二分图的基本概念
一个无向图G=<V, E>,如果存在两个集合X、Y,使得X∪Y=V, X∩Y=Φ,并且每一条边e={x,y}有x∈X,y∈Y,则称G为一个二分图(bipartite graph)。常用<X, E, Y>来表示一个二分图。若对X中任一x及Y中任一y恰有一边e∈E,使e = {x, y}, 则称G为完全二分图(complete bipartite graph)。当|X| = m,|Y| = n时,完全二分图G记为Km,n。
二分图的性质:
定理:无向图G为二分图的充分必要条件是,G至少有两个顶点,且其所有回路的长度均为偶数。
匹配:设G=<V, E>为二分图,如果ME,并且M中没有任何两边有公共端点。M=Φ时称M为空匹配。
最大匹配:G的所有匹配中边数最多的匹配称为最大匹配。
完全匹配:若X(Y)中所有的顶点都是匹配M中的端点。则成M为完全匹配。若M既是X-完全匹配又是Y-完全匹配,则称M为G的完全匹配。
注意:最大匹配总是存在但未必唯一;X(Y)-完全匹配及G的完全匹配必定是最大的,但反之则不然;X(Y)-完全匹配未必存在。
下面引入几个术语:
设G=<V, E>为二分图,M为G的一个匹配。
- M中边的端点称为M-顶点,其它顶点称为非M-顶点。
- 增广路径:除了起点和终点两个顶点为非M-顶点,其他路径上所有的点都是M=顶点。而且它的边为匹配边、非匹配边交替出现。
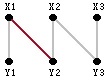

图1图2 如上图中图1,就是一个二分图的匹配:[X1, Y2]。图2就是在这个匹配的基础上的两个增广路径:X2→Y2→X1→Y1和X3→Y3。
我们来验证一下:增广路径 X2→Y2→X1→Y1中,起止点X2、Y1为非M-顶点。而中间点Y2、X1都是M-顶点。
边{X2, Y2}, {X1, Y1}为非匹配边,而边{Y2, X1}为匹配边,满足匹配边与非匹配边交替出现。
同理X3→Y3路径也满足增广路径的要求。借助这幅图,来描述一下增广路径的性质。
- 有奇数条边。
- 起点在二分图的左半边,终点在右半边。
- 路径上的点一定是一个在左半边,一个在右半边,交替出现。(其实二分图的性质就决定了这一点,因为二分图同一边的点之间没有边相连,不要忘记哦。)
- 整条路径上没有重复的点。
- 起点和终点都是目前还没有配对的点,而其它所有点都是已经配好对的。
- 路径上的所有第奇数条边都不在原匹配中,所有第偶数条边都出现在原匹配中。
- 最后,也是最重要的一条,把增广路径上的所有第奇数条边加入到原匹配中去,并把增广路径中的所有第偶数条边从原匹配中删除(这个操作称为增广路径的取反),则新的匹配数就比原匹配数增加了1个。
又∵第一条是非匹配边 且 匹配边与非匹配边交替出现
∴非匹配边有K+1条,匹配边有K条。
非匹配边比匹配边多了1条。
此时,我们做取反操作(匹配边变成非匹配边,非匹配边变成匹配边),则匹配边的个数就会在原来的基础上增加1条。
求最大匹配的“匈牙利算法”就是这样做的。
无论从哪个匹配开始(整个程序的初始状态是从空匹配开始),每次操作都让匹配数增加1条,不断使它得到扩充,直到找不到增广路径。
这样就得到了最大匹配了。对增广路径,还有一种递归的定义,可能不大准确,但揭示了一种寻找增广路径的一般方法:
从集合X中的一个非M-顶点A出发,通过与A关联的边到达集合Y中的端点B, 如果B在M中没有任何边匹配,则B就是该增广路径的终点; 如果B已经与C点配对,则这条增广路径就是从A→B→C并加上“从C点出发的增广路径”。 并且这条增广路径中不能有重复的点出现。
比如我们要从上图中找出一条从X3点出发的增广路径,我们需要做以下几步。
- 首先从X3出发,它能连接到的点只有点Y3,而Y3已经与X2配对,所以现在的增广路径是X3→Y3→X2在加上从点X2出发的增广路径。
- 点X2能连接到Y2,Y3,但Y3与前面的路径重复,而{X2, Y2}这条边也不在原来的匹配中,所以只能连接到Y2。所以现在的增广路径是X3→Y3→X2→Y2→X1在加上从点X1出发的增广路径。
- 点X1能连接到的点且不前面路径重复的点只有Y1。并且Y1在原先的匹配中不与其他所有点配对,属于非M-顶点。因此Y1是该增广路径的终点。所以最终的增广路径是X3→Y3→X2→Y2→X1→Y1。
严格意义上讲,上面提到的从X2出发的增广路径X2→Y2→X1→Y1和从点X1出发的增广路径X1→Y1并不是真正意义上的增广路径,它们不符合第5个性质。它们的起点是已配对的点。 这里说它们是增广路径只是为了简化搜索过程,它们都只是中间返回值而已。



