13. 线程池
第四种获取线程的方法:线程池,一个 ExecutorService,它使用可能的几个池线程之一执行每个提交的任务,通常使用 Executors 工厂方法配置。
线程池可以解决两个不同问题:由于减少了每个任务调用的开销,它们通常可以在执行大量异步任务时提供增强的性能,并且还可以提供绑定和管理资源(包括执行任务集时使用的线程)的方法。每个 ThreadPoolExecutor 还维护着一些基本的统计数据,如完成的任务数。
为了便于跨大量上下文使用,此类提供了很多可调整的参数和扩展钩子 (hook)。但是,强烈建议程序员使用较为方便的 Executors 工厂方法 :
- Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)
- Executors.newFixedThreadPool(int)(固定大小线程池)
- Executors.newSingleThreadExecutor()(单个后台线程)
它们均为大多数使用场景预定义了设置。
创建包含5个线程的线程池,对变量进行增加操作

/*
* 一、线程池:提供了一个线程队列,队列中保存着所有等待状态的线程。避免了创建与销毁额外开销,提高了响应的速度。
*
* 二、线程池的体系结构:
* java.util.concurrent.Executor : 负责线程的使用与调度的根接口
* |--**ExecutorService 子接口: 线程池的主要接口
* |--ThreadPoolExecutor 线程池的实现类
* |--ScheduledExecutorService 子接口:负责线程的调度
* |--ScheduledThreadPoolExecutor :继承 ThreadPoolExecutor, 实现 ScheduledExecutorService
*
* 三、工具类 : Executors
* ExecutorService newFixedThreadPool() : 创建固定大小的线程池
* ExecutorService newCachedThreadPool() : 缓存线程池,线程池的数量不固定,可以根据需求自动的更改数量。
* ExecutorService newSingleThreadExecutor() : 创建单个线程池。线程池中只有一个线程
*
* ScheduledExecutorService newScheduledThreadPool() : 创建固定大小的线程,可以延迟或定时的执行任务。
*/
public class TestThreadPool {
public static void main(String[] args) throws Exception {
//1. 创建线程池
ExecutorService pool = Executors.newFixedThreadPool(5);
ThreadPoolDemo tpd = new ThreadPoolDemo();
//2. 为线程池中的线程分配任务,>5,可将线程池里的五个线程都给调用
for (int i = 0; i < 10; i++) {
pool.submit(tpd);
}
//3. 关闭线程池
pool.shutdown();
}
// new Thread(tpd).start();
// new Thread(tpd).start();
}
class ThreadPoolDemo implements Runnable{
private int i = 0;
@Override
public void run() {
while(i <= 100){
System.out.println(Thread.currentThread().getName() + " : " + i++);
}
}
}
线程池结合Callable和Future创建线程
public static void main(String[] args) throws Exception {
//1. 创建线程池
ExecutorService pool = Executors.newFixedThreadPool(5);
List<Future<Integer>> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
//Future对象用于接收Callable线程的返回值
Future<Integer> future = pool.submit(new Callable<Integer>(){
//线程调用方法,查询1-100之和
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i <= 100; i++) {
