Faster-RCNN是基于VGG-16的网络结构,Faster-RCNN的提出为了改进Fast-RCNN中存在的问题。Fasr-RCNN中存在了一个较大的问题,就是selective search候选框,Fastr-RCNN中引入了一个专门的生成候选框的区域的神经网络,也就是选择候选框的工作也交给神经网络来做了,这就引入了RPN网络。Faster-RCNN可以简单的看作一个“RPN网络+Fast-RCNN的系统,用RPN网络来代替Fast-RCNN中的selective srarch方法。网络结构如下。

网络中需要的参数:
class Config: def __init__(self): #用来计算anchor尺寸的 self.anchor_box_scales = [128,256,512] self.anchor_box_ratios = [[1,1],[1,2],[2,1]] #缩放尺度600//38 self.rpn_stride =16 #ROIpooling层的输入batch_siez self.num_rois =32 self.verbose =True #正负样本的阈值 self.rpn_min_overlap =0.3 self.rpn_max_overlap = 0.7 #前景背景的阈值 self.classifier_min_overlap =0.1 self.classifier_max_overlap =0.5 self.classifier_regr_std =[8.0,8.0,4.0,4.0] self.std_scaling=4.0
Faster-RCNN网络结构:
def identity_block(input_tensor,kernel_size,filters,stage,block): filters1,filters2,filters3 = filters conv_name_base = "res"+str(stage)+block+"_branch" bn_name_base = "bn"+str(stage)+block+"_branch" x = Conv2D(filters1,(1,1),name=conv_name_base+"2a")(input_tensor) x = BatchNormalization(name=bn_name_base+"2a")(x) x = Activation("relu")(x) x = Conv2D(filters2,kernel_size,padding="same",name=conv_name_base+"2b")(x) x = BatchNormalization(name=bn_name_base+"2b")(x) x = Activation("relu")(x) x = Conv2D(filters3,(1,1),name=conv_name_base+"2c")(x) x = BatchNormalization(name=bn_name_base+"2c")(x) x = add([x,input_tensor]) x = Activation("relu")(x) return x def conv_block(input_tensor,kernel_size,filters,stage,block,strides=(2,2)): filters1,filters2,filters3 =filters conv_name_base = "res" + str(stage) + block + "_branch" bn_name_base = "bn" + str(stage) + block + "_branch" x = Conv2D(filters1,(1,1),strides=strides,name=conv_name_base+"2a")(input_tensor) x = BatchNormalization(name=bn_name_base+"2a")(x) x = Activation("relu")(x) x = Conv2D(filters2,kernel_size,padding="same",name=conv_name_base+"2b")(x) x = BatchNormalization(name=bn_name_base+"2b")(x) x = Activation("relu")(x) x = Conv2D(filters3,(1,1),name=conv_name_base+"2c")(x) x = BatchNormalization(name=bn_name_base+"2c")(x) shortcut = Conv2D(filters3,(1,1),strides=strides,name=conv_name_base+"1")(input_tensor) shortcut = BatchNormalization(name=bn_name_base+"1")(shortcut) x = add([x,shortcut]) x = Activation("relu")(x) return x def ResNet50(inputs): img_input = inputs x = ZeroPadding2D((3,3))(img_input) x = Conv2D(64,(7,7),strides=(2,2),name="conv1")(x) x = BatchNormalization(name="bn_conv1")(x) x = Activation("relu")(x) x = MaxPooling2D((3,3),strides=(2,2),padding="same")(x) x = conv_block(x,3,[64,64,256],stage=2,block="a",strides=(1,1)) x = identity_block(x,3,[64,64,256],stage=2,block="b") x = identity_block(x,3,[64,64,256],stage=2,block="c") x = conv_block(x,3,[128,128,512],stage=3,block="a") x = identity_block(x,3,[128,128,512],stage=3,block="b") x = identity_block(x,3,[128,128,512],stage=3,block="c") x = identity_block(x,3,[128,128,512],stage=3,block="d") x = conv_block(x,3,[256,256,1024],stage=4,block="a") x = identity_block(x,3,[256,256,1024],stage=4,block="b") x = identity_block(x,3,[256,256,1024],stage=4,block="c") x = identity_block(x,3,[256,256,1024],stage=4,block="d") x = identity_block(x,3,[256,256,1024],stage=4,block="e") x = identity_block(x,3,[256,256,1024],stage=4,block="f") return x
RPN网络:
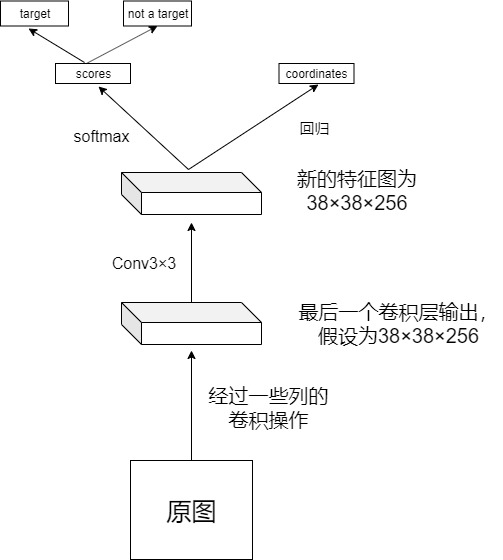
def get_rpn(base_layers,num_anchors): x = Conv2D(512,(3,3),padding="same",activation="relu",kernel_initializer="normal",name="rpn_conv1")(base_layers) x_class = Conv2D(num_anchors,(1,1),activation="sigmoid",kernel_initializer="uniform",name="rpn_out_class")(x) x_regr = Conv2D(num_anchors*4,(1,1),activation="linear",kernel_initializer="zero",name="rpn_out_regr")(x) return [x_class,x_regr,base_layers]
RPN的流程:
1.将最后一个卷积层输出的特征图在进行一次卷积操作得到新的特征图。
2.新的特征图的平面上共有38×38共1444个点,每个点都可以对应到原始图片上,得到9个候选区域,一共可以得到12996个候选区域。
3.计算所有候选区域的scores。
4.把所有超出图片的候选区域都限制在图片区域内,选scores最大的前12000(可以随便设置)个候选区域。
5.剩余的区域中有些候选区域跟其他候选区域有大量重叠,我们可以基于第四步计算的scores,采用非极大值抑制,固定NMS的IOU阈值为0.7,然后再选出scores最大的前2000个候选区域,这2000个候选区域如果于某个真实区域重叠比例大于0.7,集为正样本,如果于任意一个真实区域重叠比例都小于0.3,记为负样本,其余区域不作为样本。
6.在训练RPN层分类回归任务时,我们会随机的抽取256个区域来训练,正负候选区域的比例时1:1,如果正样本数目小于128,用负样本填充。
7.训练最后输出得分类回归任务是,我们随机抽取64个于真实标注框IOU≥0.5的区域作为前景,192个IOU<0.5且≥0.1的区域作为背景来训练。
def calc_rpn(con,img_data,width,height,resized_width,resized_height,img_length_calc_function): #图片的缩放比例为16 downscale =float(con.rpn_stride) anchor_sizes =con.anchor_box_scales anchor_ratios = con.anchor_box_ratios num_anchors =len(anchor_sizes)*len(anchor_ratios) (output_width,output_height) =img_length_calc_function(resized_width,resized_height) #需要的一些参数 y_rpn_overlap =np.zeros((output_height,output_width,num_anchors)) y_is_box_valid=np.zeros((output_height,output_width,num_anchors)) y_rpn_regr =np.zeros((output_height,output_width,num_anchors*4)) #真实框的个数 num_bboxes= len(img_data["bboxes"]) n_anchratios = len(anchor_ratios) #存储anchor与真实框最大的IOU best_iou_for_bbox =np.zeros(num_bboxes).astype(np.float32) best_anchor_for_bbox =-1*np.ones((num_bboxes,4)).astype(int) #存储anchor的位置 best_x_for_bbox =np.zeros((num_bboxes,4)).astype(int) #存储真实框的坐标 best_dx_for_bbox = np.zeros((num_bboxes,4)).astype(np.float32) #记录正样本 num_anchors_for_bbox =np.zeros((num_bboxes)).astype(int) #因为我们计算都是通过resize以后的图像,所以要把x1,x2,y1,y2缩放 gta = np.zeros((num_bboxes,4)) #获得所有真实框 for bbox_num,bbox in enumerate(img_data["bboxes"]): gta[bbox_num,0] = bbox["x1"]*(resized_width/float(width)) gta[bbox_num,1] = bbox["x2"]*(resized_width/float(width)) gta[bbox_num,2] = bbox["y1"]*(resized_height/float(height)) gta[bbox_num,3] = bbox["y2"]*(resized_height/float(height)) #建议框 for anchor_size_idx in range(len(anchor_sizes)): for anchor_ratio_idx in range(n_anchratios): anchor_x = anchor_sizes[anchor_size_idx]*anchor_ratios[anchor_ratio_idx][0] anchor_y = anchor_sizes[anchor_size_idx]*anchor_ratios[anchor_ratio_idx][1] #建议框的左上角右下角的x,y值(对应与原图) for ix in range(output_width): x1_anc = downscale*(ix+0.5)-anchor_x/2 x2_anc = downscale*(ix+0.5)+anchor_x/2 #忽略掉超出的部分 if x1_anc < 0 or x2_anc >resized_ continue for iy in range(output_height): y1_anc =downscale*(iy+0.5)-anchor_y/2 y2_anc =downscale*(iy+0.5)+anchor_y/2 if y1_anc <0 or y2_anc >resized_height: continue #初始值为负样本 bbox_type="neg" #存储最大IOU的值 best_iou_for_loc =0.0 #存储最好的坐标 best_regr=() #计算每个建议框跟所有真实框的iou for bbox_num in range(num_bboxes): curr_iou =iou(gta[bbox_num,0],gta[bbox_num,2],gta[bbox_num,1], gta[bbox_num,3],x1_anc,y1_anc,x2_anc,y2_anc ) if curr_iou > best_iou_for_bbox[bbox_num] or curr_iou>con.rpn_max_overlap: cx = (gta[bbox_num,0]+gta[bbox_num,1])/2.0 cy = (gta[bbox_num,2]+gta[bbox_num,3])/2.0 cxa =(x1_anc+x2_anc)/2.0 cya =(y1_anc+y2_anc)/2.0 tx =(cx-cxa)/(x2_anc-x1_anc) ty =(cy-cya)/(y2_anc-y1_anc) tw =np.log((gta[bbox_num,1-gta[bbox_num,0]])/(x2_anc-x1_anc)) th =np.log((gta[num_bboxes,3]-gta[bbox_num,2])/(y2_anc-y1_anc)) #类别不是背景 if img_data["bboxes"][bbox_num]["class"]!="bg": if curr_iou >best_iou_for_bbox[bbox_num]: best_anchor_for_bbox[bbox_num]=[iy,ix,anchor_ratio_idx,anchor_size_idx] best_iou_for_bbox[bbox_num] =curr_iou best_x_for_bbox[bbox_num,:] =[x1_anc,x2_anc,y1_anc,y2_anc] best_dx_for_bbox[bbox_num,:]=[tx,ty,tw,th] #正样本 if curr_iou > con.rpn_max_overlap: bbox_type = "pos" num_anchors_for_bbox[bbox_num]+=1 if curr_iou >best_iou_for_loc: best_iou_for_loc=curr_iou best_regr =(tx,ty,tw,th) if con.rpn_min_overlap <curr_iou <con.rpn_max_overlap: if bbox_type !