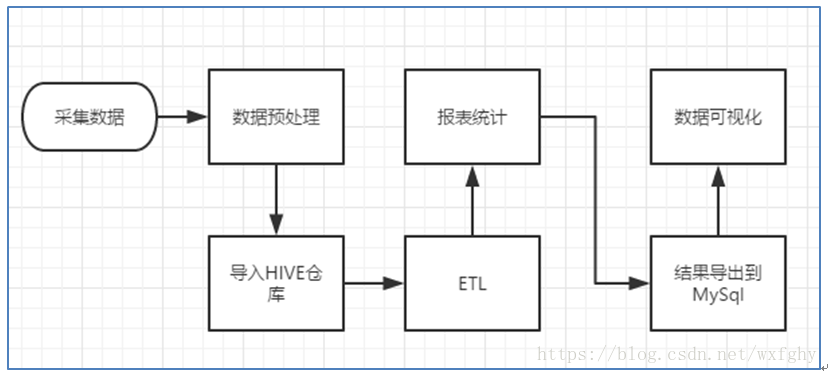
一、大数据的基本处理步骤
1)数据获取
flume
数据来源:专业数据机构,国家统计局,企业内部数据,互联网数据
2)数据清洗
mapreduce
清除不需要,错误,无效的数据
3)数据存储
hdfs
性能,可用,可靠,成本等方面考量
4)数据处理
hive
按业务需求处理
5)数据分享
sqoop,kettle
可视化展示,最大化利用数据价值
二、数据仓库技术 ETL
E: extract 抽取
T: tansform 交互转换
L: load 加载
三、 商业智能 BI(Business Intelligence)
1)商业智能
2)将企业现有数据有效整合,快速准确提供报表提出决策依据,帮助作出业务决策
3)需求分析和功能实现依赖的技术组件
四、Hadoop
1)apache旗下开源软件平台,广义是指Hadoop生态圈
2)利用分布式集群,根据具体业务,对海量数据进行分布式处理
3)核心组件包括COMMON,HDFS,YARN,MAPREDUCE
组件名称以及主要功能
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于文件系统和运算框架的SQL数据仓库工具
ZOOKEEPER:分布式协调服务基础组件
HBASE:分布式数据库OLTP
Mahout:基于分布式运算框架的机器学习算法库
Saoop:数据的导入导出工具
Flume:日志数据采集框架