目录:
-
Pytorch数据类型:Tensor与Storage
- 创建张量
- tensor与numpy数组之间的转换
- 索引、连接、切片等
- Tensor操作【add,数学运算,转置等】
- GPU加速
-
自动求导:torch.autograd
- autograd
- Variable
-
读取数据集:torch.utils.data
- 抽象类:torch.utils.data.Dataset
- 采用batch、shuffle或者多线程:torch.utils.data.DataLoader
-
神经网络的构建:nn.Module(模组)
- 参数:torch.nn.Parameter()
- 容器:基类、时序
- 卷积层
- 池化层
- 标准化层
- 循环层
- 激活层:torch.nn.ReLU和torch.nn.functional.relu的效果一样
- Linear层
- Dropout层
- 稀疏层
- 距离函数
- 损失函数
-
神经网络的优化:torch.optim
- 构建优化器
- 设置单独参数
- 单步优化
-
模型的保存和加载:torch.save
一、Pytorch数据类型
1、Tensor张量:torch.Tensor是一种包含单一数据类型元素的多维矩阵。
(1)创建张量------float型、long型、全0张量、随机正态分布张量
-
- float型和long型

-
- 全0张量和正态分布

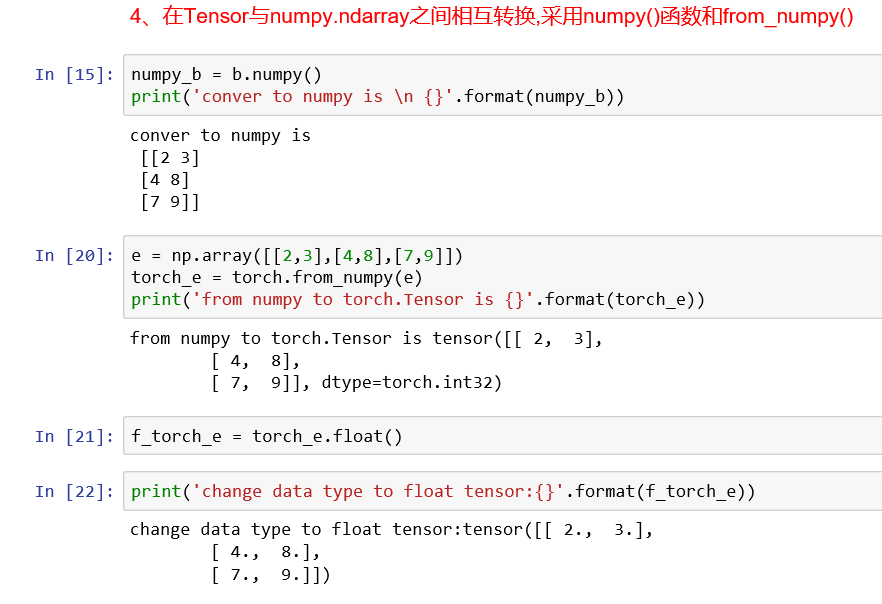
(2)Tensor和numpy之间的转换:
通过a.numpy(),就能将Tensor a转换成numpy数据类型,同时使用torch.from_numpy()就能将numpy转换成tensor,如果需要更改tensor的数据类型,只需要在转换后面加上需要的类型,如想将a的类型转换成float,只需a.float()就可以了。
(3)Tensor的索引、切片、连接、换位:
- 连接:torch.cat(inputs, dimension=0) → Tensor【dimension=0按行连接】


1 >>> x = torch.randn(2, 3) 2 >>> x 3 4 0.5983 -0.0341 2.4918 5 1.5981 -0.5265 -0.8735 6 [torch.FloatTensor of size 2x3] 7 8 >>> torch.cat((x, x, x), 0) 9 10 0.5983 -0.0341 2.4918 11 1.5981 -0.5265 -0.8735 12 0.5983 -0.0341 2.4918 13 1.5981 -0.5265 -0.8735 14 0.5983 -0.0341 2.4918 15 1.5981 -0.5265 -0.8735 16 [torch.FloatTensor of size 6x3] 17 18 >>> torch.cat((x, x, x), 1) 19 20 0.5983 -0.0341 2.4918 0.5983 -0.0341 2.4918 0.5983 -0.0341 2.4918 21 1.5981 -0.5265 -0.8735 1.5981 -0.5265 -0.8735 1.5981 -0.5265 -0.8735 22 [torch.FloatTensor of size 2x9]
- 分块:torch.chunk(tensor, chunks, dim=0) 【tensor (Tensor) 表示待分块的输入张量,chunks (int) 表示 分块的个数,dim (int) 表示 沿着此维度进行分块】
- 聚合:torch.gather(input, dim, index, out=None) → Tensor
- 切片:torch.index_select(input, dim, index, out=None) → Tensor 【input (Tensor) – 输入张量,dim (int) – 索引的轴,index (LongTensor) – 包含索引下标的一维张量,out (Tensor, optional) – 目标张量】