sum += i;
}
return sum;
}
});
list.add(future);
}
//关闭线程池
pool.shutdown();
//遍历结果集,会输出10次5050
for (Future<Integer> future : list) {
System.out.println(future.get());
}
}
14. 线程调度
接口ScheduledExecutorService 继承自 ExecutorService接口,由ScheduledThreadPoolExecutor类(ThreadPoolExecutor类的子类)实现,可安排在给定的延迟后运行或定期执行的命令。
ScheduledExecutorService newScheduledThreadPool() : 创建固定大小的线程,可以延迟或定时的执行任务。
参考java.util.concurrent.ScheduledThreadPoolExecutor.class中schedule方法源码
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable,
triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
示例:
public class TestScheduledThreadPool {
public static void main(String[] args) throws Exception {
//创建ScheduledExecutorService类型的线程池对象
ScheduledExecutorService pool = Executors.newScheduledThreadPool(5);
for (int i = 0; i < 5; i++) {
Future<Integer> result = pool.schedule(new Callable<Integer>(){
@Override
public Integer call() throws Exception {
int num = new Random().nextInt(100);//生成随机数
System.out.println(Thread.currentThread().getName() + " : " + num);
return num;
}
}, 1, TimeUnit.SECONDS);
System.out.println(result.get());
}
//线程池关闭
pool.shutdown();
}
}
15. ForkJoinPool 分支合并框架-工作窃取
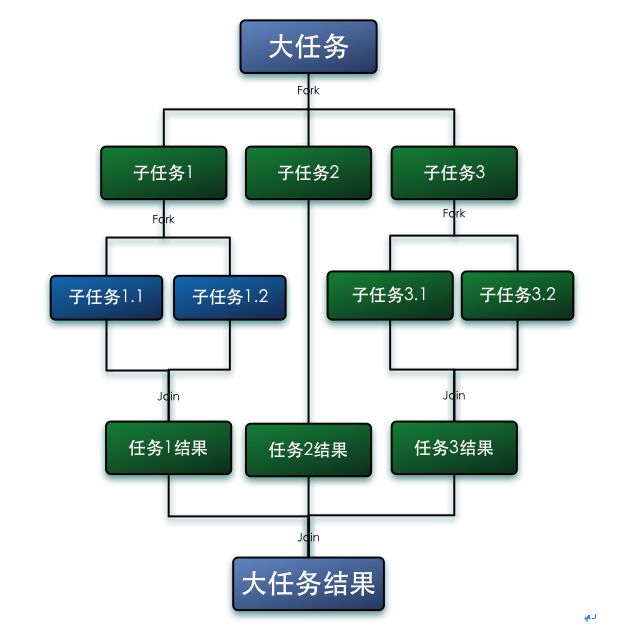
Fork/Join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行 join 汇总。
/* @since 1.7
* @author Doug Lea
*/
public abstract class ForkJoinTask<V> implements Future<V>, Serializable {
...
}
- 采用 “工作窃取”模式(work-stealing):当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
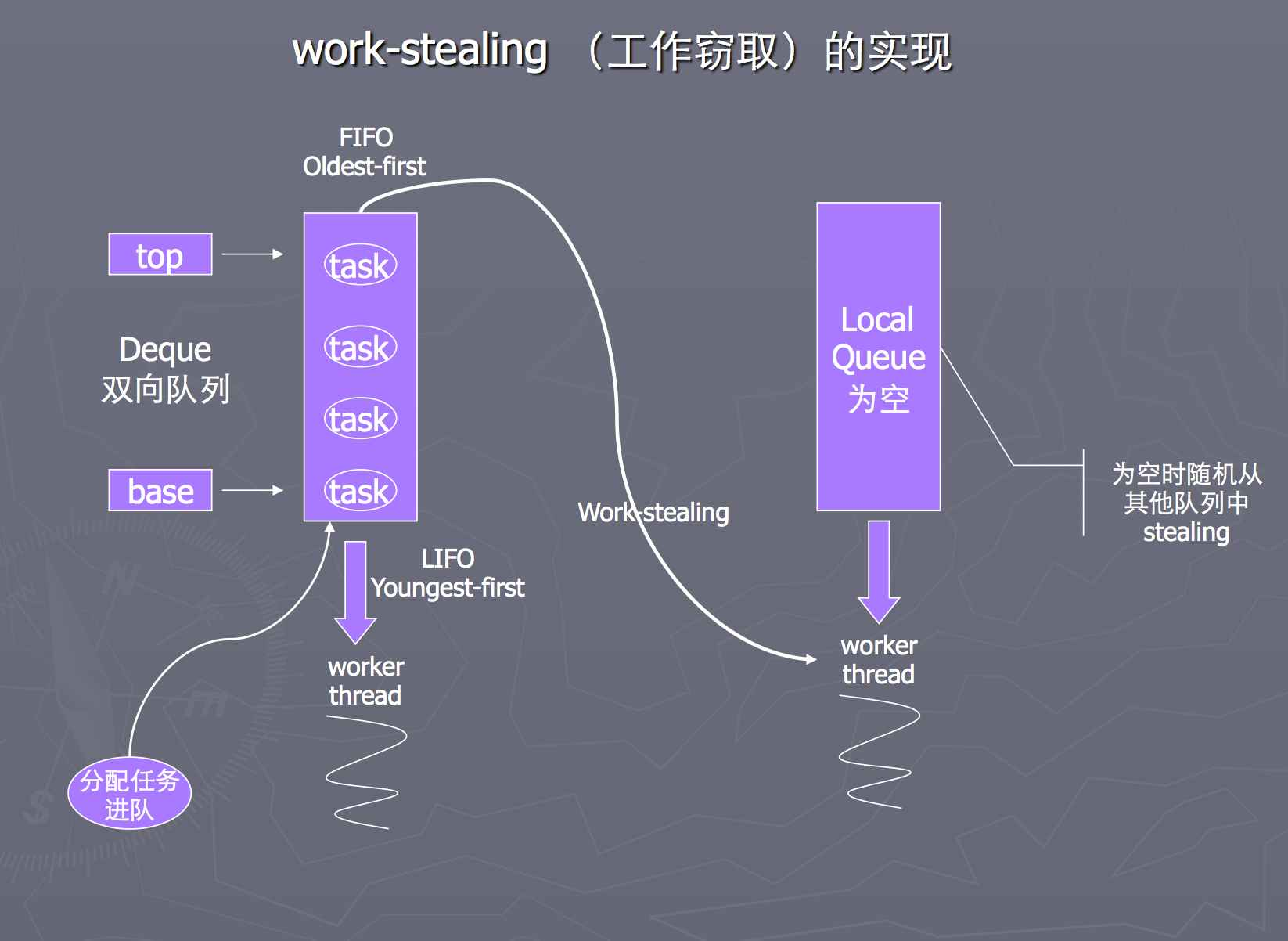
- 相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态。而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行。那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能。
jdk1.7之后提供了两个Fork/Join 框架,两个框架最大区别为是否有返回值
//有返回值
public abstract class RecursiveTask<V> extends ForkJoinTask<V> {}
//无返回值
public abstract class RecursiveAction extends ForkJoinTask<Void> {}
下面为一实现示例(求两数之间所有数之和,如1-100——>5050):
class ForkJoinSumCalculate extends RecursiveTask<Long>{
private static final long serialVersionUID = -1812835340478767238L;
