如何评价Kaiming He的Momentum Contrast for Unsupervised?
33 个回答
【2019年12月18日最新修改】
看完其他回答,我也来谈谈我对无监督或者自监督研究的看法。
大的方面来说,目前无监督(预)训练性能处于SOTA的有两大流派的方法。
基于变换的无监督训练
一个是以“预测变换”作为自监督信号进行训练的模型,代表是Rotation Net (RotNet)[1] 和AutoEncoding Transformations (AET) [2,3]。
- RotNet [1]通过对输入图像的旋转角度进行分类,实现对图像的特征学习。
- AET[2,3]是我们提出模型,它的思想是颠覆了传统AutoEncoder重构数据的方法(Autoencoding Data, AED),而是通过重构变换(transformation)来实现特征的学习。下面的图对比了这两种模型(AED vs. AET)。按照不同的训练loss,有进一步分成了最小化MSE的第一代v1 [2],和最小化测地线距离的 v2版本[3]
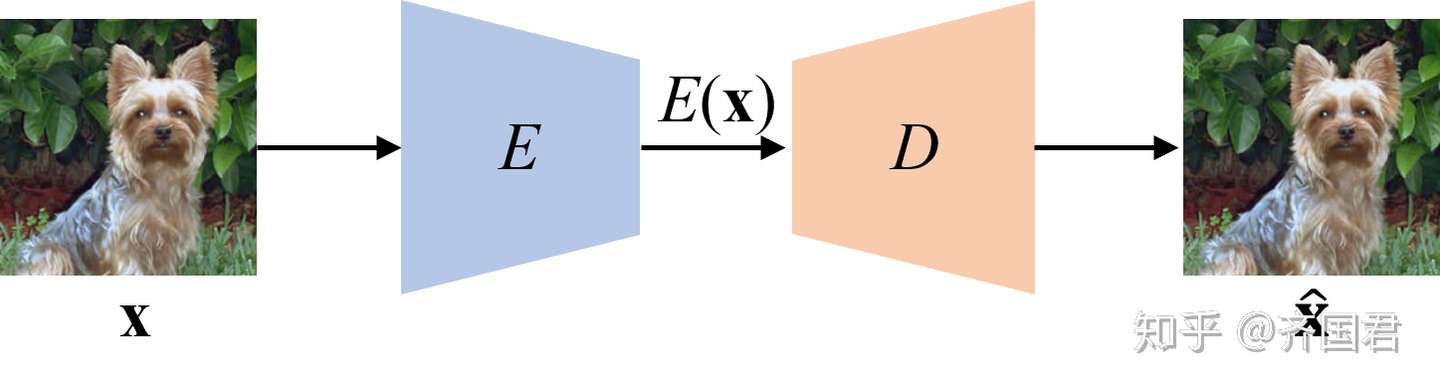 传统的数据自编码模型(AED)
传统的数据自编码模型(AED)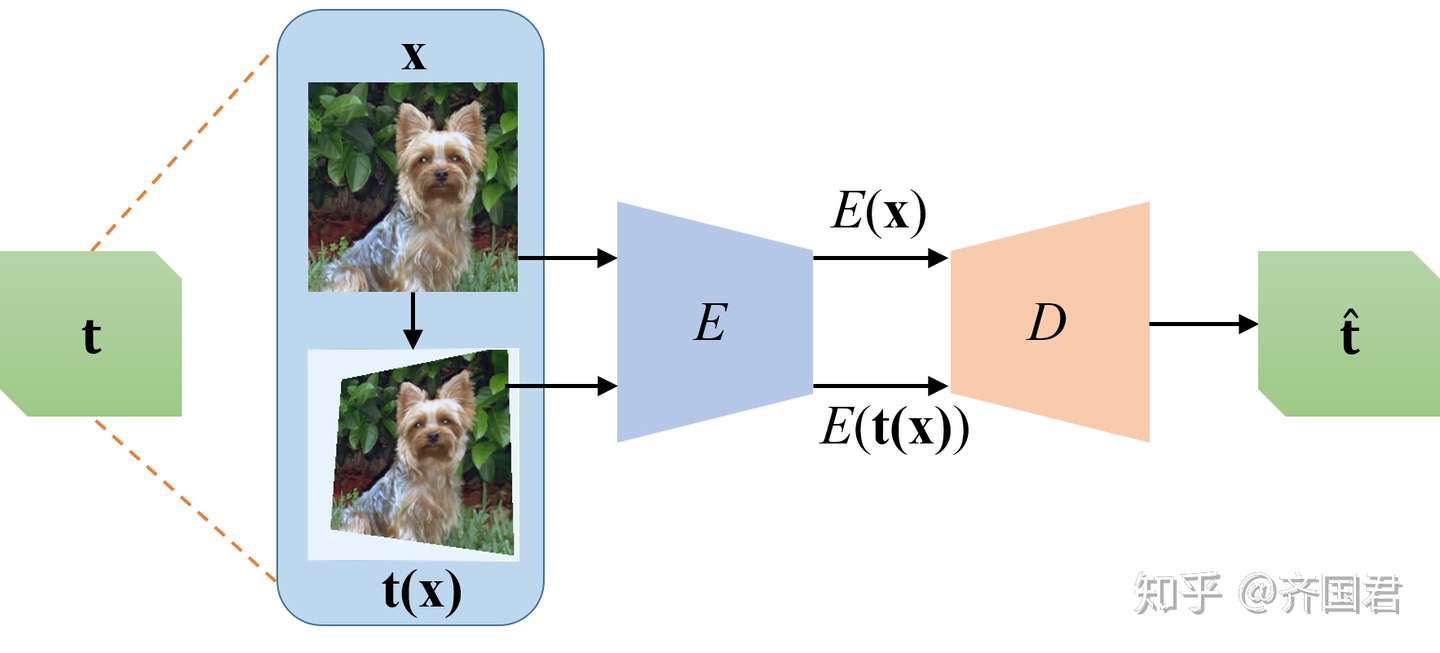 变换自编码模型(AET)
变换自编码模型(AET)
- 特别的,在最新的AETv2中,利用在变换空间所构成的李群(Lie Group)中,我们通过利用在李群所构建的流型(manifold)上计算并最小化预测与采样的groundtruth变换直接的误差,可以进一步显著提高AET的性能。这点不能理解:对所有合法变换所构成的李群(Lie group of transformations),它对应的是一个弯曲的流型,而非一个平坦的欧式变换空间,这点如下图所示。所以利用MSE来计算变化的预测误差显然是不合理的。当然计算李群中两个变换之间的误差,并非易事。需要我们计算黎曼对数(Riemannian logarithm)。这个在一般情况下往往是不容易的。在[3]中,可以了homograhy变换下,如果利用子群投影来实现可优化的方法。具体可以参看改论文。
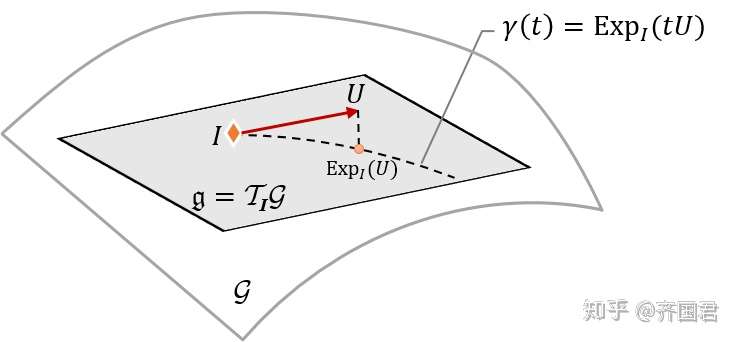 由所有合法变换构成的空间是一个完全的李群,任意两个变换之间的距离应该用它们在李群上的测地线距离而非欧式距离来度量。
由所有合法变换构成的空间是一个完全的李群,任意两个变换之间的距离应该用它们在李群上的测地线距离而非欧式距离来度量。
- 我们近一步将其引申到用最大化特征和变换之间互信息来实现训练,并提出了 Autoenconding Variational Transformations (AVT) [4] 模型。并证明了,得到的AET/AVT特征可以实现 变换同变性 (Transformation Equivariance),这个也是Hinton 在胶囊网络中提出的希望能够学习到的一种重要特征;而AET/AVT实现了无监督训练下也能学习到这种变换同变的特征。
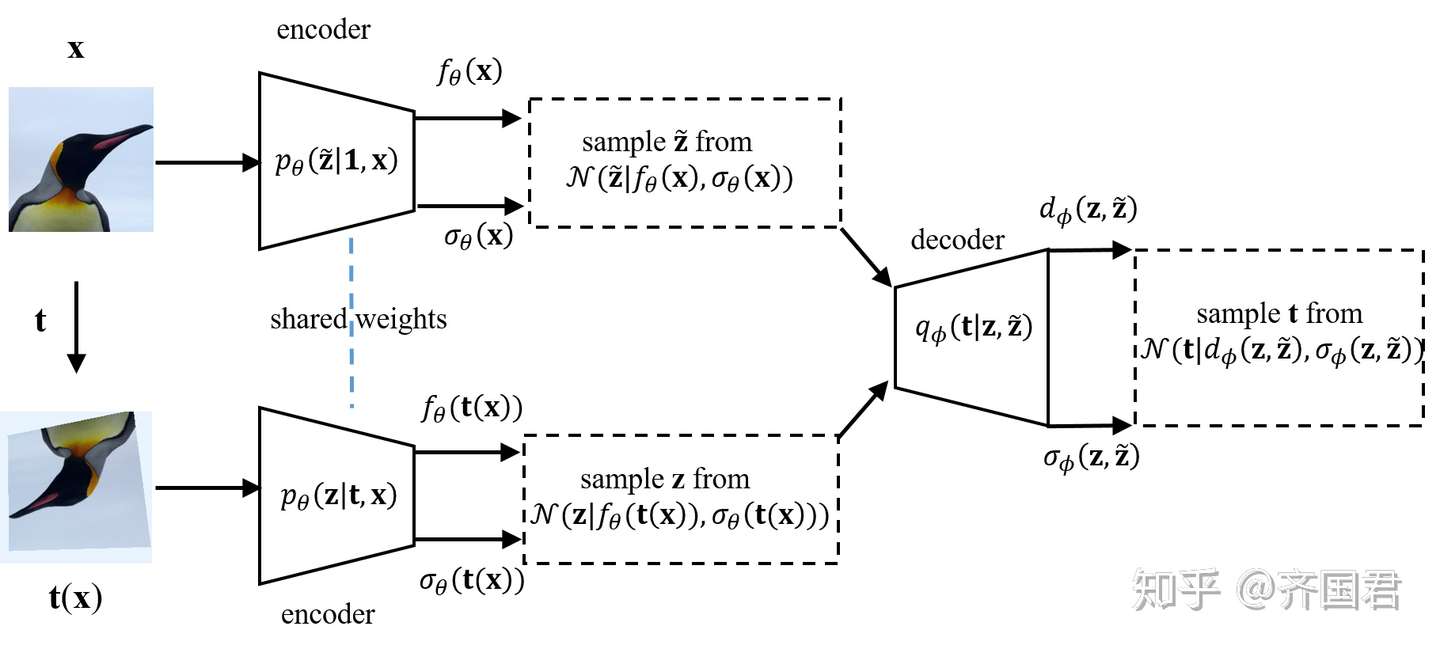 基于变分法的AET模型 (AVT)
基于变分法的AET模型 (AVT)
这类基于“变换”的自编码方法,可以看作是一种无监督的数据增强,不用依赖于被增强样本的标注,这样一方面扩大了可以做增强的样本范围,另外也增大了变换适用的范围:因为在无监督数据增强下,我们不需要关心变换后的样本是否会改变样本的语义标注,进而可以探索更大范围内的变换下,图像样本各种可能的增强。
基于辨别Instance的无监督训练
除此之外,第二种达到SOTA性能就是以contrastive loss为代表的通过辨别不同instance来对实现自监督的训练。Momentum Contrast和其前身方法NCE[5]都是属于这类方法,最近提出的一些其他这里方法, 如contrastive Multiview coding。这类方法最早是收到ExamplarCNN [7]的启发,把每个样本看作是一个个独立的伪类别,用来无监督的训练网络。不同的是ExamplarCNN是直接训练一个最后一层FC来区分这些伪类,而基于contrastive loss的方法是把它看成一个retrieval by example的问题。
通过辨别Instance,进而实现无监督训练,可以看成是deep clustering方法的一种极端情况。即,可以每个样本看做是一个独立的clusters。从这点上来看,deep clustering通过辨别更精细的聚类结构,结合contrastive loss,也许有更大的性能空间可以挖掘,比如 local aggregation 这个工作就是在这方面的一种有益的探索。
两类方法的异同
这两类方法各有千秋,在公平的比较下(同样的网络、同样的数据集),各种都有互有胜负。不过后者,因为要辨别不同的instance,需要额外借助memory bank或者一个队列来存储过去的样本,而第一类的预测变换的方法则不需要。第一类方法也同时揭示了变换共变的性质,而且很容易扩展到半监督学习上[6],并取得了超越mean-teacher的性能,这些都使得它通过无监督数据增强在挖掘无标注数据上具有一定的优势。
值得注意的是,两类方法都用到了变换来做增强。对于第一类方法而言,如上所述,直接可以看作是无监督的数据增强。对第二类方法而言,包括Momentum Contrast,在从一组数据(如memory bank或者sequence)中retrieve一个特定样本是,query和数据库中的样本都是做过某种变换了,这个可以防止出现trivial 的样本retrieval,对无监督训练起到了核心和关键的作用。
结论
这样看来,充分挖掘变换下样本特征的本质,进而实现无监督或有监督特征学习的最优化,是一个特征学习领域的一个重要方向。另外,如何把上述两类方法,在变换和instance 两个维度充分结合起来,实现两类方法的有机融合也是一个非常值得探讨的方向。
[1] Spyros Gidaris, Praveer Singh, Nikos Komodakis. Unsupervised Representation Learning by Predicting Image Rotations.
[2] Liheng Zhang, Guo-Jun Qi, Liqiang Wang, Jiebo Luo. AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data, in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, June 16th - June 20th, 2019.
http://maple-lab.net/projects/AET.htm[3] Feng Lin, Haohang Xu, Houqiang Li, Hongkai Xiong, and Guo-Jun Qi. AETv2: AutoEncoding Transformations for Self-Supervised Representation Learning by Minimizing Geodesic Distances in Lie Groups.
AETmaple-lab.net
[4] Guo-Jun Qi, Liheng Zhang, Chang Wen Chen, Qi Tian. AVT: Unsupervised Learning of Transformation Equivariant Representations by Autoencoding Variational Transformations, in Proceedings of International Conference in Computer Vision (ICCV 2019), Seoul, Kore, Oct. 27 – Nov. 2, 2019.
http://maple-lab.net/projects/AVT.htm[5] Zhirong Wu, Yuanjun Xiong, Stella Yu, and Dahua Lin. Unsupervised Feature Learning via Non-parametric instance discrimination.
[6] Guo-Jun Qi, Learning Generalized Transformation Equivariant Representations via Autoencoding Transformations [pdf]
[7] Alexey Dosovitskiy, Philipp Fischer, Jost Tobias Springenberg, Martin Riedmiller, Thomas Brox, Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks [pdf]
(待续)
一些不成熟的浅见:
- 主体提取 key/query feature 并选择合适的损失函数训练的模式算是 representation learning 中很常用的方法,在人脸等领域其实也在广泛使用,但是似乎很少看到在 key 和 query 上用不同 feature extractor 的,从论文看 momentum encoder 似乎至关重要。
- 选择 key/query pair 上用了林达华老师组的 《Unsupervised Feature Learning via Non-Parametric Instance Discrimination》 的想法,算是 instance discrimination 的进一步挖掘,或许这才是这篇论文的起点。
- Shuffling BN 应该是个大坑,不懂多少实验砸进去才得到这个技巧。
- 性能提升上 Detection 同规模数据不是很明显,但是对 keypoints/densepose 提升显著,大概是因为 imagenet features 的分类能力对 detection 帮助很大,但是对其他任务不一定是最合适的。不过堆上工业级数据(Instagram)就可以超过Imagenet了。可能过几年回头看,这篇文章是真正开启 post-Imagenet 时代的工作。
- 何老师一直呼吁 representation 上有所突破,看了这篇才明白到底是什么,只能说何老师真的厉害。不过不止何老师,作者团队可以说是群星璀璨。
不过似乎这也预示着,视觉学术界连 unsupervised learning 都要打不过工业界了,不仅没数据没机器,这个论文的代码实现估计相当复杂,因为考虑多机多卡(64 GPUs)和各种tricks,一般学生估计没法轻松复现。
(待续
Update: 实现了一下Momentum Contrast和Instance Discrimination, 代码分享出来一并放在CMC的repo下面了, 感兴趣的可以戳这里.
我把文中很多地方提到的Kaiming改成了Kaiming及合作者,或者MoCo. Kaiming是主要作者,但credit应该是所有作者的.
============================
趁着作业写得痛苦的间隙,来分享个人一些小小的想法。
利益相关:Accuracy/Tradeoff图中的CMC (contrastive multiview coding) 是我们的工作, 很欣慰暂时还在Kaiming及合作者的曲线上面,代码有release.

Kaiming的很多工作总是一如既往地硬核,总是非常solid地在解决实际问题!超越supervised pretraining一直是我们做unsupervised的动力之一,很出色的成绩.
但罗马并不是一天就建成的.先介绍一些contrastive learning的背景吧,lecun2007的论文提出的contrastive 的想法(有可能还有更早的)是把positive match在一起,negative分开,不过他的办法是基于margin的(需要设置)
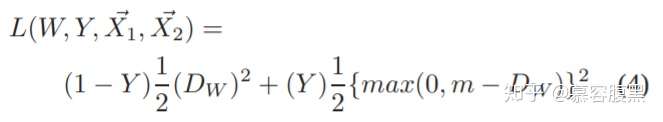
最近大家讨论更多的contrastive loss (包括kaiming及合作者的论文),据我所知,是NIPS 2016率先提出的k-pair loss, "Improved Deep Metric Learning with Multi-class N-pair Loss Objective", NIPS 2016,用在metric learning中:
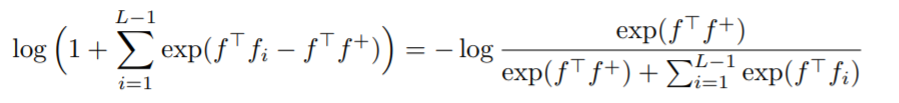
(但这个k-pair loss很简单, 就是softmax + negative log likelihood, 相似的想法在我的学长Yi Sun的一些face recognition工作中也用到了, 虽然形式并不是完全一样. "Deep Learning Face Representation from Predicting 10,000 Classes" CVPR 2014, "Deep Learning Face Representation by Joint Identification-Verification" NIPS 2014.).