现在就进入我们的正题:用匈牙利算法求最大匹配。
匈牙利算法的基本模式是:
初始时最大匹配为空
while 找得到增广路径
do 把增广路径加入到最大匹配中去
比如我们寻找图1的最大匹配,过程可能如下:
- 初始最大匹配为空。
- 找到增广路径X1→Y2,把它取反,则匹配数增大到1,最大匹配变成[X1, Y2]。
- 找到增广路径X2→Y3,把它取反,则匹配数增大到2,最大匹配变成[X1, Y2],[X2, Y3]。
- 找到增广路径X3→Y3→X2→Y2→X1→Y1,把它取反,则匹配数增大到3,最大匹配变成[X1, Y1],[X2, Y2],[X3, Y3]。
- 找不出增广路径,程序结束,得到最大匹配数为3。
从上面的描述可以看出,搜索增广路径的方法是DFS,写一个递归的函数。当然也可以用BFS。
至此,理论基础部份讲完了。但是要完成匈牙利算法,还需要一个重要的定理:
如果从一个点A出发,没有找到增广路径,那么无论再从别的点出发找到多少增广路径来改变现在的匹配,从A出发都永远找不到增广路径。
有了这个定理,匈牙利算法就成形了。如下:
初始时最大匹配为空
for 二分图左半边的每个点i
do 从点i出发寻找增广路径。如果找到,则把它取反(即增加了总了匹配数)。如果二分图的左半边一共有n个点,那么最多找n条增广路径。如果图中共有m条边,那么每找一条增广路径(DFS或BFS)时最多把所有边遍历一遍,所花时间也就是m。所以总的时间大概就是O(n * m)。
#include <iostream>
#include <cstring>
#include <cstdio>
#include <vector>
#include <stack>
#define SIZE 300
using namespace std;
void solve();
bool dfs(int x);
vector<int>list[SIZE];
stack<int>stk;
int size_x,size_y;
bool visit[SIZE];
int X[SIZE];
int Y[SIZE];
bool dfs(int x)
{
vector<int>::iterator it;
stk.push(x);
for ( it=list[x].begin();it<list[x].end();it++ )
{
if ( !visit[ *it ] )
{
visit[ *it ]=true;
stk.push( *it );
if ( Y[ *it ]==0 || dfs( Y[ *it ] ) )
{
return true;
}
else
{
stk.pop();
}
}
}
stk.pop();
return false;
}
void solve()
{
int top;
for (int i=1;i<=size_x;i++)
{
while (!stk.empty()) stk.pop();
memset(visit,false,sizeof(visit));
if ( dfs(i) )
{
while ( !stk.empty() )
{
top=stk.top();
stk.pop();
Y[top]=stk.top();
X[stk.top()]=top;
stk.pop();
}
}
}
}--------------------------------------
另一种写法
#include <iostream>
#include <cstring>
using namespace std;
int a[600][600];
bool v[600];
int d[600];
int n,K;
bool dfs(int p)
{
int t;
for (int i=1;i<=n;i++)
{
if (a[i][p]&&!v[i])
{
v[i]=true;
t=d[i];
d[i]=p;
if (t==0||dfs(t))
{
return true;
}
d[i]=t;
}
}
return false;
}
int main()
{
int ans,x,y;
while (cin>>n>>K)
{
memset(a,0,sizeof(a));
memset(d,0,sizeof(d));
ans=0;
for (int i=1;i<=K;i++)
{
cin>>x>>y;
a[x][y]=1;
}
for (int i=1;i<=n;i++)
{
memset(v,0,sizeof(v));
if (dfs(i))
{
ans++;
}
}
cout<<ans<<endl;
}
return 0;
}