理论要点
什么是数据局部性模式:合理组织数据,充分使用CPU的缓存来加速内存读取。简单点说就是让数据在内存中连续存储,这样可以加快CPU的访问速度。
要点
1, 现代的CPU有缓存来加速内存读取,其可以更快地读取最近访问过的内存毗邻的内存。基于这一点,我们通过保证处理的数据排列在连续内存上,以提高内存局部性,从而提高性能。2,为了保证数据局部性,就要避免的缓存不命中。也许你需要牺牲一些宝贵的抽象。你越围绕数据局部性设计程序,就越放弃继承、接口和它们带来的好处。这里并没有高招,只有利弊权衡的挑战。而乐趣便在这里。
3,程序指令执行类似这样一个结构:CPU–Cache(L1缓存)–RAM(内存),从这里可以看出,影响性能的不单单只是代码,由于缓存的存在,数据的组织方式也会直接影响性能。我们的优化策略无非就是要尽量保证CPU要的数据刚好在缓存中,减少缓存未命中次数,因此优化目标就是将你的数据结构进行组织,以使需要处理的数据对象在内存中连续存储。
使用场合
1,使用数据局部性的第一准则是在遇到性能问题时使用。不要将其应用在代码库不经常使用的角落上。 优化代码后其结果往往更加复杂,更加缺乏灵活性。2,就本模式而言,还得确认你的性能问题确实由缓存不命中而引发的。如果代码是因为其他原因而缓慢,这个模式自然就不会有帮助。
3,简单的性能评估方法是手动添加指令,用计时器检查代码中两点间消耗的时间。而为了找到糟糕的缓存使用情况,知道缓存不命中有多少发生,又是在哪里发生的,则需要使用更加复杂的工具—— profilers。
4,组件模式是为缓存优化的最常见例子。而任何需要接触很多数据的关键代码,考虑数据局部性都是很重要的。
代码分析
1,数据局部性模式一般是运用在性能攸关的地方,那么首先分析的示例当然是我们的游戏主循环处。游戏世界里有很多实体,它们通常可以由AI,物理,渲染等组件组成。我们一般的做法像下面这样定义:
class GameEntity
{
public:
GameEntity(AIComponent* ai,
PhysicsComponent* physics,
RenderComponent* render)
: ai_(ai), physics_(physics), render_(render)
{}
AIComponent* ai() { return ai_; }
PhysicsComponent* physics() { return physics_; }
RenderComponent* render() { return render_; }
private:
AIComponent* ai_;
PhysicsComponent* physics_;
RenderComponent* render_;
};而且每个组件都有自己的更新接口:
class AIComponent
{
public:
void update() { /* 处理并修改状态…… */ }
private:
// 目标,情绪,等等……
};
class PhysicsComponent
{
public:
void update() { /* 处理并修改状态…… */ }
private:
// 刚体,速度,质量,等等……
};
class RenderComponent
{
public:
void render() { /* 处理并修改状态…… */ }
private:
// 网格,纹理,着色器,等等……
};游戏循环管理游戏世界中一大堆实体的指针数组。每个游戏循环,我们都要做如下事情:
为每个实体更新他们的AI组件。
为每个实体更新他们的物理组件。
为每个实体更新他们的渲染组件。
很多游戏引擎以这种方式实现:
while (!gameOver)
{
// 处理AI
for (int i = 0; i < numEntities; i++)
{
entities[i]->ai()->update();
}
// 更新物理
for (int i = 0; i < numEntities; i++)
{
entities[i]->physics()->update();
}
// 绘制屏幕
for (int i = 0; i < numEntities; i++)
{
entities[i]->render()->render();
}
// 其他和时间有关的游戏循环机制……