然后包括后来Tong Xiao他们的person re-id也用到了这个loss.但这个loss真正work的关键点就是你要sample很多negative,mini-batch很小又没有办法怎么办呢?Zhirong Wu和Yuanjun Xiong的instance discrimination非常机智地引入了memory bank机制,并且真正地把这个loss用到了unsupervised learning而且还把参数都调好了,可以说是这一波的开篇之作,非常赞.后来的CPC, CPC V2, AMDIM也都是用的这个k-pair contrastive loss来学特征,但更进一步地提出了数学上面的insight, 即是maximize mutual information.(我觉得CPC挺好的,但貌似这次他们的CPC V2投ICLR悲剧了,openreview说他们比cpcv1没有太多novelty,但问题是cpcv1也被拒了至今还没中,这还让不让人发表了:( )
总结起来,以上这些contrastive loss的工作(可能有遗漏,我这里主要梳理了重点的几篇), 包括凯明的工作,都可以理解成你有两个variable, 和
,并且你有一堆从相应的联合分布采集的sample
,给定一个
, 现在从y这边去选择,对应的
就是正样本,不对应的
就是负样本.然后对每一个这样本,我们都配对N个负样本去学习一个softmax loss.
有了这么个框架,那么instance discrimination可以把 理解成当前的第i张图片的随机crop,
理解成过去epochs对第i张图片的smooth aggregation(或者第i张图片的另一个crop). CPC, CPCv2就可以把一个image patch理解成
, 把他的context理解成
.我们的CMC可以把一个modality,比如rgb, 理解成
,另外一个modality,比如光流,理解成
.这个框架也启发我做了一个Knowledge Distillation的side project ("contrastive representation distillation"), 可以把teacher理解成
, 把student理解成
.同样的MoCo里面的两个encoder,也可以其中一个理解成
,另外一个是
.关于怎么样选取x和y,我们的CMC论文里面有讨论,我们的猜测是应该有一个很有意思的sweet point,感兴趣的可以看看我们的论文.
所以有了这样的背景,就可以大概看出其中的key, query只是取的名字而已,本质只是x和y.并且大家之前已经explore很多了.我认为MoCo这篇最创新的地方,就是解决了一个非常重要但以前又没有思路的工程问题,就是怎么节省内存节省时间搞到大量的negative sample。之前的memory bank虽然机智,但是必须存下来整个数据集,空间开销O(N),所以处理不了Instagram级别的数据,这个问题困扰我很久而且我没找到有效策略,我试过跟MoCo一样用一个queue,也是存过去m个batch的sample,这个其实很容易想到,但我发现效果不好,问题就是我只有一个encoder,我没有像他一样在不断update这个encoder的同时保存一个它的历史smooth的版本。这点说透了后听起来就没那么复杂, 但在他们发现这点之前这个办法并不显然, kaiming在这些地方总是尤为厉害, 哎真的学不来。 (又跟同学学习了一下, 这个相似trick在Q-learning里面就很多被用到, 大家update Q-function的时候就是用类似的momentum去做的,看来是我学得太少)。以后有了MoCo这个momentum encoder机制,大家就又可以放开刷了, 应该可以跟其他方法互补。另外一个重大的贡献就是我觉得他系统性地研究了这样的pre-training在各种downstream task下面transfer的效果, 间接帮做自监督学习的人验证了目前的进展. 以前大家的自监督方法,比如旋转和上色, 都很难超过imagenet预训练的模型. 最近的Contrast方法确实work,但在前面pretraining这步训练就耗得半死, 大家都没有精力太去测各种task的transfer. 只能说羡慕FAIR.
MoCo的工作一出来,我心情挺复杂的.一来这篇因为作者们的名气会引起大家更多地关注unsupervised learning,更多人投入进来也能把这个领域做的更加出色.另外一方面可能自己辛苦搞了很久的工作又要被忽视了,其实我觉得如果完全公平地比较,CMC应该在imagenet比MoCo好,并且transfer也应该比MoCo好.不过遗憾的是我自己一个人拿着学校的4卡机器慢慢跑所有实验(此处要感谢学校同学有时候让出的资源),太累了,也没有精力去试试transfer.希望还是不要太快被淹没在历史的潮流里面 , ICCV被拒,这重投又似乎要被拒,太难了,kaiming他们这么一搞,以后有可能发不出去了.
最后关于以后可以做的,我个人还是觉得Multimodal representation learning是值得尝试的方向,并且相信老板对multiview的sense是对的.其实在cognition以及developmental psychology领域,大家都讨论了很多关于婴儿如何利用multimodal的redundancy去teach不同modal的neural system去学习的话题.另外一个关于contrastive loss的研究方向,我觉得还可以尝试新的采样的策略,我个人认为之所以从1百万到1亿的数据增加并没有带来太多的提高,也是因为负样本都是随机选取的,所以从1亿里面取的并没有更有信息量太多,可能这里需要结合聚类来做. 初步的探索已经包括: Local Aggregation of unsupervised learning of visual embeddings.
下游的Person Search / ReID领域终于间接启发一下了上游的representation learning :D

一些小的想法:
- momentum encoder确实很巧妙,让这个方法扩展到了大数据集
- 个人感觉loss里面的tau会是比较重要的超参,特别是网络初始化不好的话
- reid里面结合softmax loss和triplet loss会有帮助,没准也能应用到representation learning
我理解这是一篇technique为导向的文章,继承kaiming一贯的模块简单、效果爆表的风格。说是unsupervised learning上的重大突破我觉得过誉了,不过它作为打穿unsupervised learning的最后一环,是少不了关注的,跟15年kaiming刷爆ImageNet的文章套路一样。而且这篇文章的technique和很多self-supervised learning的任务互补,也不依赖vision的具体特性,肯定有很多领域会拿来用。
文章的核心内容并不复杂,就是constrastive learning中的一种模型层面的moving average。technique直接看方法图和pytorch伪代码(手动狗头)基本就能明白了。至于文章的motivation,之前contrastive learning存在两种问题。在用online的dictionary时,也就是文章中比较的end-to-end情形,constrastive learning的性能会受制于batch size,或者说显存大小。在用offline的dictionary时,也就是文章中说的memory bank(InstDisc)情形,dictionary是由过时的模型生成的,某种程度上可以理解为supervision不干净,影响训练效果。那么很自然的,我们想要一个trade-off,兼顾dictionary的大小和质量。文章给出的解法是对模型的参数空间做moving average,相当于做一个非常平滑的update。
我看完motivation后,第一反应是直接用end-to-end搭配queue来达到上面说的那个trade off。不过依MoCo来看,估计这个想法是行不通的,不然以FAIR各位做实验的能力早就做出来了。我猜原因可能是end-to-end update得到的key encoder会比较noisy,相当于supervision总在变,optimization上不友好。这篇文章的high-level idea和variance-reduced optimization还有几分相像。在optimization里,会用历史stochastic gradient的平均来减小variance,提高优化速度。MoCo这里则是用历史stochastic model的平均来减小teacher的variance,提高supervision的质量。当然这个idea在更早的mean teacher里也出现过。从这点意义上说的话,MoCo也可以看作一个改进了optimization的InstDisc,只不过原版InstDisc训到这个水平,可能需要指数级别的训练时长。
MoCo在点数上非常solid,相比InstDisc直接在ImageNet的top-1上净涨了6.6个点。但是有些baseline就有点令人玩味了,COCO detection同样是在random init的情况下,kaiming 18年的Rethinking ImageNet Pre-training里面R50+FPN+GN在6倍epoch下mAP达到了41.3,这里只放了2倍epoch下36.7,有可能还没加GN。
很荣幸被cite了好多次,核心思想跟我们CVPR19的文章 [1] 比较类似,都是基于instance discrimination 来做unsupervised representation learning,同样类似的文章还有examplar CNN [2] 和 NCE [3], Local Aggregation [4][5]。简单介绍一下instance discrimination的发展史,下面是详细分析:
- ExamplarCNN [2]: 早期用instance discrimination的思想来做无监督学习的,将每一个instance当成一个单独的类来进行学习,即对每一个instance 学习一个classifier weight,而且由于batch size一般远小于instance number,所以每个step与所有instance classifier weights 对比,优化效率比较低。
- NCE [3]: 引入 memory bank的去替代上面的classifier weights, 把前一个step 学习到的instance feature存储起来,然后在下一个step把这些存储的memory去学习。效率有所提升。但是实际在优化的时候当前的instance feature 是跟outdated memory去对比的,所以学习效果还不是最优的 (这一部分在kaiming的Sec 3.2 以及我们paper[1]的 Sec 3.1 都有相应的分析)。
- Local Aggregation [4] 和Anchor Neighborhood Discovery [5]: 这两个paper 在上面NCE的基础上引入了local similarity/neighborhood 的思想,学习到的embedding大大提升。
- Invariant and Spreading Instance Feature [1]: 我们在今年CVPR19 上提出了一种新的学习的方式,可以直接在instance feature level 上进行学习。 我们直接用random data augmented instance feature做为“classifier weights”进行学习,并且采用了一个Siamese的network 去训练,这样两个网络的instance feature 可以实时的进行比较和学习。学习效率和准确性都有所提高,我们的文章也对上述两个方法的优缺点有详细的分析。相关代码也在github开源了。
- Momentum Contrast: kaiming 大神用momentum的思想很好的弥补了我们方法的缺陷,从而使得模型在学习的过程中避免学习classifier weights 和memory bank,同时又保证可以handle大规模的数据!其中的shuffle batch normalization 应该也是进一步稳定这个training过程的一个很重要的trick。类似的做法也在deepCluster [6]论文里面每个epoch对classifier 重新做random initialization,两种做法应该有类似的效果,使得学习到的特征稳定性和泛化性都能有所提升。
[1] Mang Ye, Xu Zhang, Pong C Yuen, and Shih-Fu Chang. Unsupervised embedding learning via invariant and spreading instance feature. In CVPR, 2019.
[2] Alexey Dosovitskiy, Philipp Fischer, Jost Tobias Springenberg, Martin Riedmiller, and Thomas Brox. Discriminative unsupervised feature learning with exemplar convolutional neural networks. In IEEE TPAMI, 2016.
[3] Zhirong Wu, Yuanjun Xiong, Stella Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In CVPR, 2018.
[4] Zhuang, Chengxu, Alex Lin Zhai, and Daniel Yamins. Local aggregation for unsupervised learning of visual embeddings. In ICCV 2019.
[5] Jiabo Huang, Qi Dong, Shaogang Gong, Xiatian Zhu Unsupervised Deep Learning by Neighbourhood Discovery. ICML 2019.
[6] Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. Deep clustering for unsupervised learning of visual features. In ECCV, 2018.
2019.11.25更新:关于unsupervised和self-supervised learning,原始论文中也提到了这个问题,以下是原始论文中的footnote

首先这是一篇很适合工业界的实验文章,他很好的解决了工业界一直想解决的一个问题:图像任务能不能按照NLP领域中的Bert一样,只用一个backbone提取通用的特征,然后适用于全部下游任务(分类,检测,分割,生成等)。
这个问题对于工业界的意义很大,因为一旦有了这样通用的embedding,那我们只需要维护一套特征库,并且节约大量的成本和计算量。具体的影响可以参照去年的Bert对工业界的冲击。所以即使文章的novelty只有两个像trick似的改动,它的contribution也是极大的。
不无脑吹,理性看,文章其实很简单,照搬了,微软在上半年的工作:Learning Representations by Maximizing Mutual Information Across Views(AMDIM),甚至在看论文中的一些小的处理细节,例如data aug的地方:
The data augmentation setting follows [59]: a 224×224-pixel crop is taken from a randomly resized image, and then undergoes random color jittering, random horizontal flip, and random grayscale conversion, all available in PyTorch’s torchvision package.
也是和AMDIM一模一样,感觉是直接clone了amdim的代码然后改改。文章的主要novelty是加了两处改动:一个Momentum Contrast也就是加了momentum参数m;另一个Shuffling BN考虑到信息泄漏对每一个batch做了shuffle。从学术界来看理论深度是不太够了,但是既然是工业paper,效果爆炸就可以逆天。
这篇文章最强的contribution我认为是他很好的总结了目前所有self-supervised representation learning的方法,然后试验了很多的downstream task。包括Object Detection,Segmentation,pose estimation等一系列除了分类以外的任务。实验部分用了有钱任性的数据集和训练资源,
说它是一个Unsupervised learning方法我是不信的,因为实际上它还是用到了海量数据中的data structure,然后把这些信息作为虚拟标签来做有监督训练,只不过过程不是无监督,最后的结果是可以拿到无监督表示(因为把所有数据都枚举完了)
(这段话有误,根据论文self-supervised learning是unsupervised learning的一种形式)
最后打波广告,推荐一下组内的工作,self-supervised representation learning除了能用来做普通的下游视觉任务外,他还能做其他很多事情,包括我们尝试用来做Few-Shot的图像分类:
Self-Supervised Learning For Few-Shot Image Classification以及我们发现,self-supervised representation还有很好的对抗防御能力,可以用来做鲁棒性模型:
Self-supervised Adversarial Training个人对表示学习不是很了解,不过最近一段时间在看一些半监督方面的工作,感觉很多地方还是很相似的
对于unlable的样本,如何将其加入网络巡练,这里是用了query-key的模式去train一个encoder
为了稳定性,选择用一个queue来记录,然后用momentum的机制去慢慢更新这个queue(感觉很像mean-teacher的moving average)
我是主做医学图像的,感觉这个工作用在医学影像分析的预训练上,潜力很大,毕竟这个领域的标注成本太高了,不同器官,甚至是同器官的不同任务之间的domain shift都非常严重,如果能把unlabel样本以及正常的无病灶样本都有效利用起来去pretrain,那是真的非常nb了
而且这个工作还可以和Vat等等半监督的工作结合起来,可能接下来一年很多东西的baseline都会有明显的提升了啊
这一波操作很迷啊,上半年发了一篇train from scratch可以和pre-training一样效果的work,搞的做self-supervised learning的人很绝望,supervised pre-training都没用我还做self-supercised learning干啥。结果现在继续把不要label的pre-training做成和要label的一样了。
所以到底是pre-train还是不pre-train啊
近日,何凯明团队挂出来了MoCo_V2,效果相对于V1有了较大提升。整篇文章不算参考文献仅有两页,主要解决了两个问题:
1、MoCo_V1中提到的data augmentation方法;
2、用MLP head代替 projection head。
在MoCo_V2中,主要对比了MoCo框架和SimCLR的效果。
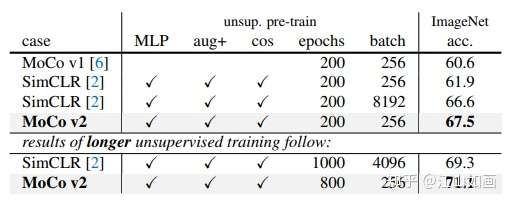
可以看到,在MoCo_V1被SimCLR大幅超越之后,凭借非框架性的手段,又重新获得了领先的地位。并且字典大小与minbatch的解耦,计算消耗上也相对于其他框架也是具有着优势的。
一句话概括MoCo_V2就是,没有改变MoCo_V1的框架,通过一些方法更深的挖掘出MoCo_V1的性能,大到目前start-of-art的效果。
下面正式介绍MoCo这篇文章。
无监督表示学习方法,是指在不存在人工标注信息的数据下,通过学习提取出图像内在的representation,这个representation又是什么呢?简单理解就是分类、分割、检测等任务Encoder后获取到feature map,类似于元学习和mutitask中学到的一个公有特征,只要学好了这个公有特征,那么根据具体的任务,具体的数据,只需要稍加迁移,就能够在目标数据目标任务中有着姣好的表现。所以说他的优势也体现在两点:
1、更快,具体的下游任务是在学习好的representation的基础上进行的,而不是从头开始训练。
2、更准,表示学习是在大数据集上进行的,能够从更多的数据学习到图像的representation,相对于目标域数据的规模,大数据是优势。
3、泛化性好,同样是由于表示学习的数据集由于没有人工标注,所以首先可以做到很大,其次类别也不受人工标注的限制,更接近从自然世界学习特征,任何目标域的数据都不存在严重的domain gap。
那么表示学习是如何实现的呢?
我们看MoCo这篇文章的方法,同样是两个关键步骤:
1、Pretext tasks,所谓Pretext tasks就表示,这个不一定是我们真正关心的任务,而是一种能够让模型学习到数据representation的task,这个task是什么无所谓,只要能够学习到数据的representation就行,比如文章中提到的,对图像的恢复,去噪自动编码,内容编码、或者通道间信息的编码,等等。这些任务有两个共同的特点,就是a)能够输入图像输出特征,b)利用图像自身的信息完成监督。MoCo采取的是instance discrimination方法,由于pretext task并不会影响到MoCo的框架,所以文章没有做更多的研究。
2、Contrastive learning,简单理解,就是输入图像以及输入图像自身的变化(data argumentation)作为正样本,其他随机采样作为负样本。然后计算经过编码之后的分类损失。这一部分是关键,因为如果想获取到较好的表示学习效果,那么负样本一定要足够的大,也就是要构建一个足够大的字典,让网络能够充分学习到正负样本的区别。但是此时就面临一个问题,收到minbatch的限制,字典无法做到很大,要不然性能消耗会爆炸。
所以何凯明通过构建了一个queue来存储字典的方式,实现字典和minibatch的解耦,具体而言就是我来一组负样本图像,经过一次编码,向字典中添加一批key。字典被填满之后,则新的key继续进入queue,旧的key则从queue中移除。以此实现字典和minibatch的解耦以及字典的动态更新。
那么这样做之后,又出现了新的问题。由于字典中的并不是同一批次的,那么对应encoder肯定也是不同的了,如何更新对应点编码器呢?所以MoCo在这里又给出一条约束,就是地点变化要足有平滑连续,不然key1是由旧的Encoder1编码得到,如果Encoder1和新的Encoder2相差较大,那么key1对应的损失是无法给Encoder提供参考信息的。
所以如何更新Encoder就成为一个至关重要的问题了,MoCo采取的方法是,也就是文章命名的关键Momentum。
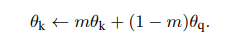
可以看到key对应的encoder是由query对应的encoder来更新的,同时受到key对应的Encoder上一次的状态影响,所以其更新速率要慢与query对应的encoder。具体要有多慢呢?慢到字典中最旧key依然能够反映出最新的encoder信息。所以文章给出m=0.999,要远好于m=0.9。直观的的感受就是,key对应的encoder基本不动,非常缓慢的更新,字典中所有的key可以近似的看成由该encoder编码得到。
这样,以上难题就得到解决了,MoCo的框架也便完成了。
对于没有接触过表示学习的,可能看起来会有些费力,如果在这个领域有一定的知识积累的话, 这篇文章是一篇非常简单的文章,没有任何难以理解的逻辑。就算没有接触过表示学习也没有关系,多读几遍也就明白了。
Shuffling BN这个技巧我就不介绍了,可以说他不是MoCo框架的一部分,其他框架也可以用。
总结来看,就是要明白几点:
1、大数据集,除了query图像和他的同源图像(augmentation)之外,其他的图像都是负样本。利用大量负样本字典,去学习一个pretext task。
2、字典要足够到,但是受限于字典,minibatch无法足够大,所以构建queue把二者解耦。
3、为了能让queue的key真实反映当前的encoder,要保证足够的连续性。所以要动量更新encoder。
我也是最近才接触到的表示学习,一开始什么也看到不懂,完全不了解这个概念,但是无监督学习一定是人工智能的未来,而不像有监督学习一样,有多少人工就有多少智能。所以就反复的研究文章,现在自认为是看懂了MoCo,当然还有很多要看的,包括这个回答下面的就有很多优秀额学者,我也在fellow他们的研究,比如
同学的CMC等一系列研究, AET系列研究,以及SimCLR方法,希望能够尽快跟上该领域优秀学者的最新动态。大家如果也对这方面有兴趣,我们可以加入微信群互相帮助,共享资源和学习进展,有兴趣的私我吧~~
表示学习及其问题
Kaiming He的文章显然借鉴了NLP社区的很多思路。
首先是各种无监督的语言模型为下游任务进行预训练的做法,BERT、XLNET和Ernie一类的词向量模型已经证明了类似打法有效性。
其次是哈希查询结构,如果有人还记得《Attention is all you need》这篇文章,它的Scaled Dot Product Attention就是通过三元组查询,学到输入embedding的权重表示,并为输出embedding准备一个有待前馈的隐向量。
然而,我们忽略了一个问题,语言空间的维度很高,视觉空间的维度,却是更高的。语言定义在离散的空间里,相比于定义在连续空间里的像素,是一种稀疏的表示。人类语言,是思想的载体,transformer模型见到的语料,受限于一定的表达规则和语法,而图像数据,则更为庞大。如果表征学习,要靠无监督预训练模型,真正达到图像理解,而非模式识别,一个ImageNet数据集,是否能担起重任呢?
