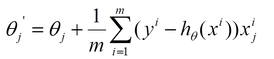最小值:梯度下降;最大值:梯度上升
(1)批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小。
(2)随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。

让theta(j)沿梯度下降最快的方向变化,批量梯度下降对多个样本梯度去均值;
梯度下降:
http://blog.csdn.net/acdreamers/article/details/27660519
相关表达式:

批量梯度下降:
http://blog.csdn.net/lilyth_lilyth/article/details/8973972
相关表达式: