TensorFlow技术内幕(七):模型优化之XLA(上)
本章中我们分析一下TensorFlow的XLA(Accelerated Linear Algebra 加速线性代数)的内核实现。代码位置在tensorflow/compiler.
XLA
在XLA技术之前,TensorFlow中计算图的执行是由runtime(运行时)代码驱动的:runtime负责加载计算图定义、创建计算图、计算图分区、计算图优化、分配设备、管理节点间的依赖并调度节点kernel的执行;计算图是数据部分,runtime是代码部分。在第五章session类的实现分析中,我们已经比较详细的分析了这个过程。在XLA出现之后,我们有了另一个选择,计算图现在可以直接被编译成目标平台的可执行代码,可以直接执行,不需要runtime代码的参与了。
本章我就来分析一下XLA是如何将tensorflow.GraphDef编译成可执行代码的。
目前XLA提供了AOT(提前编译)和JIT(即时编译)两种方式。
AOT
在编译技术里,AOT(提前编译)方式就是在代码执行阶段之前全部编译成目标指令,进入执行阶段后,不再有编译过程发生。
tensorflow的官网已经介绍了一个AOT的使用例子,这里引用一下这个例子,代码位于tensorflow/compiler/aot/tests/make_test_graphs.py,函数tfmatmul构建了一个简单的网络如下:
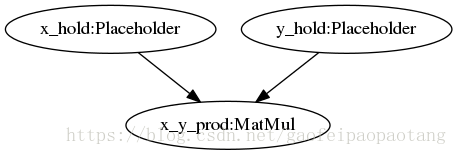
例子中,我们将使用XLA的AOT方式将这计算图编译成可执行文件,需要四步:
步骤1:编写配置
配置网络的输入和输出节点,对应生成函数的输入输出参数。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
步骤2:使用tf_library构建宏来编译子图为静态链接库
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
步骤3:编写代码以调用子图
第二步会生成一个头文件和Object文件,头文件test_graph_tfmatmul.h的内容如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
引用头文件,编写使用端代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
步骤4:使用cc_binary创建最终的可执行二进制文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
四步编译出了可执行的文件,但是其实第二步中,tf_library宏的输出就是计算图对应的可执行文件了,包含一个头文件和Object文件。 所以计算图的编译工作主要在tf_library完成的,我们来分析一下tf_library的实现, tf_library定义在文件tensorflow/compiler/aot/tfcompile.bzl中:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
上面我节选了tf_library代码中关键的一步,这步调用tfcompile_tool命令行工具,生成头文件和二进制问题。可以看到调用tfcompile_tool的命令行包括–graph,–config等等。
tfcompile_tool的入口main函数定义在tensorflow/compiler/aot/tfcompile_main.cc中,编译过程主要分为四步:
1、由GraphDef构建tensorflow.Graph。
2、调用xla.XlaCompiler.CompileGraph,将tensorflow.Graph编译为xla.Computation。
3、调用xla.CompileOnlyClient.CompileAheadOfTime函数,将xla.Computation编译为可执行代码。
4、保存编译结果到头文件和object文件
TensorFlow目前支持的AOT编译的平台有x86-64和ARM.
JIT
JIT全称Just In Time(即时).在即时编译中,计算图在不会在运行阶段前被编译成可执行代码,而是在进入运行阶段后的适当的时机才会被编译成可执行代码,并且可以被直接调用了。
关于JIT编译与AOT编译优缺点的对比,不是本章的主题,限于篇幅这里不做过多的分析了。我们直接来看TensorFlow中JIT的实现。
Python API中打开JIT支持的方式有一下几种:
方式一、通过Session设置:
这种方式的影响是Session范围的,内核会编译尽可能多的节点。
- 1
- 2
- 3
- 4
- 5
方式二、通过tf.contrib.compiler.jit.experimental_jit_scope():
这种方式影响scope内的所有节点,这种方式会对Scope内的所有节点添加一个属性并设置为true: _XlaCompile=true.