="pos": #中立 bbox_type="neutral" #y_is_box_valid是anchor是否可用y_rpn_overlap是anchor是否包含对象 if bbox_type=="neg": y_is_box_valid[iy,ix,anchor_ratio_idx+n_anchratios*anchor_size_idx]=1 y_rpn_overlap[iy,ix,anchor_size_idx+n_anchratios*anchor_size_idx]=0 elif bbox_type=="neutral": y_is_box_valid[iy,ix,anchor_ratio_idx+n_anchratios*anchor_size_idx]=0 y_rpn_overlap[iy,ix,anchor_ratio_idx+n_anchratios*anchor_size_idx]=0 elif bbox_type =="pos": y_is_box_valid[iy,ix,anchor_ratio_idx+n_anchratios*anchor_size_idx]=1 y_rpn_overlap[iy,ix,anchor_ratio_idx+n_anchratios*anchor_size_idx]=1 start =4 *(anchor_ratio_idx+n_anchratios*anchor_size_idx) y_rpn_regr[iy,ix,start:start+4] =best_regr # 这里又出现了一个潜在问题: 可能会有bbox可能找不到心仪的anchor,那这些训练数据就没法利用了, # 因此我们用一个折中的办法来保证每个bbox至少有一个anchor与之对应。 # 下面是具体的方法,比较简单,对于没有对应anchor的bbox,在中性anchor里挑最好的,当然前提是你不能跟我完全不相交,那就太过分了。。 for idx in range(num_anchors_for_bbox.shape[0]): if num_anchors_for_bbox[idx]==0: if best_anchor_for_bbox[idx,0]==-1: continue y_is_box_valid[best_anchor_for_bbox[idx,0], best_anchor_for_bbox[idx,1], best_anchor_for_bbox[idx,2]+n_anchratios*best_anchor_for_bbox[idx,3]]=1 y_rpn_overlap[best_anchor_for_bbox[idx,0], best_anchor_for_bbox[idx,1], best_anchor_for_bbox[idx,2]+n_anchratios*best_anchor_for_bbox[idx,3]]=1 start =4 *(best_anchor_for_bbox[idx,2]+n_anchratios*best_anchor_for_bbox[idx,3]) y_rpn_regr[ best_anchor_for_bbox[idx,0],best_anchor_for_bbox[idx,1],start:start+4]=best_dx_for_bbox[idx,:] y_rpn_overlap =np.transpose(y_rpn_overlap,(2,0,1)) y_rpn_overlap =np.expand_dims(y_rpn_overlap,axis=0) y_is_box_valid =np.transpose(y_is_box_valid,(2,0,1)) y_is_box_valid =np.expand_dims(y_is_box_valid,axis=0) y_rpn_regr =np.transpose(y_rpn_regr,(2,0,1)) y_rpn_regr =np.expand_dims(y_rpn_regr,axis=0) #pos代表box,neg代表背景 pos_locs =np.where(np.logical_and(y_rpn_overlap[0,:,:,:]==1,y_is_box_valid[0,:,:,:]==1)) neg_locs =np.where(np.logical_and(y_rpn_overlap[0,:,:,:]==0,y_is_box_valid[0,:,:,:]==1)) num_pos =len(pos_locs[0]) # 因为negtive的anchor肯定远多于postive的, # 因此在这里设定了regions数量的最大值为256,并对pos和neg的样本进行了均匀的取样。 