1 >>> x = torch.randn(3, 4) 2 >>> x 3 4 1.2045 2.4084 0.4001 1.1372 5 0.5596 1.5677 0.6219 -0.7954 6 1.3635 -1.2313 -0.5414 -1.8478 7 [torch.FloatTensor of size 3x4] 8 9 >>> indices = torch.LongTensor([0, 2]) 10 >>> torch.index_select(x, 0, indices) 11 12 1.2045 2.4084 0.4001 1.1372 13 1.3635 -1.2313 -0.5414 -1.8478 14 [torch.FloatTensor of size 2x4] 15 16 >>> torch.index_select(x, 1, indices) 17 18 1.2045 0.4001 19 0.5596 0.6219 20 1.3635 -0.5414 21 [torch.FloatTensor of size 3x2]
- 返回非零元素的索引:torch.nonzero
- 切分:torch.split
- 转置:torch.transpose,torch.t【只转置0,1维】
- 压缩:torch.squeeze【将输入张量形状中的
1去除并返回。】

- 扩充:torch.unsqueeze()【对数据维度进行扩充,给指定位置加上维数为1的维度】

(4)Tensor操作:加法【+,add】,转置,索引,数学运算,线性代数,随机数等。
参考:https://pytorch-cn.readthedocs.io/zh/latest/
(5)GPU加速:
如果电脑支持GPU加速,可以Tensor放到GPU上。首先通过torch.cuda.is_available()判断一下是否支持GPU,如果想把tensor a放到GPU上,只需a.cuda()就可将tensor a放到GPU上。

2、Storage数据类型:torch.Storage
一个torch.Storage是一个单一数据类型的连续一维数组。
二、自动求导:torch.autograd
1、autograd包提供了自动求导的功能
在底层,每个原始 autograd 操作符实际上是在 Tensors 上操作的两个函数。forward 函数从输入张量来计算输出张量。backward函数接收输出向量关于某个标量的梯度,然后计算输入张量关于关于同一个标量的梯度。
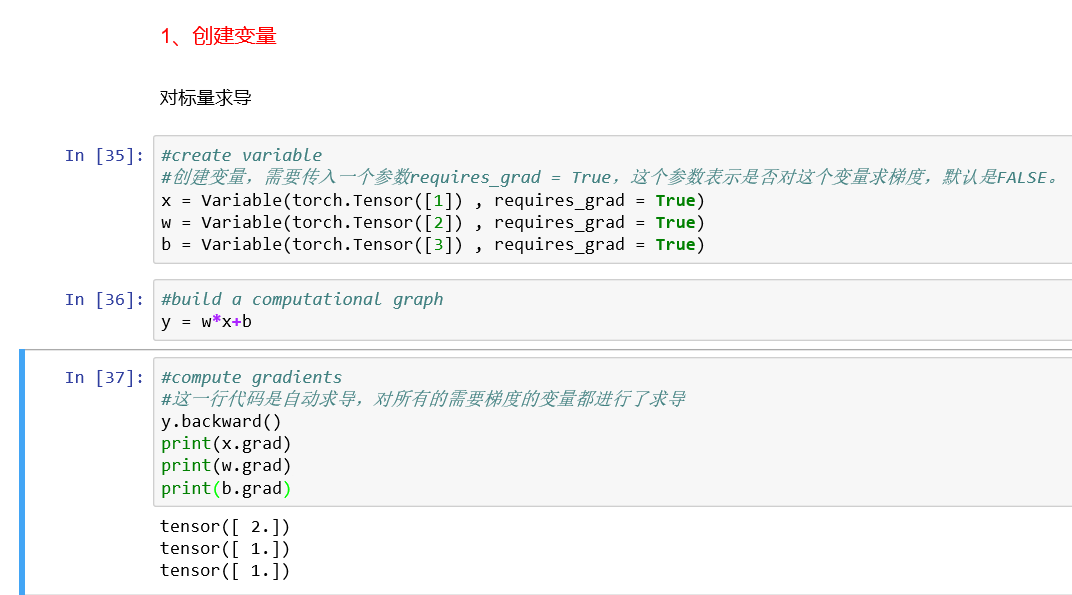
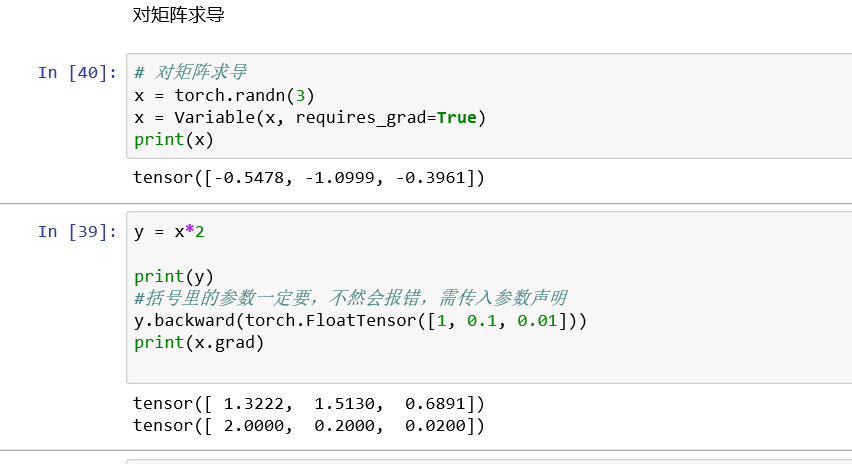
2、Variable(变量):torch.autofrad.Variable
变量和张量本质上没有什么区别,不过变量会被放入计算图中,进行前向传播和后向传播,自动求导。
Variable 在 torch.autograd.Variable 中, 如果 a 是一个张量,使用 Variable(a) 可将其变为 Variable。
Variable 中有三个重要组成性质:data, grad, grad_fn. 通过 data 可以取出 Variable 中的 tensor 数值,grad_fn 得到这个 Variable 的操作.比如通过加减还是乘除得到的, grad 是 Variable 反向传播的梯度.【通过以下代码y.backward()实现】
三、读取数据集:torch.utils.data
- Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。
- DataLoader是一个比较重要的类,它为我们提供的常用操作有:batch_size(每个batch的大小), shuffle(是否进行shuffle操作), num_workers(加载数据的时候使用几个子进程)
1、抽象类:torch.utils.data.Dataset
可以自己定义数据类继承和重写这个抽象类,只需定义__len__和__getitem__这两个函数。