对比学习
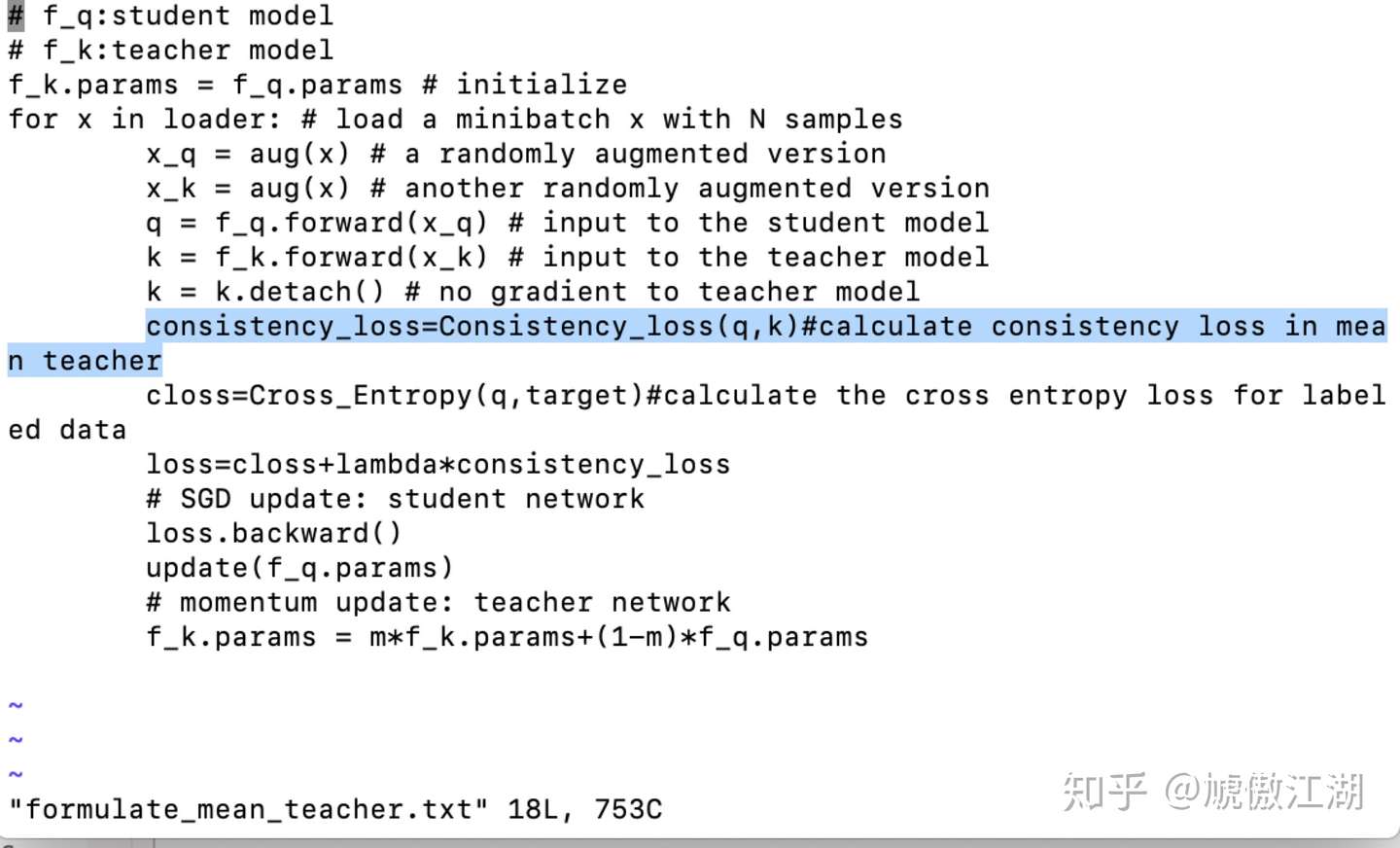
目标函数设计为了训练字典,假设编码查询q和一组编码样本{k0、k1、k2、.},它们是字典的键。假设在字典中有一个Q匹配的键(以k表示)。对比损失是一个函数,当q与其正键k相似,而与所有其他键(q为负键)不同时,其值较低,见公式(1):
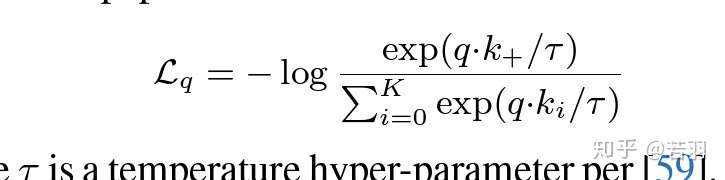
字典、队列、动量
Kaiming He等人的假设:较大的字典可以更好地采样底层连续的、高维的视觉空间,而字典中的键应该用相同或类似的编码器表示,以便它们与查询的比较是一致的。
实际训练的时候,靠队列维护字典,一个个batch的张量被压入队列。作者假设说比较陈旧的mini-batch-data对训练哈希encoder是过时的。
动量更新机制:使用队列可以使字典变大,但是它也给反向传播训练键编码器带来了极大的难度,似乎之前林达华组的论文是从查询编码器中复制梯度到键编码器,但实验效果一般。Kaimimg He等人假设这个issue是由快速变化的编码器引起的,这降低了关键表示的一致性。他们提出了一个动量更新来解决这个问题,如公式(2),相对于加了个阻尼系数:
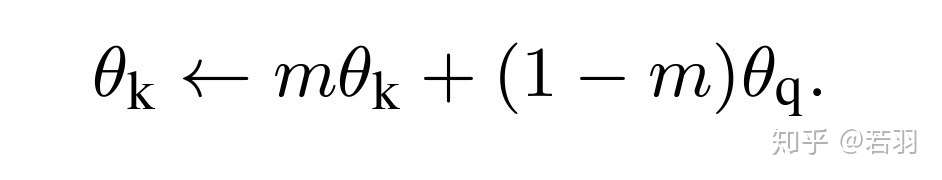
可以参考伪代码如下:

比较好奇,这个损失函数
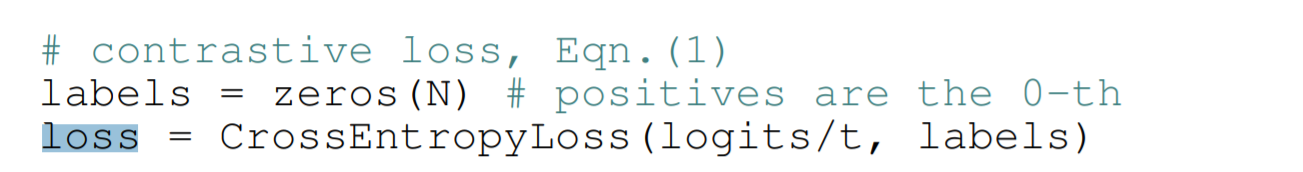
在Pytorch代码里,怎么复现?有网友看到这个点,也许可以思考下。
端到端方法与内存银行方法局限性
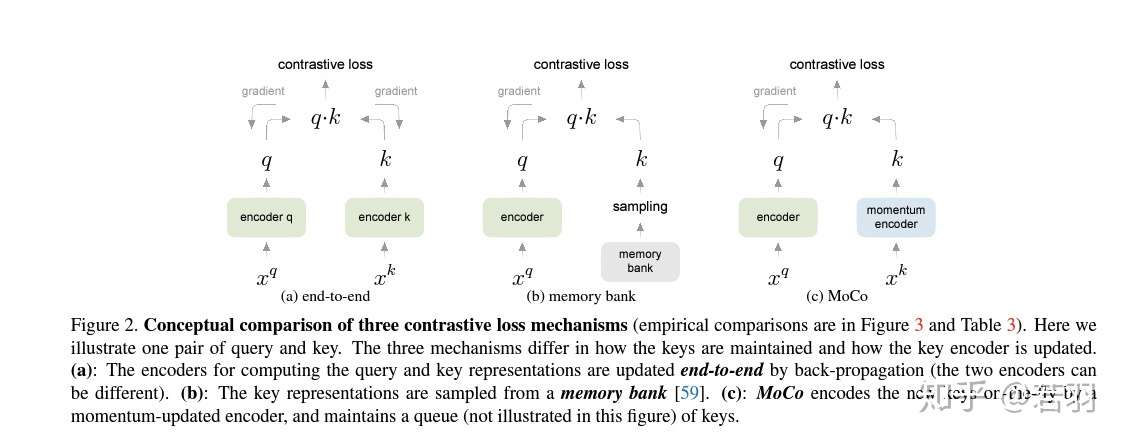
被拿出来证明方法有效的两种背景:
1.end-to-end:一个批次一个批次的编码建字典,可以保证key-value一致性,但字典大小与batch-size大小绑定在一起,受限于GPU算力。
2. memory bank:林达华教授组的工作,memory bank方法包容了数据集中所有样本。每个小批的字典是随机抽样的,在训练中没有反向传播机制,所以它可以支持一个大的字典大小。在最后一个样本训练完成后更新表示特征。因此,采样的key本质上是关于过去各时期多个不同步骤的编码器决定的,会有不一致性。
结语
记得前一段时间,计算机鬼才——王垠老吐槽现在的计算机视觉三大任务——图像分类、目标识别、语义分割,只是像素level的模式识别,不是整体视觉空间的图像理解。因而,谈不上智能。
然而,要真的达到图像理解,就离不开推理、归纳机制,现有基于标注的有监督学习,肯定是要被新方法取代的。
至于这种取代,是革命性的、还是改良性的。Kaiming He等人的倾向,应该是后者,目前很难看到前面一种路线图的清晰替代方案,好像胶囊网络的热度已经下降了。
这么来看,Kaiming He可能确实挖了个大坑,他应该是会慢慢填坑的,而且“大教堂安抚小集市”的AI产业现状,也使得这种坑,只可能由脸书和谷歌这样的企业来填。
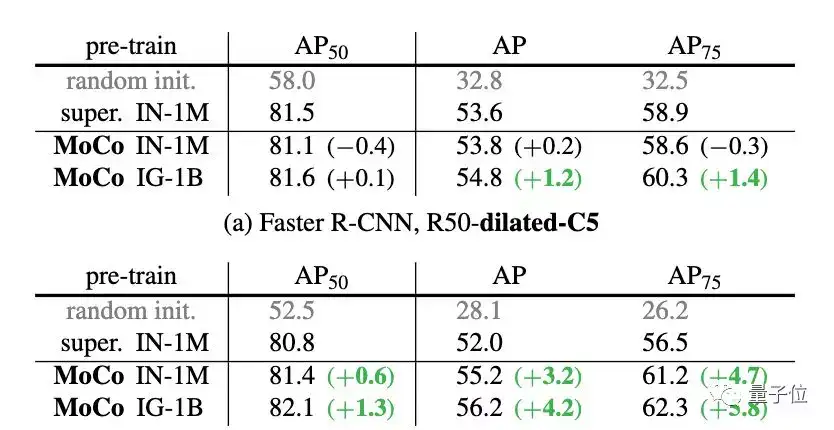
MoCo can outperform its supervised pre-training counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, sometimes surpassing it by large margins.
This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.
看完这两句话,自己写的东西都不想提交了。本来以为投过cvpr以后我和何恺明的距离可以从猴子到人类缩短到人类和人类,没想到已经拉大到草履虫和人类了
差距还体现在自己写东西生怕不够fancy没有novalty,非要强行弄个algorithm框框。而何恺明已经放飞自我到在algorithm框里面写pytorch风格伪代码了。给pytorch代码就算了,最骚的是居然还有python风格的#开头注释……只能说天下逼共一石,恺明独装八斗。