num_regions = 256 #对感兴趣的框超过128的时候 if len(pos_locs[0])>num_regions/2: val_locs =random.sample(range(pos_locs[0]),len(pos_locs[0])-num_regions/2) y_is_box_valid[0,pos_locs[0][val_locs],pos_locs[1][val_locs],pos_locs[2][val_locs]]=0 num_pos =num_regions/2 if len(neg_locs[0])+num_pos >num_regions: val_locs =random.sample(range(neg_locs[0]),len(neg_locs[0])-num_pos) y_is_box_valid[0,neg_locs[0][val_locs],neg_locs[1][val_locs],neg_locs[2][val_locs]]=0 y_rpn_cls =np.concatenate([y_is_box_valid,y_rpn_overlap],axis=1) y_rpn_regr =np.concatenate([np.repeat(y_rpn_overlap,4,axis=1),y_rpn_regr],axis=1) return np.copy(y_rpn_cls),np.copy(y_rpn_regr)
calc_rpn函数的最后一个参数:
def get_new_img_size(width,height,img_min_side=600): if width<=height: f = float(img_min_side)/width resized_height = int(f * height) resized_width = int(img_min_side) else: f = float(img_min_side)/height resized_width = int(f*width) resized_height = int(img_min_side) return resized_width,resized_height
RPN网络损失函数:
lambda_rpn_regr = 1.0 lambda_rpn_class = 1.0 lambda_cls_regr = 1.0 lambda_cls_class = 1.0 epsilon = 1e-4 #这里面y_true就是clac_rpn坐标输出,前36位代表是否是物体,后36位代表的是回归坐标 #对预测框跟真实框进行一个坐标回归 #输入就是clac_rpn的输出 def rpn_loss_regr(num_anchors): def rpn_loss_regr_fixed_num(y_true,y_pred): x = y_true[:,:,:,4*num_anchors:]-y_pred #这里使用smoothL1 x_abs = K.abs(x) x_bool = K.cast(K.less_equal(x_abs,1.0),tf.float32) return lambda_rpn_regr *K.sum( y_true[:,:,:,:4*num_anchors]*(x_bool*(0.5*x*x))+(1-x_bool)*(x_abs-0.5))/K.sum(epsilon+y_true[:,:,:,4*num_anchors]) return rpn_loss_regr_fixed_num #RPN分类损失,二分类是否有物体 def rpn_loss_cls(num_anchors): def rpn_loss_cls_fixed_num(y_true,y_pred): return lambda_rpn_class * K.sum(y_true[:,:num_anchors,:,:]*K.binary_crossentropy(y_pred[:,:,:,:],y_true[:,num_anchors:,:,:]))/K.sum(epsilon,y_true[:,:num_anchors,:,:]) return rpn_loss_cls_fixed_num
RPN-ROI:
输入的是经过RPN网络回归之后的值。
def rpn_roi(rpn_layer,regr_layer,con,dim_ordering,use_regr=True,max_boxes=300,overlap_thresh=0.9): # 因为前面在计算的时候有乘以这个系数,所以这里要除以 regr_layer = regr_layer/con.std_scaling anchor_sizes =con.anchor_box_scales anchor_ratios =con.anchor_box_ratios #如果条件不满足就报错 assert rpn_layer.shape[0] ==1 rows,cols =0,0 #获取宽和高 if dim_ordering =="th": rows,cols =rpn_layer.shape[2:] elif dim_ordering =="tf": rows,cols =rpn_layer.shape[1:3] # 当前通道或者说是锚框序号, 回归总共有9个通道,也可以认为是当前锚框的序号0-8 curr_layer = 0 A=None if dim_ordering =="tf": # 定义所有锚框的中心坐标和宽高的矩阵 A =np.zeros((4,rpn_layer.shape[1],rpn_layer.shape[2],rpn_layer.shape[3])) elif dim_ordering=="th": A =np.zeros((4,rpn_layer.shape[2],rpn_layer.shape[3],rpn_layer.shape[1])) ''' 其实在做的事,就分那么几步: 1.获取锚框的中心坐标,宽高在特征图上的映射。 2.将回归梯度作用于锚框进行修正,称为预测框。 3.进行锚框x1,y1,x2,y2的坐标修正,对应的就是左上角和右下角坐标,不能超出特征图大小。 