记录平常用到的SQL语句写法及用法
SQL server
基础用法部分:
1.添加字段
ALTER table [TableName] add [字段名称] 字段类型 ; ALTER table [sale_plan] add addr_no nvarchar(50) null ;
2. 删除字段
--删除 "Person" 表中的 "Birthday" 列 ALTER TABLE Person DROP COLUMN Birthday ;
3. 更改字段类型
ALTER TABLE Persons ALTER COLUMN Name nvarchar(50)
4. 创建表
CREATE TABLE Persons ( Id_P int IDENTITY(1,1) NOT NULL, --主键自增 LastName varchar(255) NOT NULL, --不为空 FirstName varchar(255), Address varchar(255), City varchar(255) )
5. 插入数据
--语法 --INSERT INTO 表名称 VALUES (值1, 值2,....) --INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....) INSERT INTO Persons VALUES ('Gates', 'Bill', 'Xuanwumen 10', 'Beijing')
--Sql Sever 根据查询插入数据 (这种插入方式不需要写Values)
INSERT INTO TableA(列1, 列2, ...) SELECT A, B, ... FROM TableB WHERE TableB.id = '1' ;
6. 更新字段的值带有单引号时 ' 的处理方式
update tableA columns1 = 'M''s ABC' where id = 1 ; -- columns1的值在数据库中显示为: M's ABC
7. 查询出一个表的数据插入到另外一张表
select * into destTbl from srcTbl ; insert into destTbl(fld1, fld2) select fld1, 5 from srcTbl ; --以上两句都是将 srcTbl 的数据插入到 destTbl,但两句又有区别的: --第一句(select into from)要求目标表(destTbl)不存在,因为在插入时会自动创建。 --第二句(insert into select from)要求目标表(destTbl)存在,由于目标表已经存在,所以我们除了插入源表(srcTbl)的字段外,还可以插入常量,如例中的:5。
8. 不确定字段查询和更新
1 select * from where 1=1 ; 2 3 update Table set columu1=column1 ... where ... ;
9.SQL Server 分页;
//若搜索则从新生成rownum (当前生成的rownum不能作为where后面的条件)
SELECT T.* FORM( select ROW_NUMBER() OVER(ORDER BY A.createDate asc ) AS sortNum,A.* from TableA where 1=1) T where T.sortNum> 10 and T.sortNum <=11;
10. SQL Server 插入长文本;
注意:SQL本身是没有限制长度的,插入数据后,使用select 查询出来,直接复制vnarchar(max)字段,是复制不全的,需要导出到*.csv文件中才能查看到完整的值;
ALTER TABLE WriteBackDataLog ALTER COLUMN Payload varchar(MAX);
如下图,copy不出完整payload字段的值,save results as 可将完整的数据导出来!
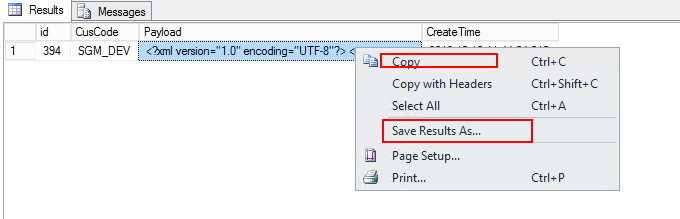
11. 添加主键:
alter table Scrap_Info add id numeric(18,0) identity(1,1)
12. SQL Server Management Studio 修改表字段顺序
在 Microsoft SQL Server Management Studio 中:
a). 工具->选项->Designers->表设计器和数据库设计器->将“阻止保存要求重新创建表的更改”的选项的勾去掉。
b). 右键单击你要更改的数据表,点选“设计”,然后在表设计器中用鼠标拖动各列的位置,最后保存即可。
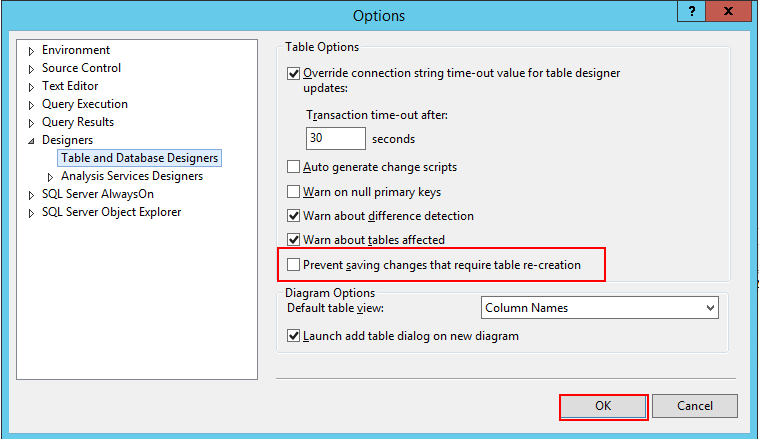
常用部分:
1.查询当前时间: select GETDATE() ;
* 字符串格式转日期格式:
SELECT CONVERT(datetime,'11/1/2003',101) --Style=101时,表示日期字符串为:dd/mm/yyyy格式
----结果:2003-01-11 00:00:00.000
2.查询非表字段写法:
select columns1, columns2, '' as otherColumns , 123 as tempColumns from Table ;
3. distinct 用法,distinct 必须用在select 后面的第一个位置, distinct后面出现的字段也会去重(columnsA的值相同,columnsB不同会作为结果分别查出来 );
select distinct columnsA , columnsB from Table ;
4.字段为空 ISNULL()函数的使用
--查询出姓名为空的记录 select * from Person where ISNULL(name,'') ='' ;
--字段值为 NULL 的,在查询条件里是不参与<>号运算的,即 where clumnA <> 'F' ,查不出 clumnA为 NULL的记录;
可使用ISNULL 函数进行处理,即 where ISNULL(clumnA,'') <> 'F' ;
在Oracle中,使用NVL(Expr1,Expr2) 如果Expr1为NULL,返回Expr2的值,否则返回Expr1的值;
例如:
1 SELECT user_id,NVL(COMPUTER_TYPE,'') as COMPUTER_TYPE FROM TABLE; 2 --这里执行SQL后,还是显示(null) 不清楚是SQL工具自动显示的还是怎么回事 3 4 --改成 NVL(COMPUTER_TYPE,'T') 是可以看到函数是生效了的; 5 SELECT user_id,NVL(COMPUTER_TYPE,'T') as COMPUTER_TYPE FROM TABLE;
5. case when 的两种写法:
--简单Case函数 CASE sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '其他' END --Case搜索函数 CASE WHEN sex = '1' THEN '男' WHEN sex = '2' THEN '女' ELSE '其他' END
6.having 在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
--查找订单总金额少于 2000 的客户 SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer HAVING SUM(OrderPrice)<2000
7.left join
左链接,做表全部显示,不管右表有没有匹配项; 左表的一条记录,比如右表有2条满足on的匹配条件,就会出现2条记录。
select tableA.*,tableB.addr tableA left join tableB on tableA.addrID=tableB.addrID where tableA.id=1;
(tableA为学生表,tableB为地址表,tableA中的addrID在tableB里有两个相同的addrID,则查询结果就会出现一个学生对应两个地址,出现两条查询结果)
8. inner join
如果表结果如下: inner join 第二表中on的条件中有两条匹配项,查询结果就会出现两条记录;注意不能join后使用group by 来统计数量,这个统计出来的数据是错误的。


如下:如果先join 再统计,显然统计错误;应该先统计出来后,再匹配过滤 select name,sum(quality) from Lw_T1 group by name ;
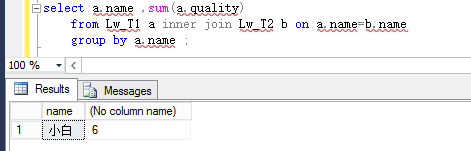
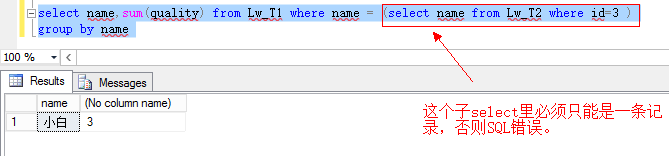
9. SQL拼接字段的值

10. group分组以后取最大的记录;
要实现这个功能需要两个SQL语句,但是可以写到一起;
第一个group语句,先把关键字段和排序字段查出来,然后再用 inner 连接查出其他字段的值;
例如:
1 --1 先用最少字段,分组查询关键字段; 2 SELECT user_id,MAX(create_time) From table WHERE ISNULL(action_type,'')='add' GROUP BY user_id ; 3 4 --2 在链接查询出其他需要用到的字段; 5 SELECT A.* FROM table 6 INNER JOIN 7 ( 8 SELECT user_id,MAX(create_time) From table WHERE ISNULL(action_type,'')='add' GROUP BY user_id 9 ) B 10 ON A.user_id = B.user_id ;
或者还有一种方法是在 WHERE 条件里再进行一次子查询,此方法比较适合排序比较方便的数据库,比如mysql 或 sqlserver;思路都是一样的,先查最大/小的一条,在关联查询出来其他字段:
例如:
1 --查询所有客户最新的跟进记录: 2 select r.c_id, r.c_createtime , r.c_custid , r.c_remark 3 from t_followuprecord r where r.c_isvalid=true and r.c_id =
(select c_id from t_followuprecord where c_custid = r.c_custid order by c_createtime desc limit 0,1) 4 5 6 select a.* from ReceivedData a where a.id=(select top 1 id from ReceivedData where a.importCode=importCode order by createDate desc) 7 8 --子查询里就相当于思路的第一步,外层查询就是第二步
11. SQL Server 简易备份; 通过SQL简易备份,也可通过SqlServer MannagementStuido 客户端来操作备份,详细操作可执行百度;
1 SELECT * FROM TABLE; --先查一下原始表 2 3 SELECT * INTO TABLE_BAK20200303 FORM TABLE; --自动创建表结构并把数据复制到备份表TABLE_BAK20200303 中,执行完毕后可对比两个表的数据是一致的;
12. 根据表B更新表A的字段;
1 update table1 2 set field1=table2.field1, 3 field2=table2.field2 4 from table2 5 where table1.id=table2.id 6 and table1.id in ('001','002') --如果有其他限制条件就再加上where条件
13. Oracle 时间字段
--更新字段为当前日期(字段类型为char) UPDATE TABLE SET READ_DATE = to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') --更新timestamp字段 update TABLE set COLUMN1 = to_timestamp(to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')
时间比较:
COLUMN01 > TO_TIMESTAMP('2020-11-20','yyyy-mm-dd hh24:mi:ss.ff3') --ff3表示毫秒位数为3,ff6表示6位毫秒 (COLUMN01类型为timestamp)