这个地方拍马屁的风气还是很盛行啊,大佬说什么都是香的? 最好还是放弃虚名,考察一下方法的核心到底在哪里吧。为什么通过个体间的discrimination,就可以完成这个任务,这个过程应该如何理解? 直觉上,让我想起广义相对论中只需要知道每一点光的方向就可以在一定程度上重构时空的度量这个结论,但具体如何理解,只通过discrimination,到底可以重构出实际数据空间的什么结构,还需要仔细想一想。我个人觉得这个是比单纯靠实验验证这种方法可以无监督的完成训练任务更有意义的问题,难道大家不想这个问题么?我看很多回答偏重于就事论事,有点过于注重技术细节了,对整体的理论上的问题考虑的似乎少了点,应该去考察这种监督信息约束下性能的极限在哪里,或者说能否保证达成目标,如果不足以保证达成目标,需要附加何种条件等等。可能这些靠实验跑板子是不容易得到结论的。
比如在楼下提到的CMC中,直接说最优的判决是相当于使用互信息,窃以为这个结论就有点草率了,因为最优必须要在给定约束下才有意义,在没有确定约束的前提下判决某个解是最优,是有疑问的,单纯从判别 positive/negative这个东西本身来说,好像并不能给出最优的判据,必须附加约束(论文中对判决函数构造的网络的参数的约束),但是我没有看到论文中说明这个约束,以及相应约束的物理或者信息处理上的含义。互信息是一个好解,但不一定是最优解。另一问题,CMC提出为何其方法优于predictive learning, 我觉得是因为CMC考察了样本的relative relationship,而不仅仅是只保证一对一的数据保持能力,毕竟学习的本质是要学到整个数据流形的特征,所以relative relationship是重要的一部分,甚至是更重要的部分,这一点在CMC论文中也略有提及。所以,考察这种监督信息到底能重构数据空间的何种结构,应该还是这个方向的核心。从我的理解看,一种理解是,CMC本质就是在进行不同modality图像空间的registration,其配准过程是把不同modality的流形映射到各自的某个类似切空间的空间上然后在切空间之间进行配准,而这个配准是不是就是基于互信息的准则为最佳,就不一定了。这个问题有多种图像来理解,到底哪个好,还是一个值得考察的问题。我是担心互信息会丢失不同modality个性化的信息,虽然可以抓住不同modality所编码的共性的信息,但是这些不同的modality specific信息对于下游的问题可能是有用的,比如在医学图像处理中,如果CT/MRI只是把共有的信息保留了,那么对于诊断任务而言,肯定会有信息丢失,从这个角度看,反而是predictive learning可能保留这些信息(不过怀疑这些信息是在嵌入空间中,还是在decoder中)。
回到论文,工作还是何一贯的风格,就是开发面向应用的有效方法。这个方法应该还是在做嵌入,相比于强调保持个体自身信息的自编码器,这里更多强调不同个体之间的关系,直观上理解应该就是在嵌入空间每个个体都把其他个体尽量往外推,从而使得样本间距离在嵌入空间达到一个平衡的分布。这个有一些 relational theory的味道。至于具体的技术细节,比如采用 momentum更新,其实还是对系统加了阻尼,要求推起来要费点劲,增加了系统的稳定性。
如果说有问题,好像还是在对个体间距离的设定上,是否仅仅通过要求每个个体与他人的距离尽量远这一条就可以保证得到好的嵌入呢?毕竟还是有相似的图像,按照这个方法得到的嵌入能否忠实的表达图像之间相似程度的差异?会不会因为要求距离尽量远的准则过于简单粗暴导致嵌入空间对图像间距离的扭曲? 此外,由于方法仅仅直接要求距离的分布,没有对嵌入空间对数据信息表达的完整性的要求,会不会导致丢失一些必要信息? 还是感觉单靠一个discrimination的特征不足以完成可靠的嵌入,一定需要结合其他的trick才有这个可能。比如,既然都编码了,为何不直接把解码器也弄上,至少保证信息不丢失啊。
另外,非常反感这个领域胡乱弄些唬人名词的做法,什么表示学习?有必要弄个新名词么?其实就是充分统计量加上复杂度约束而已,弄新名词唬人有意思么?还有什么 self-supervise,其实只要不是外界提供监督信息,其他的所有监督信息都是挖掘数据本身的某种相容性特征来构造的,没有本质的差异,弄那么多乱七八糟的名词干什么?