其实你可以暂时把最后的A理解成有4行,第一行表示所有预测框的x1坐标,第二行表示所有预测框的y1坐标,第三行表示所有预测框的x2坐标,第四行表示所有预测框的y2坐标 ''' for anchor_size in anchor_sizes: for anchor_ratio in anchor_ratios: #获取映射到特征图上的宽和高 anchor_x = (anchor_size*anchor_ratio[0])/con.rpn_stride anchor_y =(anchor_size*anchor_ratio[1])/con.rpn_stride #获取当前通道对应的回归值 if dim_ordering =="th": regr =regr_layer[0,4*curr_layer:4*curr_layer+4,:,:] else: regr =regr_layer[0,:,:,4*curr_layer:4*curr_layer+4] #转成通道,宽,高 regr =np.transpose(regr,(2,0,1)) #将特征图转成网格矩阵 X,Y =np.meshgrid(np.arange(cols),np.arange(rows)) # 填充锚框坐标矩阵,4个值 为了计算锚框修正方便,暂时是中心点以及宽和高,后面修正完会改成4个坐标值 A[0,:,:,curr_layer] =X - anchor_x/2 A[1,:,:,curr_layer] =Y - anchor_y/2 A[2,:,:,curr_layer] =anchor_x A[3,:,:,curr_layer] =anchor_y # 进行锚框的回归修正,即将RPN的回归系数用于锚框上,回归后变成了预测框,希望预测框和真实框的差距越小越好,以便于训练回归系数 # 之后的A我们称为预测框,就是锚框的回归版 if use_regr: A[:,:,:,curr_layer] =apply_rege_np(A[:,:,:,curr_layer],regr) #宽和高不能小于1 A[2,:,:,curr_layer] =np.maximum(1,A[2,:,:,curr_layer]) A[3,:,:,curr_layer] =np.maximum(1,A[3,:,:,curr_layer]) # 宽和高分别加了坐标,就等于右下角的坐标,也即这里把宽高的位置换成了右下角坐标x2,y2 # 现在A里面的值是x1,y1,x2,y2 A[2,:,:,curr_layer]+=A[0,:,:,curr_layer] A[3,:,:,curr_layer]+=A[0,:,:,curr_layer] #x1,y1不能小于0 A[0,:,:,curr_layer] =np.maximum(0,A[0,:,:,curr_layer]) A[1,:,:,curr_layer] = np.maximum(0,A[1,:,:,curr_layer]) #x2,y2不能大于边界-1 A[2,:,:,curr_layer] =np.minimum(cols-1,A[2,:,:,curr_layer]) A[3,:,:,curr_layer] =np.minimum(rows-1,A[3,:,:,curr_layer]) curr_layer+=1 all_boxes =np.reshape(A.transpose((0,3,1,2)),(4,-1)).transpose((1,0)) all_probs =rpn_layer.transpose((0,3,1,2)).reshape(-1) x1 = all_boxes[:,0] y1 = all_boxes[:,1] x2 = all_boxes[:,2] y2 = all_boxes[:,3] #选出不合适的序号 idxs =np.where((x1-x2>=0)|(y1-y2>=0)) #删除不合适的预测框 all_boxes =np.delete(all_boxes,idxs,0) all_probs =np.delete(all_probs,idxs,0) return all_boxes,all_probs
def apply_rege_np(X,T): try: x =X[0,:,:] y =X[1,:,:] w =X[2,:,:] h =X[3,:,:] tx =T[0,:,:] ty =T[1,:,:] tw =T[2,:,:] th =T[3,:,:] cx =x+w/2. cy =y+h/2. cx1 =tx*w +cx cy1 =ty*h+cy w1 =np.exp(tw.astype(np.float64))*w h1 =np.exp(th.astype(np.float64))*h x1 =cx1-w1/2. y1 =cy1-h1/2. x1 =np.round(x1) y1 =np.round(y1) w1 =np.round(w1) h1 =np.round(h1) return np.stack([x1,y1,w1,h1]) except Exception as e: print(e) return X
非极大值抑制:去掉重合比较大的框(保留300个框)