from torch.utils.data import Dataset
import pandas as pd
class myDataset(Dataset):
def __init__(self, csv_file, txt_file, root_dir, other_file):
self.csv_data = pd.read_csv(csv_file)
with open(txt_file, 't') as f:
data_list = f.readlines()
self.txt_data = data_list
self.root_dir = root_dir
def __len__(self):
return len(self.csv_data)
def __getitem__(self, idx):
data = (self.csv_data[idx], self.txt_data[idx])
return data
2、采用batch、shuffle或者多线程:torch.utils.data.DataLoader
采用torch.utils.data.DataLoader定义一个新的迭代器,collate_fn表示如何取样本
dataiter = DataLoader(myDataset, batch_size=2, shuffle=True, collate_fn=default_collate)
torchvision类中的ImageFolder是读取图片的类。
四、神经网络的构建:nn.Module(模组)
激励函数的选择,如果层数较少的神经网络,激励函数有多种选择,在图像卷积神经网络中,激励函数选择ReLu,在循环神经网络中,选择ReL或者Tanh。
所有的层结构和损失函数都来自于torch.nn,所有的模型构建都是从这个基类nn.Module继承的。
1、参数:torch.nn.Parameter()
Variable的一种,常被用于模块参数(module parameter)。
2、容器:
-
所有网络的基类:torch.nn.Module
-
时序容器:torch.nn.Sequential(* args)
3、卷积层:
- torch.nn.Conv1d:一维卷积层
- torch.nn.Conv2d:二维卷积层
- torch.nn.Conv3d:三维卷积层
- torch.nn.ConvTranspose1d:一维解卷积操作
- torch.nn.ConvTranspose2d:二维解卷积操作
- torch.nn.ConvTranspose3d:三维解卷积操作
4、池化层:
- torch.nn.MaxPool1d:1维最大池化
- torch.nn.MaxPool2d:2维最大池化
- torch.nn.MaxPool3d:3维最大池化
- torch.nn.MaxUnpool1d:MaxPool1d的逆过程
- torch.nn.MaxUnpool2d:MaxPool2d的逆过程
- torch.nn.MaxUnpool3d:MaxPool3d的逆过程
- torch.nn.AvgPool1d、torch.nn.AvgPool2d、torch.nn.AvgPool3d:均值池化
5、激活层:
- torch.nn.ReLU
>>> m = nn.ReLU() >>> input = autograd.Variable(torch.randn(2)) >>> print(input) >>> print(m(input))
- torch.nn.Sigmoid
- torch.nn.Tanh
- torch.nn.Softmax
6、标准化层:
- torch.nn.BatchNorm1d、torch.nn.BatchNorm2d、torch.nn.BatchNorm3d
7、循环层:
- torch.nn.RNN:多层RNN
rnn = nn.RNN(10, 20, 2) input = Variable(torch.randn(5, 3, 10)) h0 = Variable(torch.randn(2, 3, 20)) #初始状态 output, hn = rnn(input, h0)