}好,现在我们来分析下这个代码,在你听说CPU缓存之前,这些看上去完全无害。 但是现在,对象内存分布完全不可控,都是指针到处窜。看看它做了什么:
游戏实体的数组存储的是指针,所以为了获取游戏实体,我们得转换指针。缓存不命中。
然后游戏实体有组件的指针。又一次缓存不命中。
然后我们更新组件。
再然后我们退回第一步,为游戏中的每个实体做这件事。
令人害怕的是,我们不知道这些对象是如何在内存中布局的。 我们完全任由内存管理器摆布。 随着实体的分配和释放,堆会组织更加乱。
它就像下面这个示意图这样,对象分布得杂乱无章:
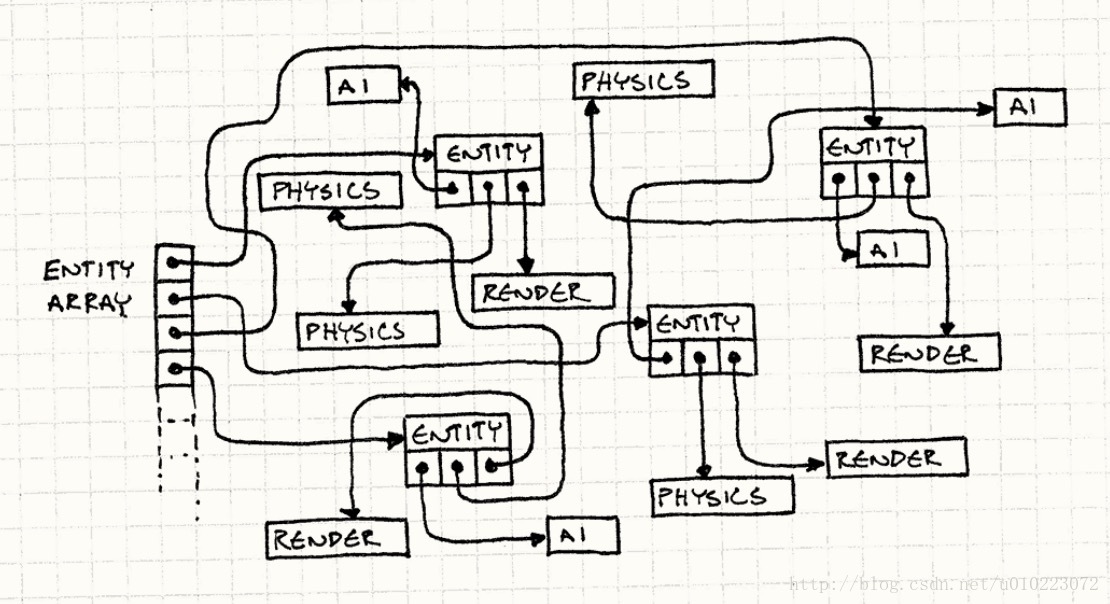
既然已经知道问题是由指针导致很多缓存不命中引起,那么直接能想到的就是使用数组的形式。其实这里GameEntity本身没有有意义的状态和有用的方法。组件才是游戏循环需要的。我们可以将每种组件存入巨大的数组:一个数组给AI组件,一个给物理,另一个给渲染。
就像这样:
AIComponent* aiComponents =
new AIComponent[MAX_ENTITIES];
PhysicsComponent* physicsComponents =
new PhysicsComponent[MAX_ENTITIES];
RenderComponent* renderComponents =
new RenderComponent[MAX_ENTITIES];再来看看我们现在的游戏循环:
while (!gameOver)
{
// 处理AI
for (int i = 0; i < numEntities; i++)
{
aiComponents[i].update();
}
// 更新物理
for (int i = 0; i < numEntities; i++)
{
physicsComponents[i].update();
}
// 绘制屏幕
for (int i = 0; i < numEntities; i++)
{
renderComponents[i].render();
}
// 其他和时间有关的游戏循环机制……
}对象数组在内存中是连续存储的,我们消除了所有的指针追逐。不在内存中跳来跳去,而是直接在三个数组中做直线遍历。就像这样:
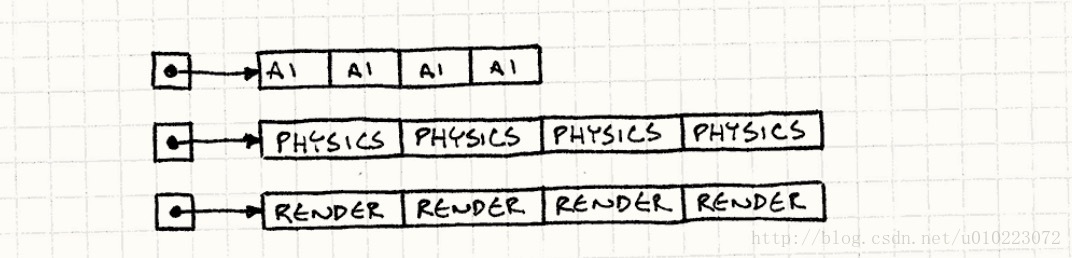
这将一股字节流直接泵到了CPU饥饿的肚子里。 在我的测试中,这个改写后的更新循环是之前性能的50倍。
2,再来看看另一个例子,假设我们在做粒子系统。 根据上节的建议,将所有的粒子放在巨大的连续数组中。让我们用管理类封装它,就像这样:
class Particle
{
public:
void update() { /* 重力,等等…… */ }
// 位置,速度,等等……
};
class ParticleSystem
{
public:
ParticleSystem()
: numParticles_(0)
{}
void update();
private:
static const int MAX_PARTICLES = 100000;
int numParticles_;
Particle particles_[MAX_PARTICLES];
};那么更新粒子就会是这样:
void ParticleSystem::update()
{
for (int i = 0; i < numParticles_; i++)
{
particles_[i].update();
}
}但实际上不需要同时更新所有的粒子。 粒子系统维护固定大小的对象池,而且粒子通常不是同时在屏幕上活跃。 最简单的解决方案是这样的,加一个标志:
for (int i = 0; i < numParticles_; i++)
{
if (particles_[i].isActive())
{
particles_[i].update();
}
}我们给Particle一个标志位来追踪其是否在使用状态。 在更新循环时,我们检查每个粒子的这个标志位。 这会将粒子其他部分的数据也加载到缓存中。 如果粒子没有在使用,那么跳过它去检查下一个。 这时粒子加载到内存中的其他数据都是浪费。
活跃的粒子越少,要在内存中跳过的部分就越多。 越这样做,在两次活跃粒子有效更新之间发生的缓存不命中就越多。 如果数组很大又有很多不活跃的粒子,我们又在颠簸缓存了。