def non_max_suppression_fast(boxes,probs,overlap_thresh=0.9,max_boxes=300): if len(boxes)==0: return [] x1 =boxes[:,0] y1 =boxes[:,1] x2 =boxes[:,2] y2 =boxes[:,3] # 两个数组必须形状一致,并且第一个数组的元素严格小于第二个数组的元素,否则就抛出异常 np.testing.assert_array_less(x1, x2) np.testing.assert_array_less(y1, y2) # 转float 便于计算,可能是因为精度问题吧 if boxes.dtype.kind == "i": boxes = boxes.astype("float") # 保存索引 pick = [] #计算面积 area =(x2-x1)*(y2-y1) # 根据概率从小到大排序,然后输出对应的索引 idxs = np.argsort(probs) # 进行非极大值抑制,直到所有都处理完为止 while len(idxs) >0: # 取最大的概率放进pick里 last =len(idxs)-1 i =idxs[last] pick.append(i) # 所有其他预测框和概率最大的预测框的交并比 xx1_int = np.maximum(x1[i],x1[idxs[:last]]) yy1_int = np.maximum(y1[i],y1[idxs[:last]]) xx2_int = np.minimum(x2[i],x2[idxs[:last]]) yy2_int = np.minimum(y2[i],y2[idxs[:last]]) ww_int = np.maximum(0,xx2_int-xx1_int) hh_int = np.maximum(0,yy2_int-yy1_int) #交集 area_int =ww_int*hh_int #并集 area_union =area[i] + area[idxs[:last]]-area_int overlap =area_int/(area_union+1e-6) # 删除最大概率预测框和IOU大于阈值的所有预测框的索引 idxs =np.delete(idxs,np.concatenate([last],np.where(overlap>overlap_thresh)[0])) if len(pick)>=max_boxes: break boxes = boxes[pick].astype("int") probs = probs[pick] return boxes,probs
选取前景,背景样本进行最终的回归分类训练。
def calc_iou(R,img_data,con,class_mapping): bboxes =img_data["bboxes"] (width,height) = (img_data["width"],img_data["height"]) (resized_width,resized_height) = get_new_img_size(width,height,600) gta = np.zeros((len(bboxes),4)) for bbox_num,bbox in enumerate(bboxes): gta[bbox_num,0] = int(round(bbox["x1"]*(resized_width/float(width))/con.rpn_stride)) gta[bbox_num,1] = int(round(bbox["x2"]*(resized_width/float(width))/con.rpn_stride)) gta[bbox_num,2] = int(round(bbox["y1"]*(resized_height/float(height))/con.rpn_stride)) gta[bbox_num,3] = int(round(bbox["y2"]*(resized_height/float(height))/con.rpn_stride)) #候选框坐标列表 x_roi =[] #类标签 onehot类型 y_class_num =[] # 存放候选框坐标列表,每一个候选框生成一个类似于onehot的坐标列表。列表长度是 (类别数-1)*4 y_class_regr_coords = [] # 所有类标签的onehot列表,类似于处理RPN时候的有效位 ,检测回归梯度的有效位 # 存放候选框坐标有效标签列表,每一个候选框生成一个类似于onehot的有效标签列表,列表长度是 (类别数-1)*4 y_class_regr_label = [] IoUs = [] for ix in range(R.shape[0]): (x1,y1,x2,y2) =R[ix,:] x1 =int(round(x1)) y1 =int(round(y1)) x2 =int(round(x2)) y2 =int(round(y2)) #记录最大的IOU best_iou =0.0 #记录IOU最大那个真实框的索引 best_bbox =-1 tx,ty,tw,th=0,0,0,0 # 每个真实框和候选框做IOU for bbox_num in range(len(bboxes)): curr_iou = iou(gta[bbox_num,0],gta[bbox_num,2],gta[bbox_num,1],gta[bbox_num,3],x1,y1,x2,y2) if curr_iou > best_iou: best_iou =curr_iou best_bbox=bbox_num #小于最小阈值就不处理了,不训练 if best_iou <con.classifier_min_overlap: continue else: w =x2-x1 h =y2-y1 