- torch.nn.LSTM:多层LSTM
lstm = nn.LSTM(10, 20, 2) input = Variable(torch.randn(5, 3, 10)) h0 = Variable(torch.randn(2, 3, 20)) #初始化状态 c0 = Variable(torch.randn(2, 3, 20)) #初始化细胞状态 output, hn = lstm(input, (h0, c0))
- torch.nn.GRU:多层GRU
rnn = nn.GRU(10, 20, 2) input = Variable(torch.randn(5, 3, 10)) h0 = Variable(torch.randn(2, 3, 20)) output, hn = rnn(input, h0)
- torch.nn.RNNCell、torch.nn.LSTMCell、torch.nn.GRUCell:一个RNN、LSTM、GRU单元
8、Linear层:回归
- torch.nn.Linear(in_features, out_features, bias=True)
>>> m = nn.Linear(20, 30) >>> input = autograd.Variable(torch.randn(128, 20)) >>> output = m(input) >>> print(output.size())
9、Dropout 层:
- torch.nn.Dropout(p=0.5, inplace=False)
>>> m = nn.Dropout(p=0.2) >>> input = autograd.Variable(torch.randn(20, 16)) >>> output = m(input)
- torch.nn.Dropout2d(p=0.5, inplace=False):通常输入是conv2d模块。
- torch.nn.Dropout3d(p=0.5, inplace=False)
10、稀疏层:一个保存了固定字典和大小的简单查找表。
- torch.nn.Embedding
11、距离函数:
- torch.nn.PairwiseDistance(p=2, eps=1e-06):批计算向量v1, v2之间的距离:
>>> pdist = nn.PairwiseDistance(2) >>> input1 = autograd.Variable(torch.randn(100, 128)) >>> input2 = autograd.Variable(torch.randn(100, 128)) >>> output = pdist(input1, input2)
12、损失函数:
- torch.nn.L1Loss:衡量输入
x(模型预测输出)和目标y之间差的绝对值的平均值的标准。 - torch.nn.MSELoss:创建一个衡量输入
x(模型预测输出)和目标y之间均方误差标准。 - torch.nn.CrossEntropyLoss:此标准将
LogSoftMax和NLLLoss集成到一个类中。 - torch.nn.HingeEmbeddingLoss:这个
loss通常用来测量两个输入是否相似 - torch.nn.MultiLabelMarginLoss:计算多标签分类的
hinge loss(margin-based loss) ,计算loss时需要两个输入
定义完模型, 来定义损失函数, 常见的损失函数都定义在 nn 中.比如均方误差、多分类的交叉熵以及二分类的交叉熵等, 这样我们就能求得输出和真是目标之间的损失函数.如:
criterion = nn.CrossEntropyLoss()
loss = criterion(output, target)
五、神经网络的优化:torch.optim
为了使用torch.optim,你需要构建一个optimizer对象。这个对象能够保持当前参数状态并基于计算得到的梯度进行参数更新。
1、构建optimizer:
- torch.optim.SGD