- 1
- 2
- 3
- 4
- 5
- 6
方式三、通过设置device:
通过设置运行的Device来启动JIT支持。
- 1
- 2
接下来我们来分析一下这个问题:上面的这些接口层的设置,最终是如何影响内核中计算图的计算的呢?
首先来回忆一下 TensorFlow技术内幕(五):核心概念的实现分析 的图4,session的本地执行这一节:graph在运行前,需要经过一系列优化和重构(包括前一章中分析的grappler模块的优化)。其中一步涉及到类:tensorflow.OptimizationPassRegistry,通过此类我们可以运行其中注册的tensorflow.GraphOptimizationPass的子类,每一个子类都是实现了一种graph的优化和重构的逻辑。XLA JIT 相关的Graph优化和重构,也是通过这个入口来执行的。
JIT相关的tensorflow.GraphOptimizationPass注册代码在:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
可以看到JIT编译相关的tensorflow.GraphOptimizationPass有三个:
1、tensorflow.MarkForCompilationPass:
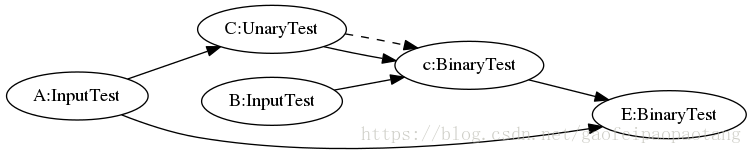
上面提到的开启JIT的三种设置方式,就是在此类中进行检查的。通过检查这些设置,此类首先会挑选出所有开启JIT并且目前版本支持JIT编译的节点,并且运行聚类分析,将这些等待JIT编译的节点分到若干个Cluster中,看一下下面的例子:


B,C节点被标记到cluster 1,E,F节点被标记到cluster 0. A,E应为不支持编译所以没有被分配cluster.
2、tensorflow.EncapsulateSubgraphsPass:
这一步优化分三步,
第一步 :为上一个优化类MarkForCompilationPass mark形成的cluster分别创建对应的SubGraph对象。
第二步:为每个SubGraph对象创建对应的FunctionDef,并将创建的FunctionDef添加到FunctionLibrary中。
这里补充一下TensorFlow中Funtion的概念,FucntionDef的定义如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Function可以看做一个独立的计算图,node_def就是这个子图包含的所有节点。Function可以被实例化和调用,方式是向调用方的计算图中插入一个Call节点,这类节点的运算核(OpKernel)是CallOp:
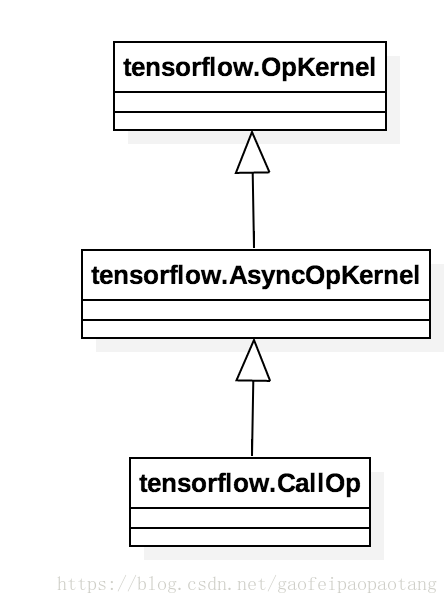
我们知道计算图的计算最终是由Executor对象驱动的,CallOp是连接调用方计算图的Executor和Function内计算图的桥梁:CallOp对外响应Executor的调用,对内会为每次调用创建一个独立的Executor来驱动Function内部计算图的运算。
第三步:重新创建一张新的计算图,首先将原计算图中没有被mark的节点直接拷贝过来,然后为每个SubGraph对应的Function创建CallOp节点,最后创建计算图中数据和控制依赖关系。
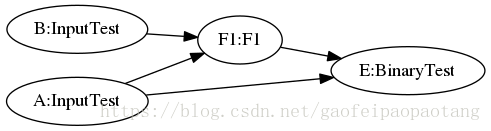
下面的例子中,就将C和c节点一起,替换成了F1节点,调用了Function F1:
3、tensorflow.BuildXlaLaunchOpsPass:
经过EncapsulateSubgraphsPass优化的计算图中的function call节点全部替换成xlalaunch节点。
JIT的关键就是这个xlalaunch节点。xlalaunch节点节点的运算名为”_XlaLaunch”,运算核是XlaLocalLaunchOp,按照运算核的要求它的父类也是OpKernel。
XlaLocalLaunchOp对外响应Executor的调用请求,对内调用JIT相关API类编译和执行FunctionDef。当然对编译结果会有缓存操作,没必要每次调用都走一次编译过程:
步骤一:调用XlaCompilationCache的将FunctionDef编译为xla.LocalExecutable。在cache没命中的情况下,会调用xla.LocalClient执行真正的编译
步骤二:调用xla.LocalExecutable.Run
JIT方式目前支持的平台有X86-64, NVIDIA GPU。
小结
以上分析的是XLA在TensorFlow中的调用方式:AOT方式和JIT方式。
两种方式下都会将整个计算图或则计算图的一部分直接编译成可执行代码。两则的区别也是比较明显的,除了编译时机不一样外,还有就是runtime(运行时)的参与程度。AOT中彻底不需要运行时的参与了,而JIT中还是需要运行时参与的,但是JIT会优化融合原计算图中的节点,加入XlaLaunch节点,来加速计算图的执行。
后面我们会详细分析一下XLA这个编译器的内部实现。
TensorFlow技术内幕(八):模型优化之XLA(下)
上一章我们分析了XLA在TensofFlow中的两种调用方式AOT和JIT,本章分析XLA编译器的实现。
LLVM
提到编译器就不得不提大名鼎鼎的LLVM。LLVM是一个编译器框架,由C++语言编写而成,包括一系列分模块、可重用的编译工具。
LLVM框架的主要组成部分有:
-
前端:负责将源代码转换为一种中间表示
-
优化器:负责优化中间代码
-
后端:生成可执行机器码的模块
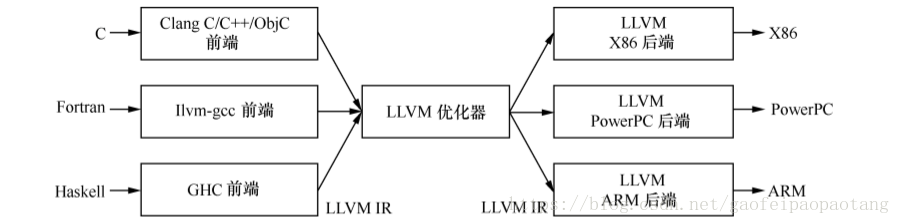
LLVM为不同的语言提供了同一种中间表示LLVM IR,这样子如果我们需要开发一种新的语言的时候,我们只需要实现对应的前端模块,如果我们想要支持一种新的硬件,我们只需要实现对应的后端模块,其他部分可以复用。
XLA目录结构
XLA的实现目录是tensorflow/compiler,目录结构如下:
XLA编译
XLA也是基于LLVM框架开发的,前端的输入是Graph,前端没有将Graph直接转化为LLVM IR,而是转化为了XLA的自定义的中间表示HLO IR.并且为HLO IR设计了一系列的优化器。经过优化的HLO IR接下来会被转化为LLVM IR。
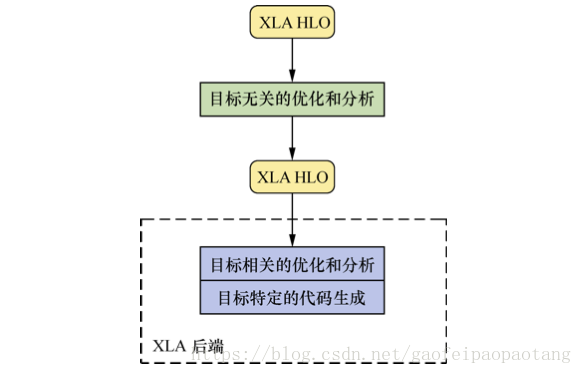
具体来说包含了下列几步:
-
步骤一:由GraphDef创建Graph
-
步骤二:由tensorflow.Graph编译为HLO IR
-
步骤三:分析与优化HLO IR
-
步骤四:由HLO IR转化为llvm IR
-
步骤五:分析与优化llvm IR
-
步骤六:生成特定平台的二进制文件
AOT
AOT编译流程图:
对照图2来分析一下AOT编译流程:
-
tensorflow.XlaCompiler.CompilerGraph函数将Graph编译成XLA的中间表示xla.UserComputation.
