协程Coroutine:
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。比如子程序A、B:
def A():
print '1'
print '2'
print '3'
def B():
print 'x'
print 'y'
print 'z'
假设由协程执行,在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A,结果可能是:
1
2
x
y
3
z
但是在A中是没有调用B的,所以协程的调用比函数调用理解起来要难一些。
看起来A、B的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
协程缺点:
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python对协程的支持还非常有限,用在generator中的yield可以一定程度上实现协程。虽然支持不完全,但已经可以发挥相当大的威力了。
=========================================================================================================================
Greenlet实现协程
from greenlet import greenlet #greenlet手动切换 gevent(自动切换) 封装了 greenlet
def test1():
print(12)
gr2.switch()
print(34)
gr2.switch()
def test2():
print(56)
gr1.switch()
print(78)
gr1=greenlet(test1) #起了两个协程gr1 gr2
gr2=greenlet(test2)
gr1.switch()
执行结果:两个函数执行过程中切换
12
56
34
78
Gevent实现协程
import gevent #gevent 通过模拟io操作 def func1(): print('执行func1') gevent.sleep(2) print('继续执行func1...') def func2(): print('执行func2') gevent.sleep(1) print('继续执行func2...') def func3(): print("执行func3") gevent.sleep(0.5) print("继续执行func3") gevent.joinall([ gevent.spawn(func1), gevent.spawn(func2), gevent.spawn(func3), ])
执行结果
执行func1
执行func2
执行func3
继续执行func3
继续执行func2...
继续执行func1...
在遇到真实IO操作时,需要将IO操作和gevent关联起来,让gevent知道产生的IO操作,这时候gevent才会切换。
from urllib import request import gevent,time from gevent import monkey monkey.patch_all()#吧当前程序所有的有可能io操作的单独坐上标记 需要将IO操作和gevent关联起来,让gevent知道产生的IO操作,这时候gevent才会切换。 def f(url): print('get:%s'%url) resp=request.urlopen(url) data=resp.read() print("%d bytes receve from %s"%(len(data)),url) urls=[ 'https://www.python.org/', 'https://www.yahoo.com', 'https://github.com' ] time_start=time.time() for url in urls: f(url) print("同步cost",time.time()-time_start) async_time=time.time() gevent.joinall( [ gevent.spawn(f,urls[0]), gevent.spawn(f,urls[1]), gevent.spawn(f,urls[2]), ] ) print("异步cost",time.time()-async_time)
执行结果:
同步6秒多
异步2秒多
通过gevent实现单线程下的多socket并发
server side
import sys import socket import time import gevent from gevent import socket,monkey monkey.patch_all() def server(port): s = socket.socket() s.bind(('0.0.0.0', port)) s.listen(500) while True: cli, addr = s.accept() gevent.spawn(handle_request, cli) def handle_request(conn): try: while True: data = conn.recv(1024) print("recv:", data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) except Exception as ex: print(ex) finally: conn.close() if __name__ == '__main__': server(8001)
client side
import socket HOST = 'localhost' # The remote host PORT = 8001 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"),encoding="utf8") s.sendall(msg) data = s.recv(1024) #print(data) print('Received', repr(data)) s.close()