最后,这个工作闻起来同时有一丝 GAN 和 attention的味道,两个网络竞争, 以及嵌入到线性空间求点积,越看越眼熟, 究竟应该如何和这两个东西结合起来看,需要想一下。
PS,还是感觉这就个GAN啊,query和 key的变换网络本别是G和D,D其实是把数据映射到嵌入空间并将嵌入空间看作欧氏空间构造了对每一个样本的判决函数,G则是要尽量生成和目标样本相似的数据,然后二者博弈,并且为了GAN的收敛,二者还是要紧密关联,这里是靠所谓 momentum更新来实现的。
另一个理解是,这就是个attention,就是要保证要把给定的query的注意力注意到对应的key上去而尽量忽略无关的key。
这篇文章确实是经典之作。但是不得不答一句,和凯明邮件来往了好几封,凯明始终不肯引用半监督经典之作mean teacher的工作,我做了两个的算法对比图,这个momentum encoder不就是mean teacher里面的teacher network吗?而且teacher network update的方法都是EMA,用的参数都是0.999。而且进一步而言,mean teacher中的J loss不是和这里的l pos很相似吗?为什么不能引用呢?各位都一起探讨下呗,两篇文章核心点当然不同,但是我认为这个大框架是mean teacher的student teacher model的路子吧。凯明的贡献主要在loss的引入和dictionary的开创性想法,但是momentum这块明显应该引用下mean teacher吧

何恺明的一作论文,又刷新了7项分割检测任务。
这一次,涉及的是无监督表征学习。这一方法广泛应用在NLP领域,但尚未在计算机视觉中引起注意。
Facebook AI研究院的何恺明团队受此启发,采用对比损失(constrative loss)法,即从图像数据中采样键(或令牌),并由经过训练、与字典相匹配的编码器表征。
新的方法,名叫MoCo(Momentum Contrast)。其预训练模型经过微调可以迁移到不同的任务上。

在ImageNet、CoCo等数据集上,MoCo甚至在某些情况下大大超越了监督预训练模型。
研究团队表示:
这表明,在许多视觉任务中,无监督和有监督的表征学习之间的鸿沟已经大大消除。
方法原理
那么,MoCo究竟是怎么实现的呢?
像查字典一样的对比学习
对比学习(constrastive learning),可以看做是在训练编码器来完成字典查找任务。
假设字典中有一个与编码查询(query)相匹配的键(key,表示为k+)。对比损失函数中,当查询与k+相似,且与所有其他键不同时,函数值较低。
在这篇论文中,研究人员采用的对比损失函数如下:
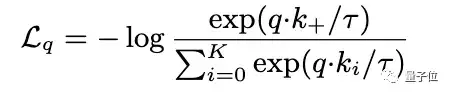
这是一种无监督目标函数,用来训练表征查询和键的编码器网络。
动量对比(MoCo)
用一句话来说,对比学习就是一种在高连续性输入(如图像)上构建离散字典的方法。
MoCo方法的核心,是将上述字典作为数据样本队列来进行维护,这样一来,字典就能重复使用已编码的键,字典就可以比通常更大,并且可以灵活地、独立地设置为超参数。
这是一本动态字典,其样本会逐渐被替换,但始终代表着所有数据的抽样子集。
其次,需要考虑的是更新编码器的问题。
使用队列可以让字典变大,但也会让通过反向传播来更新键编码器这件事变得更困难。
研究人员假设这种困难是编码器的快速变化降低了键的表征一致性所造成的,于是,他们提出了动量更新的方法。
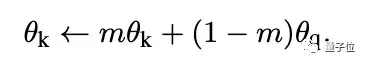
在这个公式中,只有θq是通过反向传播更新的。动量更新会使得θk的演化比θq更加平稳。
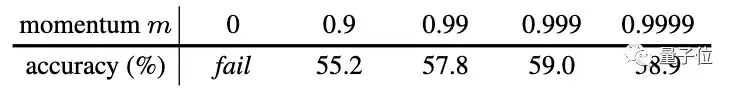
在实验中,研究人员还发现,相对较大的动量(m=0.999)会比较小的动量(m=0.9)要好得多。这表明缓慢演变的键编码器是利用队列的关键所在。
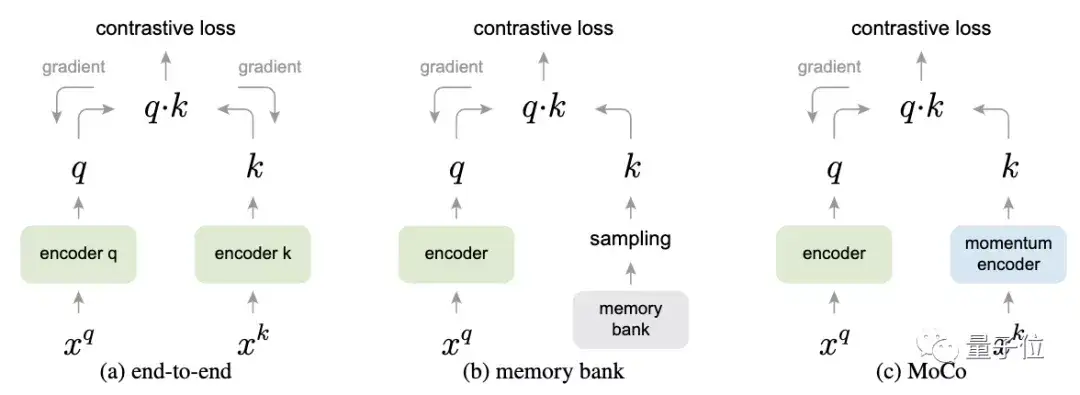 △三种不同对比损失机制,仅展示一对查询和键的关系
△三种不同对比损失机制,仅展示一对查询和键的关系
从这张图中,可以看到三种不同对比损失机制的不同。
端到端方法,是通过反向传播对计算查询和键的表征进行端到端更新。
Memory bank方法中,键的表征是从存储库中提取的。
而MoCo方法则通过基于动量更新的编码器对键进行动态编码,并维持键的队列。
实验结果
MoCo的表现究竟如何,还是要用数据说话。
研究团队在ImageNet-1M和Instagram-1B这两个数据集上进行了测试。
ImageNet-1M是ImageNet的训练集,包含1000种不同类别的128万张图片。而Instagram-1B数据集则包含10亿(940M)Instagram上的公开图像。
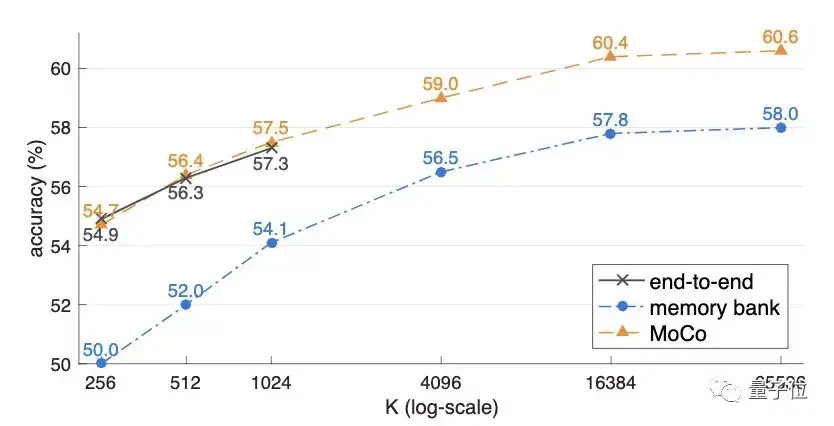
