Mayor's posters
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 32605 | Accepted: 9469 |
Description
The citizens of Bytetown, AB, could not stand that the candidates in the mayoral election campaign have been placing their electoral posters at all places at their whim. The city council has finally decided to build an electoral wall for placing the posters
and introduce the following rules:
They have built a wall 10000000 bytes long (such that there is enough place for all candidates). When the electoral campaign was restarted, the candidates were placing their posters on the wall and their posters differed widely in width. Moreover, the candidates started placing their posters on wall segments already occupied by other posters. Everyone in Bytetown was curious whose posters will be visible (entirely or in part) on the last day before elections.
Your task is to find the number of visible posters when all the posters are placed given the information about posters' size, their place and order of placement on the electoral wall.
- Every candidate can place exactly one poster on the wall.
- All posters are of the same height equal to the height of the wall; the width of a poster can be any integer number of bytes (byte is the unit of length in Bytetown).
- The wall is divided into segments and the width of each segment is one byte.
- Each poster must completely cover a contiguous number of wall segments.
They have built a wall 10000000 bytes long (such that there is enough place for all candidates). When the electoral campaign was restarted, the candidates were placing their posters on the wall and their posters differed widely in width. Moreover, the candidates started placing their posters on wall segments already occupied by other posters. Everyone in Bytetown was curious whose posters will be visible (entirely or in part) on the last day before elections.
Your task is to find the number of visible posters when all the posters are placed given the information about posters' size, their place and order of placement on the electoral wall.
Input
The first line of input contains a number c giving the number of cases that follow. The first line of data for a single case contains number 1 <= n <= 10000. The subsequent n lines describe the posters in the order in which they were placed. The i-th line among
the n lines contains two integer numbers li and ri which are the number of the wall segment occupied by the left end and the right end of the i-th poster, respectively. We know that for each 1 <= i <= n, 1 <= li <= ri <= 10000000. After
the i-th poster is placed, it entirely covers all wall segments numbered li, li+1 ,... , ri.
Output
For each input data set print the number of visible posters after all the posters are placed.
The picture below illustrates the case of the sample input.
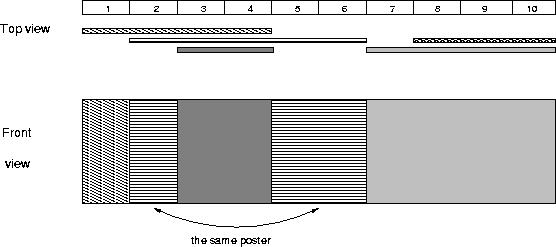
The picture below illustrates the case of the sample input.
Sample Input
1 5 1 4 2 6 8 10 3 4 7 10
Sample Output
4
Source
---------------------------------------
转题解:
题意:在墙上贴海报,海报可以互相覆盖,问最后可以看见几张海报
思路:这题数据范围很大,直接搞超时+超内存,需要离散化:
离散化简单的来说就是只取我们需要的值来用,比如说区间[1000,2000],[1990,2012] 我们用不到[-∞,999][1001,1989][1991,1999][2001,2011][2013,+∞]这些值,所以我只需要1000,1990,2000,2012就够了,将其分别映射到0,1,2,3,在于复杂度就大大的降下来了
所以离散化要保存所有需要用到的值,排序后,分别映射到1~n,这样复杂度就会小很多很多
而这题的难点在于每个数字其实表示的是一个单位长度(并非一个点),这样普通的离散化会造成许多错误(包括我以前的代码,poj这题数据奇弱)
给出下面两个简单的例子应该能体现普通离散化的缺陷:
例子一:1-10 1-4 5-10
例子二:1-10 1-4 6-10
普通离散化后都变成了[1,4][1,2][3,4]
线段2覆盖了[1,2],线段3覆盖了[3,4],那么线段1是否被完全覆盖掉了呢?
例子一是完全被覆盖掉了,而例子二没有被覆盖
为了解决这种缺陷,我们可以在排序后的数组上加些处理,比如说[1,2,6,10]
如果相邻数字间距大于1的话,在其中加上任意一个数字,比如加成[1,2,3,6,7,10],然后再做线段树就好了.