-
tensorflow.XlaCompiler.CompilerGraph会创建Executor来执行待编译的Graph,通过绑定设备,为所有节点的创建运算核都是专门设计用来编译的,基类是tensorflow.XlaOpKernel.
-
tensorflow.XlaOpKernel的子类需要实现Compile接口,通过调用xla.ComputeBuilder接口,将本节点的运算转化为Xla指令(instruction).
-
xla.ComputeBuilder是对xla.Client的调用封装,通过本接口创建的xla指令(instruction)的操作,最终都会通过xla.Client传输到xla.Service.
-
xla.Client 和 xla.Service 支持单机模式和分布式模式,实际的编译过程发生在Service端.
-
AOT编译中,用到的是 xla.CompileOnlyClient 和 xla.CompileOnlyService,分别是xla.Client和xla.Service的实现类.
-
可以看到,图2中的第一个循环(loop for every node)会为每个node生成一系列xla指令(instruction),这些指令最终会被加入xla.UserComputation的指令队列里。
-
接下来xla.CompileOnlyClient.CompileAheadOfTime会将xla.UserComputation编译为可执行代码.
-
xla.ComputationTracker.BuildHloModule函数会将所有的xla.UserComputation转化为xla.HloComputation,并为之创建xla.HloModule.
-
至此,Graph 到 HLO IR 的转化阶段完成。
-
HLO IR进入后续的编译过程,根据平台调用不同平台的具体编译器实现类,这里我们以xla.CpuComiler为例来分析.
-
xla.CpuComiler的输入是xla.HloModule,首先会调用RunHloPasses创建HloPassPipeline,添加并运行一系列的HloPass.
-
每一个HloPass都实现了一类HLO指令优化逻辑。通常也是我们比较关心的逻辑所在,包含单不限于图中列举出来的
xla.AlebraicSimplifier(代数简化),xla.HloConstantFolding(常量折叠),xla.HloCSE(公共表达式消除)等。 -
HloPassPipeline优化HLO IR之后,将创建xla.cpu.IrEmitter,进入图2中的第三个循环处理逻辑(loop for every computation of module):将xla.HloModule中的每个xla.HloComputation转化为llvm IR表示,并创建对应的llvm.Module.