在三种不同机制的对比中,字典规模越大,三种方法的表现就越好。
当K较小时,端到端方法的表现与MoCo差不多,但其批处理大小受限,在8个32GB的V100上,最大的mini-batch仅为1024。并且,即使存储空间足够大,由于端到端方法必须满足线性学习率缩放规则,否则精度会下降,其增长趋势能否推及到更大规模是存疑的。
而memory bank的准确率则始终比MoCo低了2%以上。
在ImageNet上,MoCo表现出色。
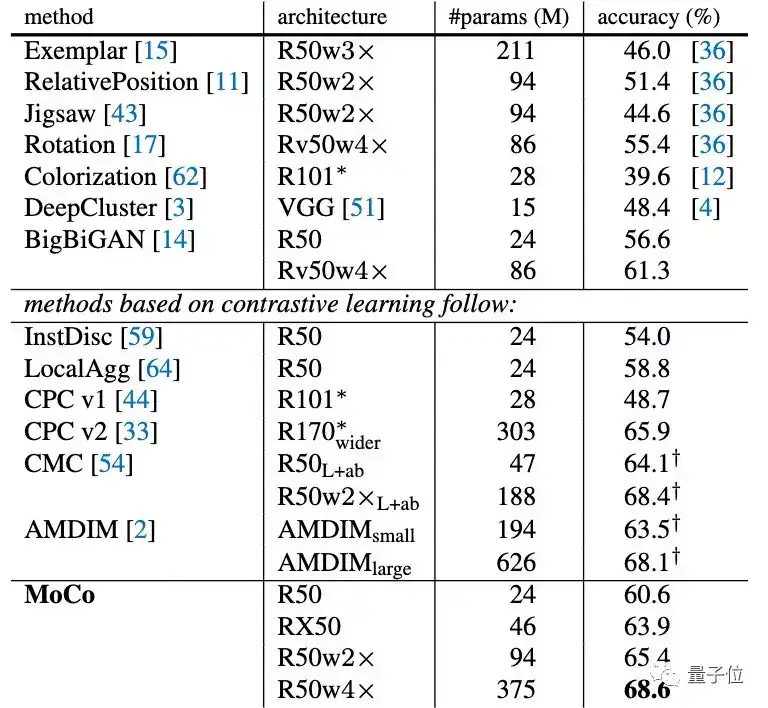
并且在针对不同的任务进行微调之后,MoCo可以很好地迁移到下游任务中,表现甚至优于有监督预训练模型。
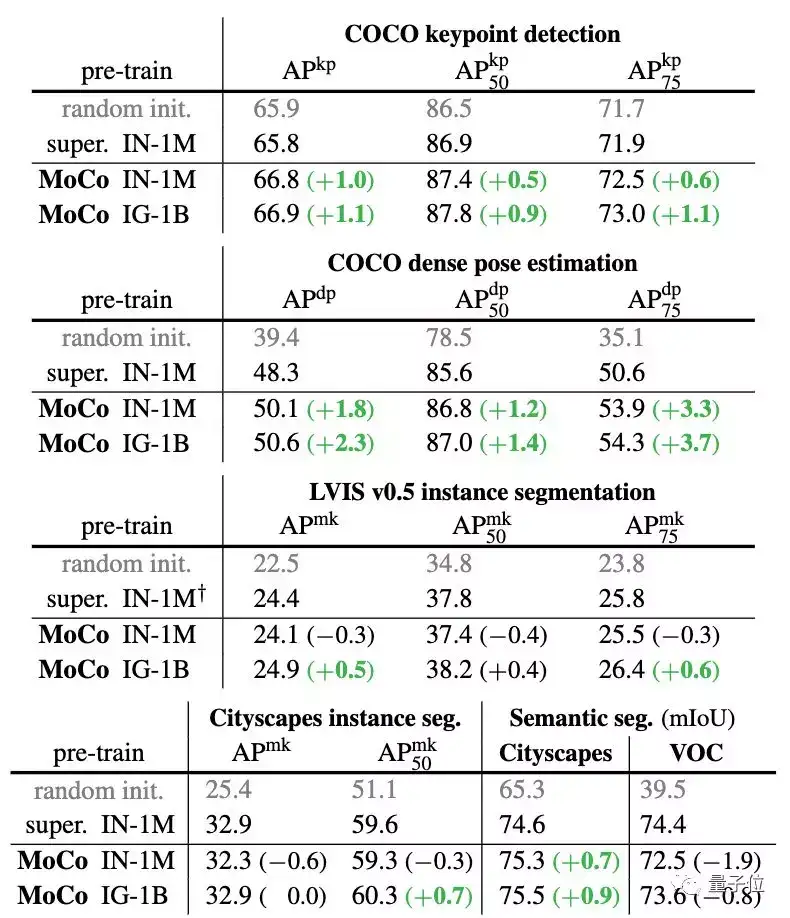
而PASCAL VOC,COCO等其他数据集上的7种检测/细分任务中,MoCo的表现也优于其他有监督预训练模型。甚至有十分明显的提升。

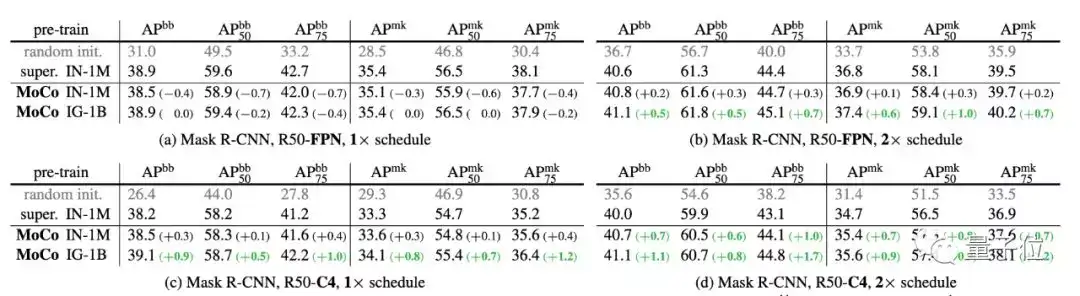
另外,在Instagram语料库上进行预训练的MoCo性能始终优于在ImageNet上训练的结果,这表明MoCo非常适合大型的、相对未整理的数据。
研究团队
论文的研究团队,来自Facebook AI研究院(FAIR)。
一作何恺明,想必大家都不陌生。作为Mask R-CNN的主要提出者,他曾三次斩获顶会最佳论文。

何恺明大神加持,论文的其他几位作者实力也不容小觑。
Haoqi Fan,毕业于卡内基梅隆大学机器人学院,是FAIR的研究工程师。研究领域是计算机视觉和深度学习。有多篇论文入选ICCV、CVPR、AAAI等国际顶会。

吴育昕,FAIR研究工程师,本科毕业于清华大学,2017年于卡内基梅隆大学获得计算机视觉硕士学位。本科期间就曾在谷歌、旷视实习。

谢赛宁,本科毕业于上海交通大学,18年获加州大学圣迭戈分校CS博士学位。现在是FAIR的研究科学家。
另外一位论文作者Ross Girshick,同样是FAIR的研究科学家。博士毕业于芝加哥大学,曾在UC伯克利担任博士后研究员。

传送门
论文地址:
https://arxiv.org/abs/1911.05722
— 完 —
量子位 · QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态
戳右上角「+关注」获取最新资讯↗↗
如果喜欢,请分享or点赞吧~比心❤
VGG更早些时候 已经在video的action recognition上尝试了用InfoNCE的算法,也是work的。https://arxiv.org/abs/1909.04656
虽然VGG基本不做PR,但论文值得一读。project page: http://www.robots.ox.ac.uk/~vgg/research/DPC/

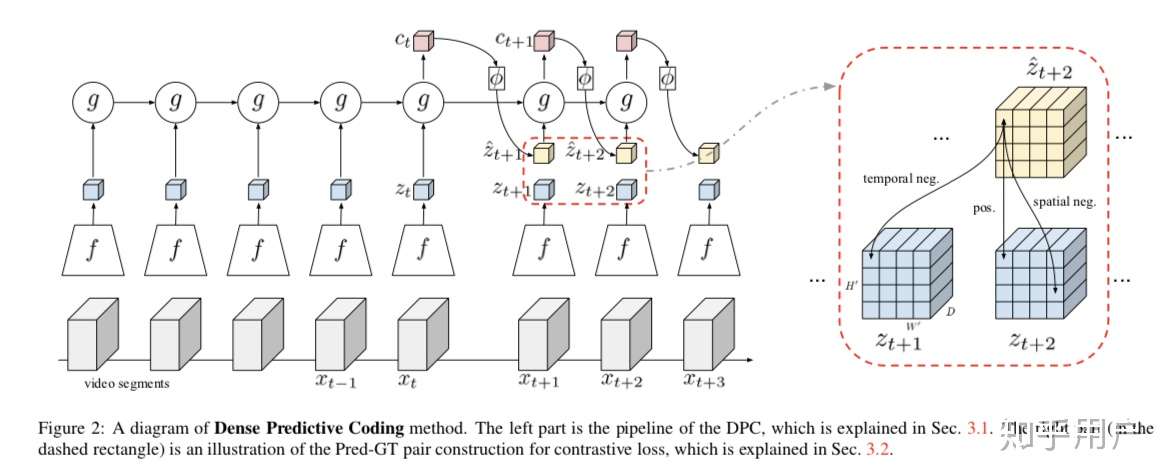
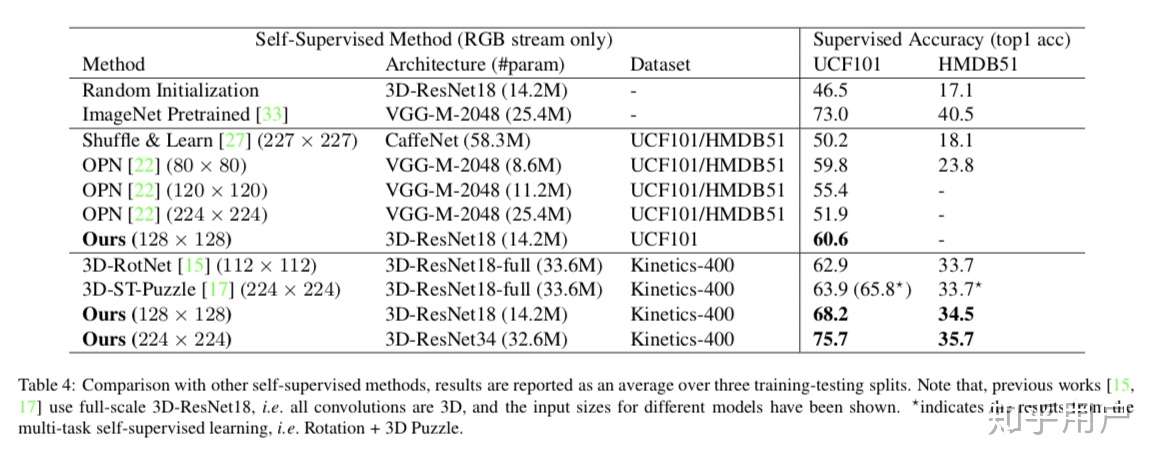
前两天刚看到google的论文,没几天就是facebook的,竞争很明显啊,google的teacher和student的结构对工业数据很有借鉴意义,马上就采用了,效果是有的,facebook的还在看
占个坑,一周后慢慢写,准备分享一下几条思路的文献,只回顾不评价,读者自己可能会发现一些有趣的事实。我觉得一些看上去松散的文献之间有着非常有趣的紧密联系。
- Contrastive XXX
- Score Function
- Momentum & Dictionary
- Representation learning
umsupeevised learning超过supervised learning?不是。
路上简单看了下,应该是一种self-supervised learning方法。
作为废柴抛砖引玉一下, self-supervised learning除了能够训出更好的预训练模型,还能做什么?
萌新弱问一下,moco官方repo里面,moco/builder.py,63行的keys.T是不是写错了。。。
更新,没有,低版本里没有T转置功能,之前以为是上面代码class里的属性。
感觉这篇文章最有价值的在于用无监督预训练上面,局限性还是很强。实际生产中,需要做outlier的识别,小样本学习这篇文章都没解决好,还是偏大问题的解决,可能大佬文章定位就是这样的。说实话,如果不是性能骤提的技术在我看来落到工业界都很尴尬,数下来,性能骤提的方法有relu, bn, faster rcnn, mask rcnn,kaiming占了两个也是厉害了
This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.
---摘要里最后这句,脑子里蹦出来星球大战片首,躺着出字幕的画面