如果连续数组中的对象不是连续处理的,实际上这个办法也没有太多效果。 如果有太多不活跃的对象需要跳过,就又回到了问题的起点。
其实这个很容易解决,我们可以不检测isActive,把数组进行排序,活跃的放数组前面,如果这样循环就可以变成下面这样了:
for (int i = 0; i < numActive_; i++)
{
particles[i].update();
}现在没有跳过任何数据。 加载入缓存的每一字节都是需要处理的粒子的一部分。
只是这个排序应该怎么写呢?
很简单,只有两种状态:激活与未激活,开始所有粒子都处于未激活状态,当哪个粒子激活时,我们让它与数组中第一个未激活的粒子进行交换。同样,当粒子死亡时,我们让它与最后一个激活粒子交换。每次状态改变只是一次交换操作,我们就能把数组排好序。
激活粒子接口:
void ParticleSystem::activateParticle(int index)
{
// 不应该已被激活!
assert(index >= numActive_);
// 将它和第一个未激活的粒子交换
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
// 现在多了一个激活粒子
numActive_++;
}死亡粒子接口:
void ParticleSystem::deactivateParticle(int index)
{
// 不应该已被激活!
assert(index < numActive_);
// 现在少了一个激活粒子
numActive_--;
// 将它和最后一个激活粒子交换
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
}很多程序员(包括我在内)已经对于在内存中移动数据过敏了。然而解析指针的代价,往往比内存中移动数据消耗更大。 在有些情况下,如果能够保证缓存命中,在内存中移动数据消耗更小。
不过也有弊端。 你可以从API看出,我们放弃了一定的面向对象思想。 Particle类不再控制其激活状态了。 你不能在它上面调用activate(),因为它不知道自己的索引。 相反,任何想要激活粒子的代码都需要接触到粒子系统。
3,我们已经讲了两种不命中情形了:一,指针导致的不命中,二,连续数组中的对象不是连续处理的不命中。而下面我们来讲最后一种情形:连续数组中的对象里有很多不需要马上使用的数据导致白占缓存线。
就像一个游戏实体,它有很多状态,如:走向目标位置,能量值,当前播放的动画等,总之这些我们每帧都在检测。然而它也存在一些不需要每帧检测的数据,如死亡掉落数据。这个就只有在实体生命周期结束时才被使用。
下面是这个的简单实现:
class AIComponent
{
public:
void update() { /* ... */ }
private:
Animation* animation_;
double energy_;
Vector goalPos_;
//掉落数据
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};是不是很明显,把整个对象加载进缓存,然而很多数据又是当前不需要使用的。这样每个对象变得更庞大,也就导致我们在一条缓存线上能放入的对象更少。我们将引发更多的缓存未命中,因为我们遍历的总内存增加了。
对于这个问题我们其实可以这样解决,无非就是看怎么把它们给分开?我是这么处理的,既然掉落数据不常用,我把它单独封装出去,实体里只保存它的指针对象,就像下面这样:
class AIComponent
{
public:
// 方法……
private:
Animation* animation_;
double energy_;
Vector goalPos_;
LootDrop* loot_;
};
class LootDrop
{
friend class AIComponent;
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};现在当我们每帧遍历实体时,载入到缓存中的那些数据就是我们实际要处理的了(指向冷数据的指针例外)。
实际很多时候我们是没这么容易分清冷热数据的界限的,我们很容易在对数据与速度的测试上花费无尽的时间,但要相信你的努力总会换来收获的。
好~,就先介绍这么多了,结束!