x_roi.append([x1,y1,w,h]) IoUs.append(best_iou) if con.classifier_min_overlap<=best_iou<con.classifier_max_overlap: # 如果在最大最小阈值之间那就是难的负样本,标记为背景 cls_name ="bg" elif con.classifier_max_overlap <=best_iou: # 如果比最大的阈值还大,要训练,那就计算回归梯度,也就是偏移量,第二次回归 cls_name=bboxes[best_bbox]["class"] cxg = (gta[best_bbox,0]+gta[best_bbox,1])/2.0 cyg = (gta[best_bbox,2]+gta[best_bbox,3])/2.0 cx =x1 + w/2.0 cy =y1 + h/2.0 tx =(cxg-cx)/float(w) ty =(cyg-cy)/float(h) tw = np.log((gta[best_bbox,1]-gta[best_bbox,0])/float(w)) th = np.log((gta[best_bbox,3]-gta[best_bbox,2])/float(h)) else: print("roi={}".format(best_iou)) raise RuntimeError # 类别的索引 比如背景 索引应该是len(class_mapping)-1 class_num =class_mapping[cls_name] # 全部为0的列表 转成onehot [0,0,0,0...] class_label =len(class_mapping) *[0] # 类标签设置为1 如果背景,最后一位是1,[0,0,0,...,1] class_label[class_num] =1 # 将onehot编码的分类标签添加进y_class_num y_class_num.append(copy.deepcopy(class_label)) # 初始化onehot的标签和坐标回归系数 把背景除外 背景是全个0,其他表示成 4x(类别数-1) 维的onehot,其中4个维度是1, # 标签是正数,坐标回归系数可以是小数 coords =[0]*4*(len(class_mapping)-1) labels =[0]*4*(len(class_mapping)-1) if cls_name!="bg": # 如果不是背景,就把相应的维度填充1 4个维度,坐标回归系数和标签都要填充 label_pos =4*class_num # 回归缩放系数 sx,sy,sw,sh =con.classifier_regr_std # 相应的坐标位置上填回归梯度 coords[label_pos:label_pos+4] =[sx*tx,sy*ty,sw*tw,sh*th] # 相应的坐标位置上填1 有点像有效位 labels[label_pos:label_pos+4]=[1,1,1,1] y_class_regr_coords.append(copy.deepcopy(coords)) y_class_regr_label.append(copy.deepcopy(labels)) else: y_class_regr_coords.append(copy.deepcopy(coords)) y_class_regr_label.append(copy.deepcopy(labels)) #没有一个候选框是合适的 if len(x_roi)==0: return None,None,None,None X = np.array(x_roi) Y1 =np.array(y_class_num) Y2 =np.concatenate([np.array(y_class_regr_label),np.array(y_class_regr_coords)],axis=1) return np.expand_dims(X,axis=0),np.expand_dims(Y1,axis=0),np.expand_dims(Y2,axis=0),IoUs
最终训练的loss
lambda_rpn_regr = 1.0 lambda_rpn_class = 1.0 lambda_cls_regr = 1.0 lambda_cls_class = 1.0 epsilon = 1e-4 #输入位clac_iou的输出 def class_loss_regr(num_classes): def class_loss_regr_fixed_num(y_true,y_pred): x =y_true[:,:,4*num_classes:]-y_pred x_abs =K.abs(x) x_bool =K.cast(K.less_equal(x_abs,1.0),"float32") return lambda_cls_regr*K.sum(y_true[:,:,:4*num_classes]*(x_bool*(0.5*x*x)+(1-x_bool)*(x_abs-0.5)))/K.sum(epsilon+y_true[:,:,:4*num_classes]) return class_loss_regr_fixed_num def class_loss_cls(y_true,y_pred): return lambda_rpn_class * K.mean(categorical_crossentropy(y_true[0,:,:],y_pred[0,:,:]))