),就返回来记录,如果计算的结构为假(0),则不返回记录!相当于对所有的记录做了一次遍历!
MySQL运算符
关系运算符 < > <= >= = !=(<>)
注意:这里的等于是一个等号
between and 做数值范围限定,相当于数学上的闭区间!另外,between and 的前面还可以加上not,代表相反!
n和not in 语法形式:in|not in(集合) 表示某个值出现或没出现在一个集合之中!
逻辑运算符 && and|| or! not
where子句的其他形式
空值查询 select *|字段列表 from 表名 where 字段名 is [not] null
糊查询 也就是带有like关键字的查询,常见的语法形式是:select *|字段列表from 表名 where 字段名 [not] like ‘通配符字符串’;
所谓的通配符字符串,就是含有通配符的字符串!
MySQL中的通配符有两个: _ :代表任意的单个字符 % :代表任意的字符
group by子句 也叫作分组统计查询语句! 语法:group by 字段1[,字段2]……
统计函数(聚合函数)
sum():求和,就是将某个分组内的某个字段的值全部相加
max():求某个组内某个字段的最大值
min():求某个组内某个字段的最小值
avg():求某个组内某个字段的平均值
count():统计某个组内非null记录的个数,通常就是用count(*)来表示!
注意:统计函数都是可以单独的使用的!但是,只要使用统计函数,系统默认的就是需要分组,如果没有group by子句,默认的就是把整个表中的数据当成一组!
字段分组 group by 字段1[,字段2]……
作用是:先根据字段1进行分组,然后再根据字段 2进行分组!所以,多字段分组的结果就是分组变多了!
回溯(su)统计 回溯统计就是向上统计!在进行分组统计的时候,往往需要做上级统计!
在MySQL中,其实就是在语句的后面加上with rollup即可!
注意:既然group by子句出现在where子句之后,说明了,我们可以先将整个数据源进行筛选,然后再进行分组统计!
having子句 having子句和where子句一样,也是用来筛选数据的,通常是对group by之后的统计结果再次进行筛选!
二者的比较:
1, 如果语句中只有having子句或只有where子句的时候,此时,它们的作用基本是一样的!
2, 二者的本质区别是:where子句是把磁盘上的数据筛选到内存上,而having子句是把内存中的数据再次进行筛选!
3, where子句的后面不能使用统计函数,而having子句可以!因为只有在内存中的数据才可以进行运算统计!
order by子句 根据某个字段进行排序,有升序和降序!
语法形式为:order by字段1[asc|desc] 默认的是asc,也就是升序!如果要降序排序,需要加上desc!
多字段排序 order by 字段1[asc|desc],字段2[asc|desc]……
比如:order by score asc,age desc
也就是说,先按分数进行升序排序,如果分数一样的时候,再按年级进行降序排序!
limit子句 limit就是限制的意思,所以,limit子句的作用就是限制查询记录的条数!
语法 limit offset,length 其中,offset是指偏移量,默认为0,而length是指需要显示的记录数!
注意:这里的偏移量offset可以省略的!缺省值就代表0!
分页原理 假如在项目中,需要使用分页的效果,就应该使用limit子句!
比如,每页显示10条记录:
第1页:limit 0,10 第2页:limit 10,10 第3页:limit 20,10
如果用$pageNum代表第多少页,用$rowsPerPage代表每页显示的长度 limit ($pageNum - 1)*$rowsPerPage, $rowsPerPage
联合查询 关键字:union
语法形式
select语句1
union[union选项]
select 语句2
union[union选项]
select 语句3
union[union选项]
……
作用:所谓的联合查询,就是将多个查询结果进行纵向上的拼接,也就是select语句2的查询结果放在select语句1查询结果的后面。依次类推!
其中,这里的union选项跟前面学习的select选择的值是一样的,只是默认值不一样:
all:也是缺省值,保留所有的查询结果! distinct:去重(默认值),去掉重复的查询结果!
union的应用
union的主要应用有以下的两种情形:
第一, 获得数据的条件,在同一个select语句中存在逻辑冲突,或者很难在同一个select语句中实现,这个时候,我们需要把这个业务逻辑进行拆分,也就是使用多个select语句单独的分别实现,然后再用union将各个select语句查询结果“拼接”到一起!
注意的:1, 联合查询中如果要使用order by,那么就必须对这个select语句加上一对括号!
2, 联合查询中的order by必须搭配上limit关键字才能生效!因为系统默认的联合查询的结果往往比较多,所以要加以限制,当然,如果想显示全部的数据,可以在limit子句后面加上一个很大的数,比如:999999
第二,如果一个项目的某张数据表的数据量特别大,往往会导致数据查询效率很低下,此时,我们需要对数据表进行优化处理,往往就是对该数据表进行“水平分割”,此时,这些拆分后的数据表,表结构都是一样的,只是存放的数据不一样