一、课堂练习
# 课堂练习 from sklearn.datasets import load_iris # 导入鸢尾花数据 iris=load_iris() iris iris.keys() data=iris['data'] #鸢尾花数据 target=iris.target #标签,属于哪一种花 iris.feature_names #特征名:花萼长度、花萼宽度、花瓣长度、花瓣宽度 # 'sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'
图:

二、作业
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类


| 第一次分类 | 第一次类中心 | 1 | 8 | 13 |
| sum | 18 | 127 | 86 | |
| mean | 18/8 | 127/18 | 86/7 | |
| 第二次分类 | 第二次类中心 | 2.25 | 7.05 | 12.28 |
| sum | 18 | 107 | 106 | |
| mean | 18/8 | 107/16 | 106/9 | |
| 第三次分类 | 第三次新中心 | 2.25 | 6.68 | 11.77 |
| sum | 18 | 107 | 106 | |
| mean | 18/8 | 107/16 | 106/9 | |
| 聚类中心 | 中心 | 2.25 | 6.68 | 11.77 |
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
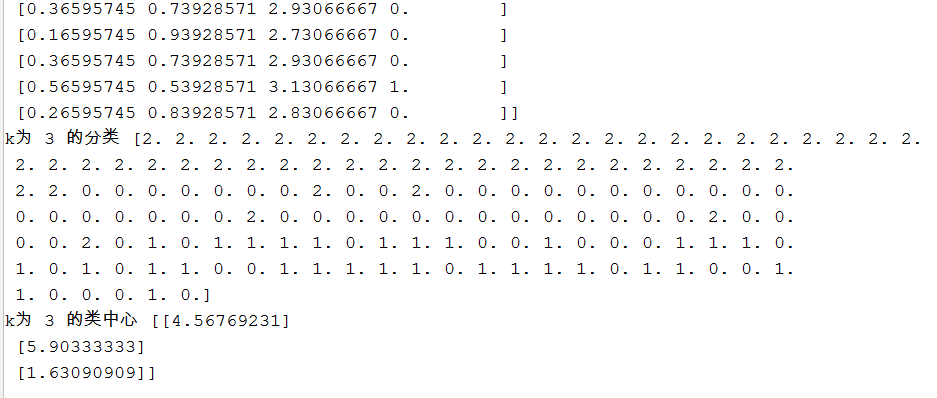
from sklearn.datasets import load_iris #导入数据 import numpy as np #numpy库 import random #生成随机的类中心 import matplotlib.pyplot as plt #画图 # 定义的参数是:数据源、聚类中心个数、属性个数 def KKmeans(dataset,k): #定义一个函数,参数是数据源和k值 n=dataset.shape[0] #样本数 m=dataset.shape[1] #样本属性 rand=random.sample(range(0,n),k) center=dataset[rand,] #k是聚类中心数,k=3的话,从中随机取三个 dist=np.zeros([n,k+1]) #相当于一个nx(k+1)的矩阵,前k列是聚类中心值,最后一列用来分类 centernew=np.zeros([k,m]) #新的聚类中心就是一个kxm的矩阵,k是k行,m是属性个数 while True: for i in range(n): # 每一行都做运算 for j in range(k): # 第一行的第一列就是第一个数与聚类中心的欧式距离 dist[i, j] = np.sqrt(sum((dataset[i, :] - center[j, :]) ** 2)) # 欧式距离 dist[i, k] = np.argmin(dist[i, :k]) # 从前k个值中取最小值的下标赋给分类的列 for i in range(k): #这一步进行归类和归类后的平均值计算,得到新的类中心 index = dist[:, k] == i centernew[i, :] = dataset[index, :].mean(axis=0) if (np.all(center == centernew)): #如果新的类中心所有的元素和类中心一样,跳出程序 break; else: center = centernew #没有一样的类中心,就将新的类中心赋值,从新再聚类 print("k为",k,"的欧式距离和分类",dist) print("k为",k,"的分类",dist[:,3]) print("k为",k,"的类中心",centernew) return dist[:, 3] kdata=iris.data[:,2].reshape(-1,1) #数据是鸢尾花的花瓣长度 KKmeans(kdata,3) #调用函数,第一个参数是数据,第二个参数是k值,即聚类中心
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.scatter(kdata,KKmeans(kdata,3),c=KKmeans(kdata,3),cmap="rainbow") plt.xlabel("花瓣长度(cm)") plt.ylabel("鸢尾花分类") plt.show()
图:
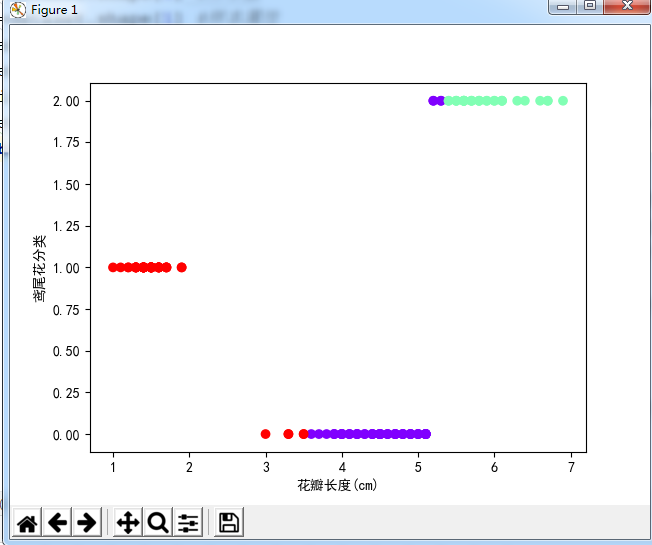
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt # 导入鸢尾花数据 iris=load_iris() data=iris['data'] #鸢尾花数据 petal=data[:,2] #花瓣长度数据 # # 换成n行1列,-1是任意行的意思 X_petal=petal.reshape(-1,1) model1=KMeans(n_clusters=3) #构建模型,聚类中心个数为3 model1.fit(X_petal) #模型训练 Y_petal=model1.predict(X_petal) #模型训练过后,根据花瓣长度预测分类 # c是按颜色分类,cmap是设置颜色 # x轴是花瓣数据,y轴是鸢尾花分类 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.scatter(X_petal[:,0],Y_petal,c=Y_petal,cmap="rainbow") plt.xlabel("花瓣长度(cm)") plt.ylabel("鸢尾花分类")
图:

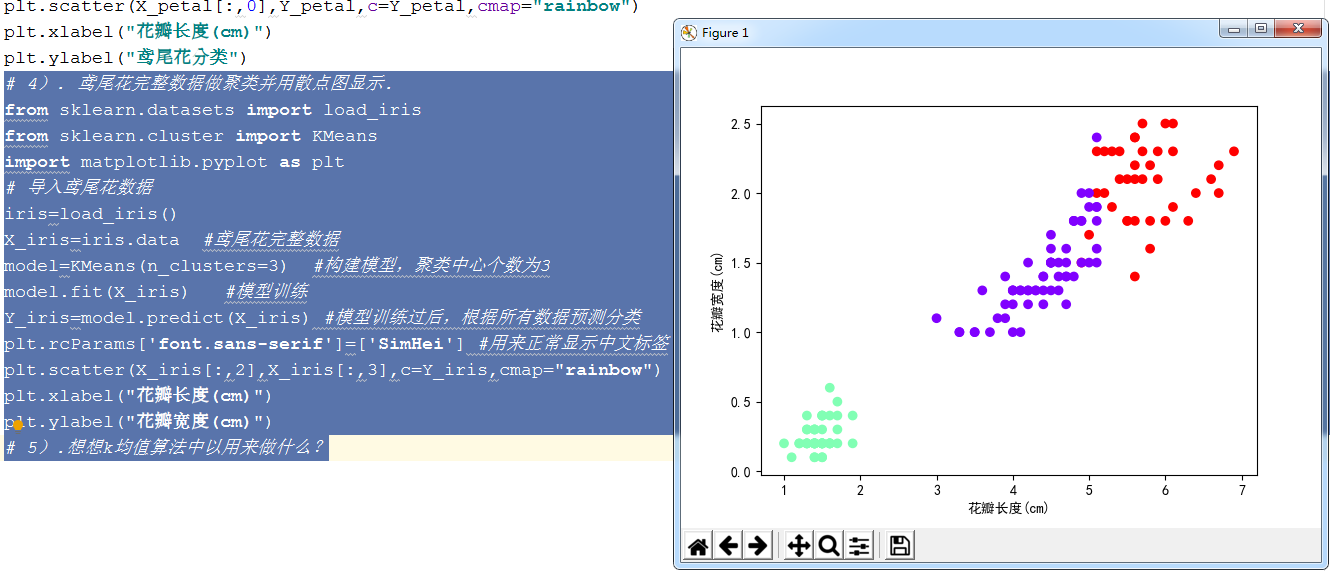
4). 鸢尾花完整数据做聚类并用散点图显示.
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt # 导入鸢尾花数据 iris=load_iris() X_iris=iris.data #鸢尾花完整数据 model=KMeans(n_clusters=3) #构建模型,聚类中心个数为3 model.fit(X_iris) #模型训练 Y_iris=model.predict(X_iris) #模型训练过后,根据所有数据预测分类 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.scatter(X_iris[:,2],X_iris[:,3],c=Y_iris,cmap="rainbow") plt.xlabel("花瓣长度(cm)") plt.ylabel("花瓣宽度(cm)")
图
5).想想k均值算法中以用来做什么?
K均值算法属于聚类算法,可以将没有标签的数据进行分类。
在实际生活中,可以帮助细分市场,可以将客户划分至不同的细分市场组,以便营销和服务;
又或者可以进行社交网络分析,观察人与人之间的互相来往,从而查找一群互相有关系的人等等。