排序算法
地址:https://www.cnblogs.com/onepixel/articles/7674659.html
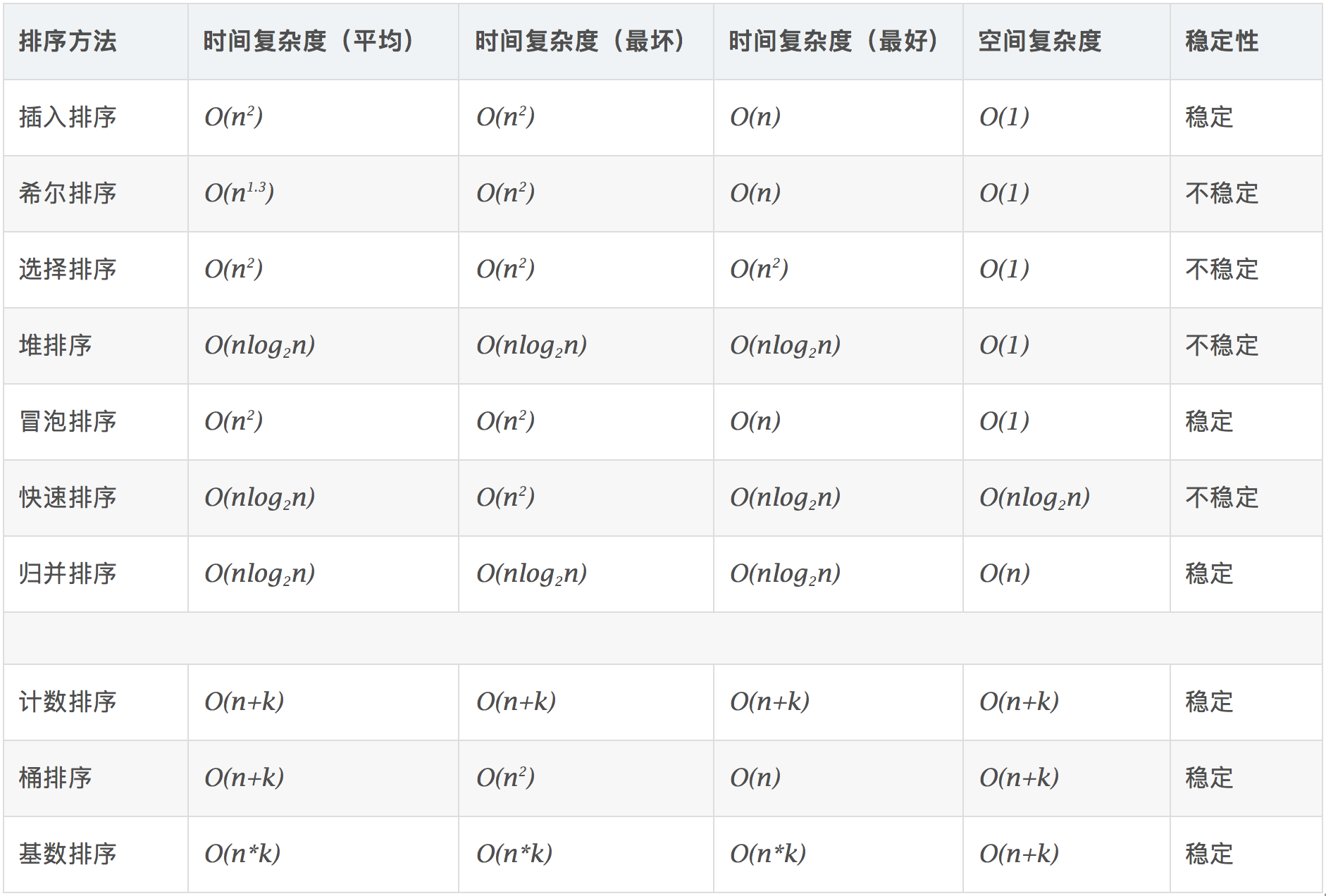
各种排序算法复杂度
冒泡排序 (稳定)
比较相邻的元素,如果第一个比第二个大,就交换它们两个。 重复执行。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
选择排序(不稳定)
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,
插入排序
通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
从第一个元素开始,该元素可以认为已经被排序;
取出下一个元素,在已经排序的元素序列中从后向前扫描;
如果该元素(已排序)大于新元素,将该元素移到下一位置;
重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
将新元素插入到该位置后;
重复步骤2~5。
归并排序
https://blog.csdn.net/k_koris/article/details/80508543
首先将这个数组分成一半,再分别将左边的数组和右边的数组分成一半,
分到一定细度的时候,每一个部分就只有一个元素了,那么我们此时不用排序,对他们进行归并。
归并到上一个层级之后继续归并,归并到更高的层级。可以用递归的过程来实现整个归并。
如何归并:需要一个临时数组,对比左右两个数组的元素,小得插入,然后索引往后移动。如果那个数组先对比完了,另外一个就不需要对比了。
归并思路就是这样了,最后唯一需要注意的是那个先比较完的话,那么剩下的直接不需要比较,把后面的直接移上去就可以了,这个需要提前判定一下。
快速排序
这个讲的最清楚了 https://www.cnblogs.com/redbear/p/8891730.html
时间复杂度比较复杂,最好的情况是O(n),最差的情况是O(n2),所以平时说的O(nlogn),为其平均时间复杂度。
思想:
随机找出一个数,可以随机取,也可以取固定位置,一般是取第一个或最后一个称为基准,然后就是比基准小的在左边,比基准大的放到右边,如何放做,就是和基准进行交换,这样交换完左边都是比基准小的,右边都是比较基准大的,这样就将一个数组分成了两个子数组,然后再按照同样的方法把子数组再分成更小的子数组,直到不能分解为止。