-
至此,Hlo IR 到 llvm IR的转化阶段完成,后面进入llvm IR的处理阶段。
-
创建xla.cpu.CompilerFunctor将llvm IR转化为最终的可执行机器代码llvm.object.ObjectFile.中间会调用一系列的llvm ir pass对llvm ir进行优化处理。
-
至此,llvm ir到可执行机器码的转化阶段完成。
JIT
JIT编译流程图:
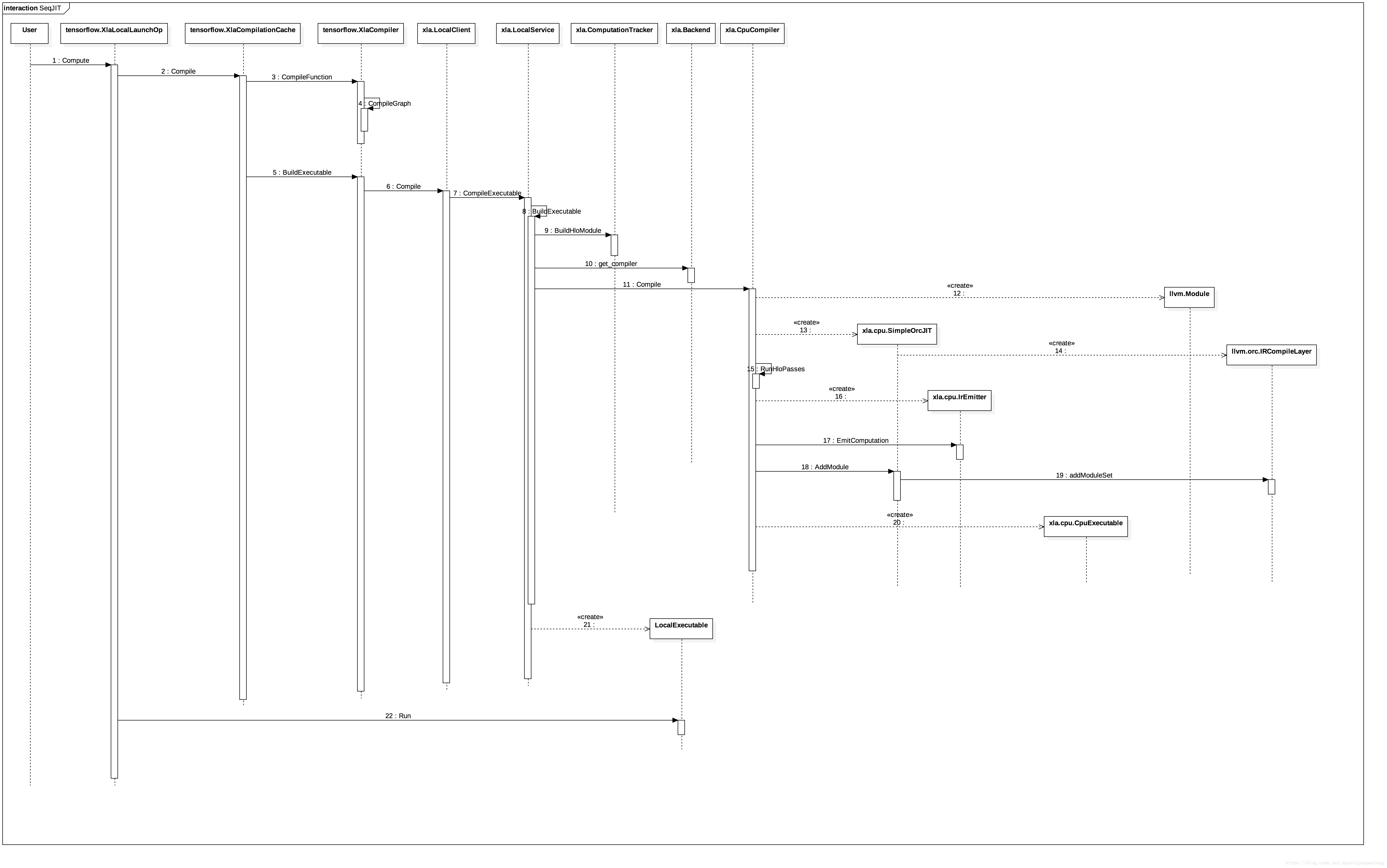
JIT对比AOT来说,过程比较类似,略过共同的部分,我们来分析一下:
-
JIT调用方式的入口在运算核tensorflow.XlaLocalLaunchOp.Compute,tensorflow.XlaLocalLaunchOp是连接外部Graph的Executor和内部JIT调用的桥梁。
-
如果被调用的计算图缓存不命中,则会调用xla.XlaCompile进行实际的编译。
-
编译过程类似AOT,不同之处主要在于:首先这次调用的Client和Service的实现类是xla.LocalClient和xla.LocalService;其次,llvm ir到机器码的编译过程,这次是通过xla.cpu.SimpleOrcJIT完成的,它将llvm ir编译为可执行代码,并可被立即调用。
-
可执行机器码后续会被封装为xla.LocalExecutale
-
调用xla.LocalExecutable的如后函数Run.