需要给它一个包含了需要优化的参数(必须都是Variable对象)的iterable。然后,你可以设置optimizer的参 数选项,比如学习率,权重衰减,等等。
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
以上学习率为0.01,动量是0.9的随机梯度下降,在优化之前需要先将梯度归零,即optimizer.zeros(),然后通过loss.backward()反向传播,自动求导得到每个参数的梯度,最后只需要optimizer.step()就可以通过梯度做一步参数更新。
2、为每个参数单独设置选项
Optimizer也支持为每个参数单独设置选项。若想这么做,不要直接传入Variable的iterable,而是传入dict的iterable。每一个dict都分别定 义了一组参数,并且包含一个param键,这个键对应参数的列表。其他的键应该optimizer所接受的其他参数的关键字相匹配,并且会被用于对这组参数的 优化。
当我们想指定每一层的学习率时,这是非常有用的:
optim.SGD([ {'params': model.base.parameters()}, {'params': model.classifier.parameters(), 'lr': 1e-3} ], lr=1e-2, momentum=0.9)
这意味着model.base的参数将会使用1e-2的学习率,model.classifier的参数将会使用1e-3的学习率,并且0.9的momentum将会被用于所 有的参数。
3、进行单次优化
所有的optimizer都实现了step()方法,这个方法会更新所有的参数。它能按两种方式来使用:
- optimizer.step():一旦梯度被如
backward()之类的函数计算好后,我们就可以调用这个函数。例如:
for input, target in dataset: optimizer.zero_grad() output = model(input) loss = loss_fn(output, target) loss.backward() optimizer.step()
- optimizer.step(closure):一些优化算法例如Conjugate Gradient和LBFGS需要重复多次计算函数,因此你需要传入一个闭包去允许它们重新计算你的模型。这个闭包应当清空梯度, 计算损失,然后返回。
for input, target in dataset: def closure(): optimizer.zero_grad() output = model(input) loss = loss_fn(output, target) loss.backward() return loss optimizer.step(closure)
六、模型的保存和加载:
- 在 Pytorch 中使用 torch.save 来保存模型的结构和参数,有两种方式
1. 保存整个模型的结构信息和参数信息, 保存的对象是模型 model ,可以是pth方式,也可以是pkl的方式。即取名为my_model.pkl名称。
2. 保存模型的参数, 保存的对象是模型的状态 model.state_dict()
save 的第一个参数是保存的对象, 第二个是保存的路径及名称
torch.save(model, './model.pth') # 方式1
torch.save(model.state_dict(), './model_state.pth') # 方式2
- 加载模型对应两种保存方式也有两种
1. 加载完整的模型结构和参数信息, 使用 load_model = torch.load(‘model.pth’) 在网络较大的时候记载时间教程, 存储空间较大
2. 加载模型参数信息, 需要先导入模型的结构, 然后通过 model.load_state_dict(torch.load(‘model_state.pth’)) 来导入.
参考:https://blog.csdn.net/broken_promise/article/details/81174760