sharding jdbc: sharding sphere 的 一部分,可以做到 分表分库,读写分离。
和 mycat 不同的 是 sharding jdbc 是 一个 jdbc 驱动 在 驱动这个层做的 分表,分库,读写分离。 mycat 是 一个数据库 中间件,或者就是一个数据库代理工具。
对比图:
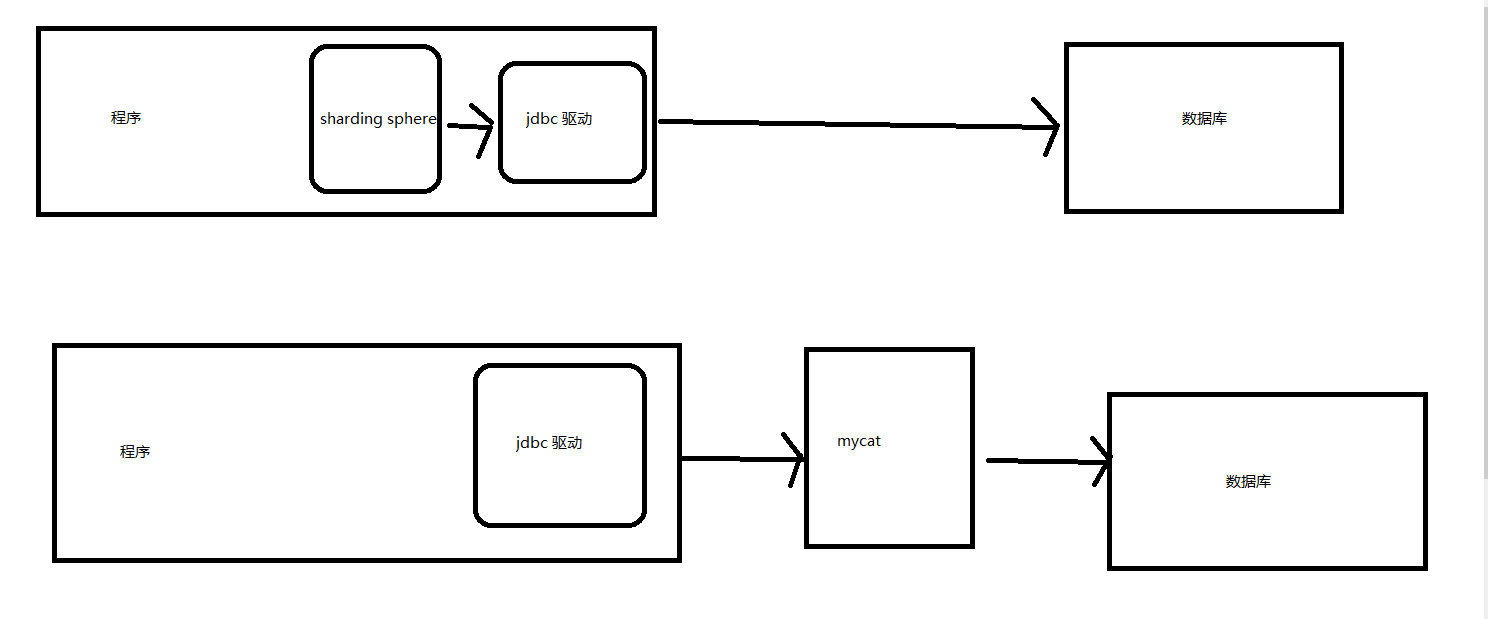
1 sharding shpere 不做 主从图同步数据一致性的的保证,也就是说,必然会遇到主写入,然后如果在从库上读取数据是读取不到的。
在这种情况应该去读主库,入股欧式事物环境写入数据以后,就会自动切换到 materonly 模式,只用主库。
2 关于sharding sphere主从路由的选着:
文档里面说过一句话,如果同一个线程有修改操作,那么后面都读的主库。
实际并不会这样。如果是非事务环境还是读的从库。如果是事务环境会强制读主库。
3 强制使用主库
HintManager hintManager =HintManager.getInstance();
hintManager.setMasterRouteOnly();
强制主库,在非事务环境也生效
使用和配置:
1 引入 包

2 配置 yml 文件
数据分片:
dataSources: ds0: !!org.apache.commons.dbcp.BasicDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/ds0 username: root password: ds1: !!org.apache.commons.dbcp.BasicDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/ds1 username: root password: shardingRule: tables: t_order: actualDataNodes: ds${0..1}.t_order${0..1} databaseStrategy: inline: shardingColumn: user_id algorithmInlineExpression: ds${user_id % 2} tableStrategy: inline: shardingColumn: order_id algorithmInlineExpression: t_order${order_id % 2} t_order_item: actualDataNodes: ds${0..1}.t_order_item${0..1} databaseStrategy: inline: shardingColumn: user_id algorithmInlineExpression: ds${user_id % 2} tableStrategy: inline: shardingColumn: order_id algorithmInlineExpression: t_order_item${order_id % 2}
读写分离:
dataSources: ds_master: !!org.apache.commons.dbcp.BasicDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/ds_master username: root password: ds_slave0: !!org.apache.commons.dbcp.BasicDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/ds_slave0 username: root password: ds_slave1: !!org.apache.commons.dbcp.BasicDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/ds_slave1 username: root password: masterSlaveRule: name: ds_ms masterDataSourceName: ds_master slaveDataSourceNames: [ds_slave0, ds_slave1] props: sql.show: true
3 然后正常的写程序就是,注意使用的 是主还是从数据库。