- 过拟合,欠拟合
对于overfitting常用regularization正则化
参见machine learning
Regularization is designed to address the problem of overfitting.
There are two main options to address the issue of overfitting:
1) Reduce the number of features:
a) Manually select which features to keep.
b) Use a model selection algorithm (studied later in the course).
2) Regularization
Keep all the features, but reduce the parameters J .
Regularization works well when we have a lot of slightly useful features.
- 2. 一个数据集,并且既要训练,又要测试的评估方法
留出法:当只有一个数据集的时候,用一部分来训练,一部分来测试。而且训练数据和测试数据没有交集。通常会用60%到80%的数据作为训练集,剩下的作为测试集。需要注意的是,在选择训练集(或者测试集)的时候要采用分层抽样的方法。就像刷题一样,训练集和测试集都要有相近比例的题型,不能训练集全是选择题,测试集全是论述题,应该训练集和测试集都包含选择题和测试题,而且比例要一致,都是八成选择题,两成论述题。
一次的训练-测试结果可能不够科学,最好划分不同的训练集和测试集,做多次训练-测试,将测试结果(错误率、查准率之类的)取平均。
交叉检验法:这是在“留出法”的基础上改进的方法。先将数据集分为k个大小相似的互斥子集(当然,每个子集的产生都要用分层抽样进行)。每次用k-1个子集作为训练集,剩下的一个作为测试集。这样就可以进行k次训练-测试。k的测试结果的平均值就是最终的测试结果。
自助法:上述两种方法都是在原本作为训练集的数据中抽出一部分作为测试集,因此训练集的规模不可避免地减少了,训练效果也就受到了影响。自助法则是一中比较好的缓解方法。假设有一个包含m个样本的数据集D。对这个数据集进行m次有放回的抽样,则得到了一个含有m个样本的数据集D'。D'相对于原数据集D,规模没有减少,只是D'中有部分样本是重复出现的。所以在抽样中没有抽到的样本就作为测试集,D'就作为训练集。按照概率论推导可知,一般来说抽样中国会有三分之一的样本没有被抽到,也就是说测试集大小为数据集D大小的三分之一。
- 3. 性能度量
在预测任务中,给定样例集D = {(X1, Y1) , (X2 , 的), . . . , (Xm, Ym)} , 其中Yi
是示例Xi 的真实标记.要评估学习器f 的性能,就要把学习器预测结果f(x)
与真实标记y进行比较.
回归任务最常用的性能度量是"均方误差" (mean squared error)
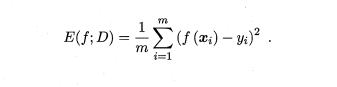
- 4. 分类任务中常用的性能度量.
Ø 错误率与精度
错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例
错误率定义为
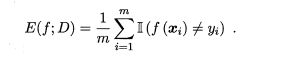
精度则定义为

Ø 查准率、查全率与Fl

查准率和查全率是一对矛盾的度量.一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低.
ØAndrew Ng 机器学习第六课
Ø Andrew Ng 机器学习第六课
Ø 
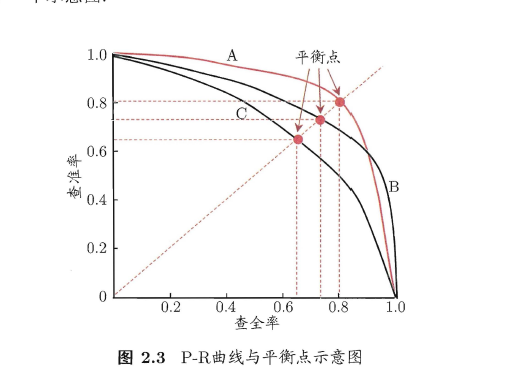
Ø P-R 图直观地显示出学习器在样本总体上的查全率、查准率.
- 5. F1度量
由于BEP 还是过于简化了些,更常用的是F1 度量:

F1 度量的一般形式--Fß' 能让我们表达出对查准率/查全率的不同偏好,它定义为
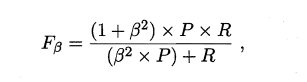
其中ß>O 度量了查全率对查准率的相对重要性. ß = 1时退化为标准的F1; ß> 1 时查全率有更大影响; ß < 1 时查准率有更大影响.
- 6. ROC
ROC 全称是"受试者工作特征" (Receiver Operating Characteristic) 曲
线7
- 7. ROC 曲线
ROC的纵轴是"真正例率" (True Positive Rate,简称TPR) ,横轴是"假正例率" (False PositiveRate,简称FPR)
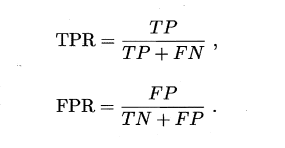
- 8. ROC AUC

现实任务中通常是利用有限个测试样例来绘制ROC 图,此时仅能获得有
限个(真正例率,假正例率)坐标对,无法产生图2.4(a) 中的光滑ROC 曲线,
AUC 可通过对ROC 曲线下各部分的面积求和而得
1.