1.什么是Json?
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它是JavaScript的子集,易于人阅读和编写。
JSON注意事项:
(1)名称必须用双引号(即:””)来包括
(2)值可以是双引号包括的字符串、数字、true、false、null、JavaScript数组,或子对象。
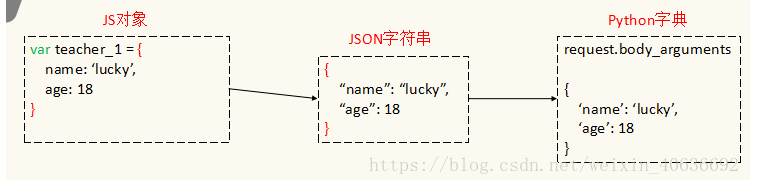
2.python数据类型与json数据类型的映射关系

3. json中常用的方法
在使用json这个模块前,首先要导入json库:import json

3-1 json.dumps()
import json
data = {'name':'nanbei','age':18}
#将Python对象编码成json字符串
print(json.dumps(data))
结果:
{"name": "nanbei", "age": 18}
注: 在这里我们可以看到,原先的单引号已经变成双引号了
3-2 json.loads()
import json
data = {'name':'nanbei','age':18}
#将Python对象编码成json字符串
#print(json.dumps(data))
#将json字符串编码成Python对象
a = json.dumps(data)
print(json.loads(a))
结果:
{'name': 'nanbei', 'age': 18}
在这里举个元组和列表的例子:
import json data = (1,2,3,4) data_json = [1,2,3,4] #将Python对象编码成json字符串 print(json.dumps(data)) print(json.dumps(data_json)) #将json字符串编码成Python对象 a = json.dumps(data) b = json.dumps(data_json) print(json.loads(a)) print(json.loads(b))
结果:
[1, 2, 3, 4]
[1, 2, 3, 4]
[1, 2, 3, 4]
[1, 2, 3, 4]
可以看到,元组和列表解析出来的均是数组。
3-3 json.dump()
import json
data = {
'nanbei':'haha',
'a':[1,2,3,4],
'b':(1,2,3)
}
with open('json_test.txt','w+') as f:
json.dump(data,f)
查看结果:

3-4 json.load()
import json
data = {
'nanbei':'haha',
'a':[1,2,3,4],
'b':(1,2,3)
}
with open('json_test.txt','w+') as f:
json.dump(data,f)
with open('json_test.txt','r+') as f:
print(json.load(f))
结果:
{'a': [1, 2, 3, 4], 'b': [1, 2, 3], 'nanbei': 'haha'}
4.参数详解:
dump(obj,skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):
# 函数作用: 将Python的对象转变成JSON对象
# skipkeys: 如果为True的话,则只能是字典对象,否则会TypeError错误, 默认False
# ensure_ascii: 确定是否为ASCII编码
# check_circular: 循环类型检查,如果为True的话
# allow_nan: 确定是否为允许的值
# indent: 会以美观的方式来打印,呈现,实现缩进
# separators: 对象分隔符,默认为,
# encoding: 编码方式,默认为utf-8
# sort_keys: 如果是字典对象,选择True的话,会按照键的ASCII码来排序
对于dump来说,只是多了一个fp参数
dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw)
Serialize ``obj`` as a JSON formatted stream to ``fp`` (a
``.write()``-supporting file-like object).
简单说就是dump需要一个类似文件指针的参数(并不是真正的指针,可以称之为文件对象),与文件操作相结合,即先将Python文件对象转化为json字符串再保存在文件中。。。
转载----原文链接:https://blog.csdn.net/weixin_40636692/article/details/81212304