IO操作:

IO(Input / Output,输入 / 输出)即数据的读取(接收)或写入(发送)操作,通常用户进程中的一个完整IO分为两阶段:用户进程空间 < -->内核空间、内核空间 < -->设备空间(磁盘、网络等)。IO有内存IO、网络IO和磁盘IO三种,通常我们说的IO指的是后两者。
LINUX中进程无法直接操作I / O设备,其必须通过系统调用请求kernel来协助完成I / O动作;内核会为每个I / O设备维护一个缓冲区。
对于一个输入操作来说,进程IO系统调用后,内核会先看缓冲区中有没有相应的缓存数据,没有的话再到设备中读取,因为设备IO一般速度较慢,需要等待;内核缓冲区有数据则直接复制到进程空间。
所以,对于一个网络输入操作通常包括两个不同阶段:
(1)等待网络数据到达网卡→读取到内核缓冲区,数据准备好;
(2)从内核缓冲区复制数据到进程空间。
2、5种IO模型
《UNIX网络编程》说得很清楚,5种IO模型分别是阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动的IO模型、异步IO模型;前4种为同步IO操作,只有异步IO模型是异步IO操作。下面这样些图,是它里面给出的例子:接收网络UDP数据的流程在IO模型下的分析,在它的基础上再加以简单描述,以区分这些IO模型。
阻塞IO模型

进程发起IO系统调用后,进程被阻塞,转到内核空间处理,整个IO处理完毕后返回进程。操作成功则进程获取到数据。
1、典型应用:阻塞socket。
2、特点:
进程阻塞挂起不消耗CPU资源,及时响应每个操作;
实现难度低、开发应用较容易;
适用并发量小的网络应用开发;
不适用并发量大的应用:因为一个请求IO会阻塞进程,所以,得为每请求分配一个处理进程(线程)以及时响应,系统开销大。
非阻塞IO模型

进程发起IO系统调用后,如果内核缓冲区没有数据,需要到IO设备中读取,进程返回一个错误而不会被阻塞;进程发起IO系统调用后,如果内核缓冲区有数据,内核就会把数据返回进程。
对于上面的阻塞IO模型来说,内核数据没准备好需要进程阻塞的时候,就返回一个错误,以使得进程不被阻塞。
1、典型应用:socket是非阻塞的方式(设置为NONBLOCK)
2、特点:
进程轮询(重复)调用,消耗CPU的资源;
实现难度低、开发应用相对阻塞IO模式较难;
适用并发量较小、且不需要及时响应的网络应用开发;
IO复用模型
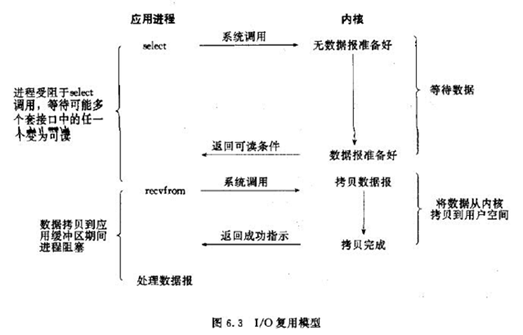
多个的进程的IO可以注册到一个复用器(select)上,然后用一个进程调用该select, select会监听所有注册进来的IO;
如果select没有监听的IO在内核缓冲区都没有可读数据,select调用进程会被阻塞;而当任一IO在内核缓冲区中有可数据时,select调用就会返回;
而后select调用进程可以自己或通知另外的进程(注册进程)来再次发起读取IO,读取内核中准备好的数据。
可以看到,多个进程注册IO后,只有另一个select调用进程被阻塞。
1、典型应用:select、poll、epoll三种方案,nginx都可以选择使用这三个方案;
2、特点:
专一进程解决多个进程IO的阻塞问题,性能好;Reactor模式;
实现、开发应用难度较大;
适用高并发服务应用开发:一个进程(线程)响应多个请求;
3、select、poll、epoll
Linux中IO复用的实现方式主要有select、poll和epoll:
Select:注册IO、阻塞扫描,监听的IO最大连接数不能多于FD_SIZE;
Poll:原理和Select相似,没有数量限制,但IO数量大扫描线性性能下降;
Epoll :事件驱动不阻塞,mmap实现内核与用户空间的消息传递,数量很大,Linux2.6后内核支持;
信号驱动IO模型
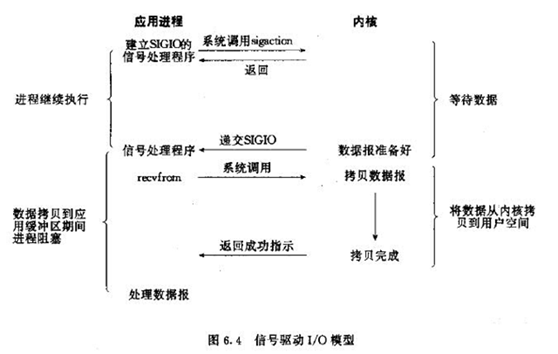
当进程发起一个IO操作,会向内核注册一个信号处理函数,然后进程返回不阻塞;当内核数据就绪时会发送一个信号给进程,进程便在信号处理函数中调用IO读取数据。
特点:回调机制,实现、开发应用难度大;
异步IO模型
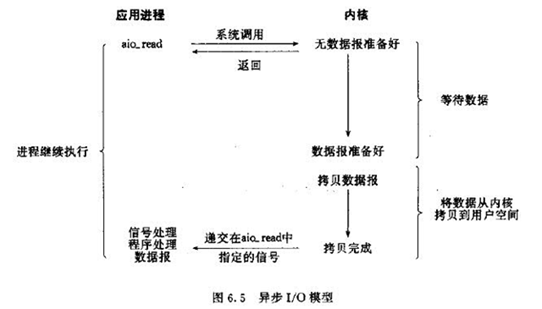
当进程发起一个IO操作,进程返回(不阻塞),但也不能返回果结;内核把整个IO处理完后,会通知进程结果。如果IO操作成功则进程直接获取到数据。
1、典型应用:JAVA7AIO、高性能服务器应用
2、特点:不阻塞,数据一步到位;Proactor模式;
需要操作系统的底层支持,LINUX2.5版本内核首现,2.6版本产品的内核标准特性;实现、开发应用难度大;非常适合高性能高并发应用;
IO模型比较
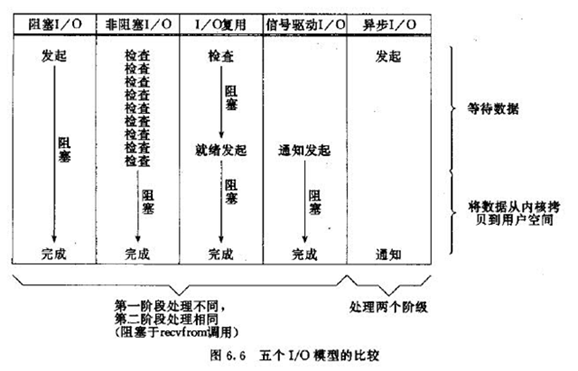
阻塞IO调用和非阻塞IO调用、阻塞IO模型和非阻塞IO模型
注意这里的阻塞IO调用和非阻塞IO调用不是指阻塞IO模型和非阻塞IO模型:
阻塞IO调用 :在用户进程(线程)中调用执行的时候,进程会等待该IO操作,而使得其他操作无法执行。
非阻塞IO调用:在用户进程中调用执行的时候,无论成功与否,该IO操作会立即返回,之后进程可以进行其他操作(当然如果是读取到数据,一般就接着进行数据处理)。
这个直接理解就好,进程(线程)IO调用会不会阻塞进程自己。所以这里两个概念是相对调用进程本身状态来讲的。
从上面对比图片来说,阻塞IO模型是一个阻塞IO调用,而非阻塞IO模型是多个非阻塞IO调用+一个阻塞IO调用,因为多个IO检查会立即返回错误,不会阻塞进程。
而上面也说过了,非阻塞IO模型对于阻塞IO模型来说区别就是,内核数据没准备好需要进程阻塞的时候,就返回一个错误,以使得进程不被阻塞。
同步IO和异步IO
同步IO:导致请求进程阻塞,直到I/O操作完成。
异步IO:不导致请求进程阻塞。
上面两个定义是《UNIX网络编程 卷1:套接字联网API》给出的。这不是很好理解,我们来扩展一下,先说说同步和异步,同步和异步关注的是双方的消息通信机制:
同步:双方的动作是经过双方协调的,步调一致的。
异步:双方并不需要协调,都可以随意进行各自的操作。
这里我们的双方是指,用户进程和IO设备;明确同步和异步之后,我们在上面网络输入操作例子的基础上,进行扩展定义:
同步IO:用户进程发出IO调用,去获取IO设备数据,双方的数据要经过内核缓冲区同步,完全准备好后,再复制返回到用户进程。而复制返回到用户进程会导致请求进程阻塞,直到I/O操作完成。
异步IO:用户进程发出IO调用,去获取IO设备数据,并不需要同步,内核直接复制到进程,整个过程不导致请求进程阻塞。
所以, 阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动的IO模型者为同步IO模型,只有异步IO模型是异步IO。
SelectPollEpoll IO多路复用的实现
Select io多路复用的代码实现
server 端
import select import socket import queue server=socket.socket() server.bind(('localhost',9001)) server.listen(1000) server.setblocking(False) msg_dict={} inputs=[server,] #给select传递监控的io链接server 代表自己 #inputs=[server,conn] 如果建立新链接,就把conn放进去 如果返回的是server则新的链接,如果是conn则是有数据来了 outputs=[] # while True: readable,writeable,exceptional=select.select(inputs,outputs,inputs) #outputs 往里放甚么就出来甚么 print(readable,writeable,exceptional) for r in readable: if r is server: conn,addr=server.accept() print("来了新链接",addr) inputs.append(conn)#是因为这个新建立的连接还没发数据过来,现在就接收的话程序就报错了, #所以要想实现这个客户端发数据来时server端能知道,就需要让select再监测这个conn msg_dict[conn]=queue.Queue() #初始化一个队列存储给客户端返回的消息 else: data=r.recv(1024) #这里不用conn.recv原因是,conn指的当前刚建立上的链接,如果是之前建立的链接发过来数据,con只认当前 #新建立的无法之前建立的链接发过来数据 print("来的是数据",data) msg_dict[r].put(data) outputs.append(r) #放入返回的链接队列 # r.send(data) # print("send down") for w in writeable:#要返回给客户端的链接 列表 data_to_client=msg_dict[w].get() w.send(data_to_client) #返回给客户端数据 outputs.remove(w)#确保下次循环的时候writeable不返回已经处理完的连接了 for e in exceptional: if e in outputs: outputs.remove(e) inputs.remove(e) del msg_dict[e]
client端
import socket HOST = 'localhost' # The remote host PORT = 9001 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"), encoding="utf8") s.sendall(msg) data = s.recv(1024) # print(data) print('Received', repr(data)) s.close()
执行结果
/usr/bin/python3.5 /home/cui0x01/PycharmProjects/oldboy/进程_线程/select_server.py [<socket.socket fd=3, family=AddressFamily.AF_INET, type=2049, proto=0, laddr=('127.0.0.1', 9002)>] [] [] 来了新链接 ('127.0.0.1', 57076) [<socket.socket fd=4, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9002), raddr=('127.0.0.1', 57076)>] [] [] 来的是数据 b'1' [] [<socket.socket fd=4, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9002), raddr=('127.0.0.1', 57076)>] [] [<socket.socket fd=3, family=AddressFamily.AF_INET, type=2049, proto=0, laddr=('127.0.0.1', 9002)>] [] [] 来了新链接 ('127.0.0.1', 57078) [<socket.socket fd=5, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9002), raddr=('127.0.0.1', 57078)>] [] [] 来的是数据 b'2' [] [<socket.socket fd=5, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9002), raddr=('127.0.0.1', 57078)>] [] [<socket.socket fd=3, family=AddressFamily.AF_INET, type=2049, proto=0, laddr=('127.0.0.1', 9002)>] [] [] 来了新链接 ('127.0.0.1', 57080) [<socket.socket fd=6, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9002), raddr=('127.0.0.1', 57080)>] [] [] 来的是数据 b'3' [] [<socket.socket fd=6, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9002), raddr=('127.0.0.1', 57080)>] []
