import re
from collections import Counter
txt = open('readme.txt',mode='r').read()#读取文件
list1 = re.split('W+',txt)#以不是英文字母来区分单词
out1 = Counter(list1)#统计词频
print('词频统计结果:',out1)
print('出现频率最高的前十个单词:',out1.most_common(10))
输出:
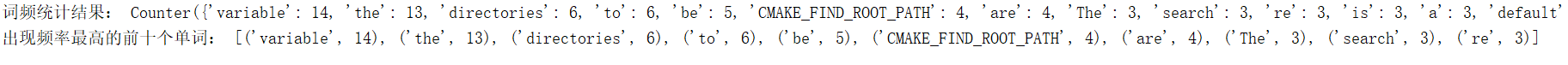
import re
from collections import Counter
txt = open('readme.txt',mode='r').read()#读取文件
list1 = re.split('W+',txt)#以不是英文字母来区分单词
out1 = Counter(list1)#统计词频
print('词频统计结果:',out1)
print('出现频率最高的前十个单词:',out1.most_common(10))
输出: