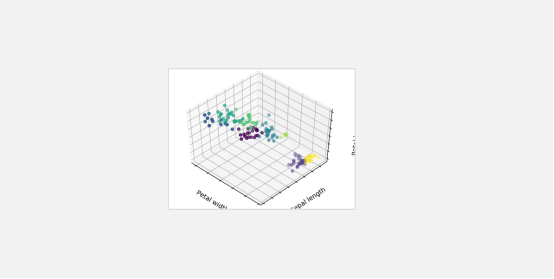
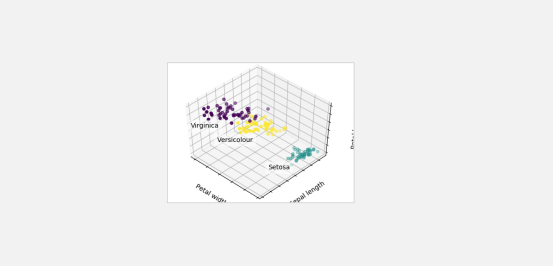
参考地址:https://blog.csdn.net/weixin_30607659/article/details/95010173
实验记录,方便以后查阅
一丶实现代码
import numpy as np #绘图的工具 类似MATLAB import matplotlib.pyplot as plt #Matplotlib里面专门用来画三维图的工具包 from mpl_toolkits.mplot3d import Axes3D from sklearn.cluster import KMeans #函数库 主要由分类,回归,聚类,降维 四类函数方法组成 from sklearn import datasets #随机数 np.random.seed(5) #KMeans在sklearn.cluster的包里面,在sklearn里面都是使用fit函数进行聚类 centers = [[1, 1], [-1, -1], [1, -1]] #加载数据集 共150行 前四列为花萼长度,花萼宽度,花瓣长度,花瓣宽度等4个用于识别鸢尾花的属性,第5列为鸢尾花的类别(包括Setosa,Versicolour,Virginica三类) iris = datasets.load_iris() #data对应了样本的4个特征,150行4列 X = iris.data #print(X.shape) #target对应了样本的类别(目标属性),150行1列 y = iris.target #print(y.shape) #K-Means方法 #n_clusters : 聚类的个数k init : 初始化的方式 n_init : 运行k-means的次数,最后取效果最好的一次 estimators = {'k_means_iris_3': KMeans(n_clusters=3), 'k_means_iris_8': KMeans(n_clusters=8), 'k_means_iris_bad_init': KMeans(n_clusters=3, n_init=1, init='random')} #在sklearn中基本所有的模型的建模的函数都是fit,预测的函数都是predict fignum = 1 for name, est in estimators.items(): fig = plt.figure(fignum, figsize=(4, 3)) plt.clf() ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134) plt.cla() # fit建立模型 est.fit(X) # 获得模型聚类后的label labels = est.labels_ # 绘制X中的第3,0,2个维度的特征 ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=labels.astype(np.float)) ax.w_xaxis.set_ticklabels([]) ax.w_yaxis.set_ticklabels([]) ax.w_zaxis.set_ticklabels([]) # 设置坐标轴名 ax.set_xlabel('Petal width') ax.set_ylabel('Sepal length') ax.set_zlabel('Petal length') fignum = fignum + 1 # Plot the ground truth # 绘制结果 fig = plt.figure(fignum, figsize=(4, 3)) plt.clf() #设置坐标 ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134) plt.cla() for name, label in [('Setosa', 0), ('Versicolour', 1), ('Virginica', 2)]: ax.text3D(X[y == label, 3].mean(), X[y == label, 0].mean() + 1.5, X[y == label, 2].mean(), name, horizontalalignment='center', bbox=dict(alpha=.5, edgecolor='w', facecolor='w')) # Reorder the labels to have colors matching the cluster results #重新排序标签以使颜色与聚类结果匹配 y = np.choose(y, [1, 2, 0]).astype(np.float) ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=y) ax.w_xaxis.set_ticklabels([]) ax.w_yaxis.set_ticklabels([]) ax.w_zaxis.set_ticklabels([]) #设置坐标轴名 ax.set_xlabel('Petal width') ax.set_ylabel('Sepal length') ax.set_zlabel('Petal length') #绘制整张图 plt.show()
二丶测试结果