private long start;
private long end;
private static final long THURSHOLD = 10000L; //临界值
public ForkJoinSumCalculate(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
//小于临界值,则不进行拆分,直接计算初始值到结束值之间所有数之和
if(length <= THURSHOLD){
long sum = 0L;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else{ //大于临界值,取中间值进行拆分,递归调用
long middle = (start + end) / 2;
ForkJoinSumCalculate left = new ForkJoinSumCalculate(start, middle);
left.fork(); //进行拆分,同时压入线程队列
ForkJoinSumCalculate right = new ForkJoinSumCalculate(middle+1, end);
right.fork(); //
return left.join() + right.join();
}
}
}
测试1-50000000000的和:
public static void main(String[] args) {
Instant start = Instant.now();
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinSumCalculate(0L, 50000000000L);
Long sum = pool.invoke(task);
System.out.println(sum);
Instant end = Instant.now();
System.out.println("耗费时间为:" + Duration.between(start, end).toMillis());
}
结果:cpu利用率达到100%,耗时19.361s

和for循环累加比较一下:
@Test
public void test1(){
Instant start = Instant.now();
long sum = 0L;
for (long i = 0L; i <= 50000000000L; i++) {
sum += i;
}
System.out.println(sum);
Instant end = Instant.now();
System.out.println("耗费时间为:" + Duration.between(start, end).toMillis());//35-3142-15704
}
结果如下:耗时18.699s

由于fork/join框架在复杂逻辑时不易拆分,java8为fork/join进行了改进,代码如下:
//java8 新特性
@Test
public void test2(){
Instant start = Instant.now();
Long sum = LongStream.rangeClosed(0L, 50000000000L)
.parallel()
.reduce(0L, Long::sum);
System.out.println(sum);
Instant end = Instant.now();
System.out.println("耗费时间为:" + Duration.between(start, end).toMillis());//1536-8118
}
结果:耗时15.428s

测试了几个值,发现效率方面: java8 > for循环 > fork/join
| 10000000000L |
50000000000L |
100000000000L | |
| java8 | 3320ms | 15428ms | 34770ms |
| for | 3902ms | 18699ms | 37858ms |
| fork/join | 4236ms | 19361ms | 40977ms |
按理来说,随着计算量的增大,fork/join的效率会超过for循环,但是在本机测试出的结果如上,fork/join框架的效率始终不如贴近底层的for循环。这方面可能一方面在于compute方法设计中long类型的装箱拆箱存在一定时间开销,另一方面可能由于临界值选择不合理,测试时选择10000,在测试10000000000L累加时,采取四个临界值:5000、10000、20000、100000,结果还是临界值为10000时效率最高。还是相信眼见为实吧。