线段树功能:update:成段替换 query:简单hash
嗯,果然是我离散的姿势不对,用了150ms,慢一倍多。
--------------------------------------
#include<iostream>
#include<cstdio>
#include<cmath>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=222222;
struct Tree
{
int l;
int r;
int col;
} tree[N*4];
bool hash[N];
int it_x[N];
int it_y[N];
int a[N*4];
void push_up(int rt)
{
;
}
void push_down(int rt)
{
if (tree[rt].col>0)
{
tree[rt<<1].col=tree[rt<<1|1].col=tree[rt].col;
tree[rt].col=0;
}
}
void build(int root,int l,int r)
{
tree[root].l=l;
tree[root].r=r;
tree[root].col=0;
if(tree[root].l==tree[root].r)
{
return;
}
int mid=(l+r)/2;
build(root<<1,l,mid);
build(root<<1|1,mid+1,r);
push_up(root);
}
void update(int root,int L,int R,int val)
{
if(L<=tree[root].l&&R>=tree[root].r)
{
tree[root].col=val;
return;
}
push_down(root);
int mid=(tree[root].l+tree[root].r)/2;
if (L<=mid)
update(root<<1,L,R,val);
if (R>mid)
update(root<<1|1,L,R,val);
push_up(root);
}
void query(int root)
{
if (tree[root].col!=0)
{
hash[ tree[root].col ]=true;
return;
}
if (tree[root].l==tree[root].r) return;
query(root<<1);
query(root<<1|1);
}
int search(int key,int a[],int n)
{
int l=0,r=n-1;
while (l<=r)
{
int m=(l+r)/2;
if (a[m]==key) return m;
if (a[m]<key) l=m+1;
else r=m-1;
}
return -1;
}
int main()
{
int T,n,m,nn;
scanf("%d",&T);
while (T--)
{
memset(hash,0,sizeof(hash));
nn=0;
scanf("%d",&n);
for (int i=1;i<=n;i++)
{
scanf("%d%d",&it_x[i],&it_y[i]);
a[nn++]=it_x[i];
a[nn++]=it_y[i];
}
sort(a,a+nn);
m=1;
for (int i=1;i<nn;i++)
{
if (a[i]!=a[i-1]) a[m++]=a[i];
}
for (int i=m-1;i>0;i--)
{
if (a[i]!=a[i-1]+1) a[m++]=a[i-1]+1;
}
sort(a,a+m);
build(1,1,m);
for (int i=1;i<=n;i++)
{
int x=search(it_x[i],a,m)+1;
int y=search(it_y[i],a,m)+1;
update(1,x,y,i);
}
query(1);
int ans=0;
for (int i=1;i<=n;i++)
{
if (hash[i]) ans++;
}
printf("%d\n",ans);
}
return 0;
}
/*
#include<iostream>
#include<cstdio>
#include<cmath>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=222222;
int num[N];
struct Tree
{
int l;
int r;
int col;
} tree[N*4];
bool hash[N];
void push_up(int rt)
{
;
}
void push_down(int rt)
{
if (tree[rt].col>0)
{
tree[rt<<1].col=tree[rt<<1|1].col=tree[rt].col;
tree[rt].col=0;
}
}
void build(int root,int l,int r)
{
tree[root].l=l;
tree[root].r=r;
tree[root].col=0;
if(tree[root].l==tree[root].r)
{
return;
}
int mid=(l+r)/2;
build(root<<1,l,mid);
build(root<<1|1,mid+1,r);
push_up(root);
}
void update(int root,int L,int R,int val)
{
if(L<=tree[root].l&&R>=tree[root].r)
{
tree[root].col=val;
return;
}
push_down(root);
int mid=(tree[root].l+tree[root].r)/2;
if (L<=mid)
update(root<<1,L,R,val);
if (R>mid)
update(root<<1|1,L,R,val);
push_up(root);
}
void query(int root)
{
if (tree[root].col!=0)
{
hash[ tree[root].col ]=true;
return;
}
if (tree[root].l==tree[root].r) return;
query(root<<1);
query(root<<1|1);
}
struct DATA{
int id;
int fd;
int d;
bool x;
}a[N];
int it_x[N];
int it_y[N];
bool cmp1(DATA a,DATA b)
{
if (a.fd^b.fd) return a.fd<b.fd;
return !a.x;
}
bool cmp2(DATA a,DATA b)
{
if (a.id^b.id) return a.id<b.id;
return a.x;
}
int main()
{
int T,c,n,m,cnt;
scanf("%d",&T);
while (T--)
{
memset(hash,0,sizeof(hash));
m=0;
c=0;
scanf("%d",&n);
for (int i=1;i<=n;i++)
{
scanf("%d%d",&it_x[i],&it_y[i]);
a[m].id=i;
a[m].fd=it_x[i];
a[m].x=true;
m++;
a[m].id=i;
a[m].fd=it_y[i];
a[m].x=false;
m++;
}
sort(a,a+m,cmp1);
cnt=1;
for (int i=0;i<m;i++)
{
a[i].d=cnt;
c=max(c,a[i].d);
if (a[i].fd!=a[i+1].fd) cnt+=2;
if (a[i].fd+1==a[i+1].fd) cnt-=1;
}
sort(a,a+m,cmp2);
for (int i=1;i<=c;i++)
{
num[i]=0;
}
build(1,1,c);
for (int i=0;i<m;i+=2)
{
int x=a[i].d;
int y=a[i+1].d;
int id=a[i].id;
update(1,x,y,id);
}
query(1);
int ans=0;
for (int i=1;i<=c;i++)
{
if (hash[i]) ans++;
}
printf("%d\n",ans);
}
return 0;
}
*/