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
一 epoll操作过程
epoll操作过程需要三个接口,分别如下
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);1. int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值,参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
当创建好epoll句柄后,它就会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
2. int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
函数是对指定描述符fd执行op操作。
- epfd:是epoll_create()的返回值。
- op:表示op操作,用三个宏来表示:添加EPOLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOLL_CTL_MOD。分别添加、删除和修改对fd的监听事件。
- fd:是需要监听的fd(文件描述符)
- epoll_event:是告诉内核需要监听什么事
3. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待epfd上的io事件,最多返回maxevents个事件。
参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。


复制代码 #_*_coding:utf-8_*_ __author__ = 'Alex Li' import socket, logging import select, errno logger = logging.getLogger("network-server") def InitLog(): logger.setLevel(logging.DEBUG) fh = logging.FileHandler("network-server.log") fh.setLevel(logging.DEBUG) ch = logging.StreamHandler() ch.setLevel(logging.ERROR) formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") ch.setFormatter(formatter) fh.setFormatter(formatter) logger.addHandler(fh) logger.addHandler(ch) if __name__ == "__main__": InitLog() try: # 创建 TCP socket 作为监听 socket listen_fd = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) except socket.error as msg: logger.error("create socket failed") try: # 设置 SO_REUSEADDR 选项 listen_fd.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) except socket.error as msg: logger.error("setsocketopt SO_REUSEADDR failed") try: # 进行 bind -- 此处未指定 ip 地址,即 bind 了全部网卡 ip 上 listen_fd.bind(('', 2003)) except socket.error as msg: logger.error("bind failed") try: # 设置 listen 的 backlog 数 listen_fd.listen(10) except socket.error as msg: logger.error(msg) try: # 创建 epoll 句柄 epoll_fd = select.epoll() # 向 epoll 句柄中注册 监听 socket 的 可读 事件 epoll_fd.register(listen_fd.fileno(), select.EPOLLIN) except select.error as msg: logger.error(msg) connections = {} addresses = {} datalist = {} while True: # epoll 进行 fd 扫描的地方 -- 未指定超时时间则为阻塞等待 epoll_list = epoll_fd.poll() for fd, events in epoll_list: # 若为监听 fd 被激活 if fd == listen_fd.fileno(): # 进行 accept -- 获得连接上来 client 的 ip 和 port,以及 socket 句柄 conn, addr = listen_fd.accept() logger.debug("accept connection from %s, %d, fd = %d" % (addr[0], addr[1], conn.fileno())) # 将连接 socket 设置为 非阻塞 conn.setblocking(0) # 向 epoll 句柄中注册 连接 socket 的 可读 事件 epoll_fd.register(conn.fileno(), select.EPOLLIN | select.EPOLLET) # 将 conn 和 addr 信息分别保存起来 connections[conn.fileno()] = conn addresses[conn.fileno()] = addr elif select.EPOLLIN & events: # 有 可读 事件激活 datas = '' while True: try: # 从激活 fd 上 recv 10 字节数据 data = connections[fd].recv(10) # 若当前没有接收到数据,并且之前的累计数据也没有 if not data and not datas: # 从 epoll 句柄中移除该 连接 fd epoll_fd.unregister(fd) # server 侧主动关闭该 连接 fd connections[fd].close() logger.debug("%s, %d closed" % (addresses[fd][0], addresses[fd][1])) break else: # 将接收到的数据拼接保存在 datas 中 datas += data except socket.error as msg: # 在 非阻塞 socket 上进行 recv 需要处理 读穿 的情况 # 这里实际上是利用 读穿 出 异常 的方式跳到这里进行后续处理 if msg.errno == errno.EAGAIN: logger.debug("%s receive %s" % (fd, datas)) # 将已接收数据保存起来 datalist[fd] = datas # 更新 epoll 句柄中连接d 注册事件为 可写 epoll_fd.modify(fd, select.EPOLLET | select.EPOLLOUT) break else: # 出错处理 epoll_fd.unregister(fd) connections[fd].close() logger.error(msg) break elif select.EPOLLHUP & events: # 有 HUP 事件激活 epoll_fd.unregister(fd) connections[fd].close() logger.debug("%s, %d closed" % (addresses[fd][0], addresses[fd][1])) elif select.EPOLLOUT & events: # 有 可写 事件激活 sendLen = 0 # 通过 while 循环确保将 buf 中的数据全部发送出去 while True: # 将之前收到的数据发回 client -- 通过 sendLen 来控制发送位置 sendLen += connections[fd].send(datalist[fd][sendLen:]) # 在全部发送完毕后退出 while 循环 if sendLen == len(datalist[fd]): break # 更新 epoll 句柄中连接 fd 注册事件为 可读 epoll_fd.modify(fd, select.EPOLLIN | select.EPOLLET) else: # 其他 epoll 事件不进行处理 continue 复制代码
selectors模块
This module allows high-level and efficient I/O multiplexing, built upon the select module primitives. Users are encouraged to use this module instead, unless they want precise control over the OS-level primitives used.
import selectors import socket sel = selectors.DefaultSelector() def accept(sock, mask): conn, addr = sock.accept() # Should be ready print('accepted', conn, 'from', addr,mask) conn.setblocking(False) sel.register(conn, selectors.EVENT_READ, read) #新连接注册read回调函数 def read(conn, mask): data = conn.recv(1024) # Should be ready if data: print('echoing', repr(data), 'to', conn) conn.send(data) # Hope it won't block else: print('closing', conn) sel.unregister(conn) conn.close() sock = socket.socket() sock.bind(('localhost', 9999)) sock.listen(100) sock.setblocking(False) sel.register(sock, selectors.EVENT_READ, accept) while True: events = sel.select() #默认阻塞,有活动连接就返回活动的连接列表 for key, mask in events: callback = key.data #accept callback(key.fileobj, mask) #key.fileobj= 文件句柄
本文转载http://www.cnblogs.com/alex3714/articles/5248247.html