原文地址:https://segmentfault.com/a/1190000008484167
博主讲的很好
一:背景
给定一个字符串,求出其最长回文子串。例如:
- s="abcd",最长回文长度为 1;
- s="ababa",最长回文长度为 5;
- s="abccb",最长回文长度为 4,即bccb。
以上问题的传统思路大概是,遍历每一个字符,以该字符为中心向两边查找。其时间复杂度为$O(n^2)$,效率很差。
1975年,一个叫Manacher的人发明了一个算法,Manacher算法(中文名:马拉车算法),该算法可以把时间复杂度提升到$O(n)$。下面来看看马拉车算法是如何工作的。
二:算法过程分析
由于回文分为偶回文(比如 bccb)和奇回文(比如 bcacb),而在处理奇偶问题上会比较繁琐,所以这里我们使用一个技巧,具体做法是:在字符串首尾,及各字符间各插入一个字符(前提这个字符未出现在串里)。
举个例子:s="abbahopxpo",转换为s_new="$#a#b#b#a#h#o#p#x#p#o#"(这里的字符 $ 只是为了防止越界,下面代码会有说明),如此,s 里起初有一个偶回文abba和一个奇回文opxpo,被转换为#a#b#b#a#和#o#p#x#p#o#,长度都转换成了奇数。
定义一个辅助数组int p[],其中p[i]表示以 i 为中心的最长回文的半径,例如:
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| s_new[i] | $ | # | a | # | b | # | b | # | a | # | h | # | o | # | p | # | x | # | p | # |
| p[i] | 1 | 2 | 1 | 2 | 5 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 4 | 1 | 2 | 1 |
可以看出,p[i] - 1正好是原字符串中最长回文串的长度。
接下来的重点就是求解 p 数组,如下图: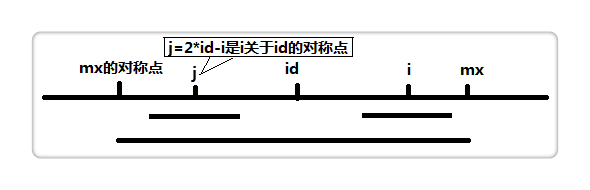
设置两个变量,mx 和 id 。mx 代表以 id 为中心的最长回文的右边界,也就是mx = id + p[id]。
假设我们现在求p[i],也就是以 i 为中心的最长回文半径,如果i < mx,如上图,那么:
if (i < mx) p[i] = min(p[2 * id - i], mx - i);
2 * id - i为 i 关于 id 的对称点,即上图的 j 点,而p[j]表示以 j 为中心的最长回文半径,因此我们可以利用p[j]来加快查找。
#include <iostream> #include <cstring> #include <algorithm> using namespace std;
const int maxn = 10010; char s[maxn]; char s_new[maxn<<1]; int p[maxn<<1]; int Init() { int len = strlen(s); s_new[0] = '$'; s_new[1] = '#'; int j = 2; for (int i = 0; i < len; i++) { s_new[j++] = s[i]; s_new[j++] = '#'; } s_new[j] = '�'; // 别忘了哦 return j; // 返回 s_new 的长度 } int Manacher() { int len = Init(); // 取得新字符串长度并完成向 s_new 的转换 int max_len = -1; // 最长回文长度 int id; int mx = 0; for (int i = 1; i < len; i++) { if (i < mx) p[i] = min(p[2 * id - i], mx - i); // 需搞清楚上面那张图含义, mx 和 2*id-i 的含义 else p[i] = 1; while (s_new[i - p[i]] == s_new[i + p[i]]) // 不需边界判断,因为左有'$',右有'�' p[i]++; // 我们每走一步 i,都要和 mx 比较,我们希望 mx 尽可能的远,这样才能更有机会执行 if (i < mx)这句代码,从而提高效率 if (mx < i + p[i]) { id = i; mx = i + p[i]; } max_len = max(max_len, p[i] - 1); } return max_len; } int main() { while (printf("请输入字符串: ")) { scanf("%s", s); printf("最长回文长度为 %d ", Manacher()); } return 0; }
四:算法复杂度分析
文章开头已经提及,Manacher算法为线性算法,即使最差情况下其时间复杂度亦为$O(n)$,在进行证明之前,我们还需要更加深入地理解上述算法过程。
根据回文的性质,p[i]的值基于以下三种情况得出:
(1):j 的回文串有一部分在 id 的之外,如下图:
上图中,黑线为 id 的回文,i 与 j 关于 id 对称,红线为 j 的回文。那么根据代码此时p[i] = mx - i,即紫线。那么p[i]还可以更大么?答案是不可能!见下图: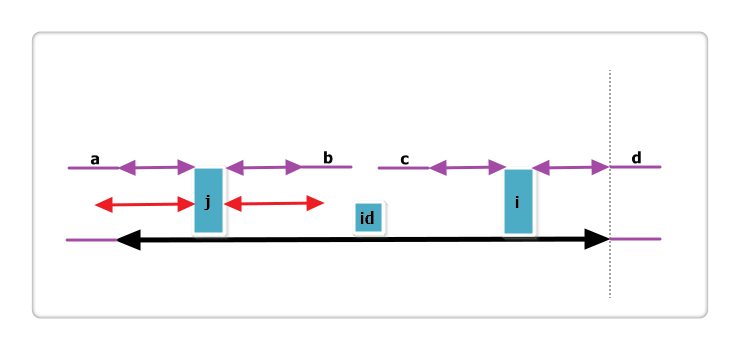
假设右侧新增的紫色部分是p[i]可以增加的部分,那么根据回文的性质,a 等于 d ,也就是说 id 的回文不仅仅是黑线,而是黑线+两条紫线,矛盾,所以假设不成立,故p[i] = mx - i,不可以再增加一分。
(2):j 回文串全部在 id 的内部,如下图: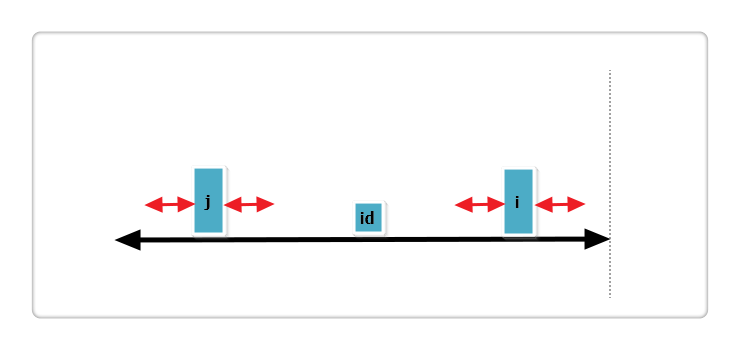
根据代码,此时p[i] = p[j],那么p[i]还可以更大么?答案亦是不可能!见下图: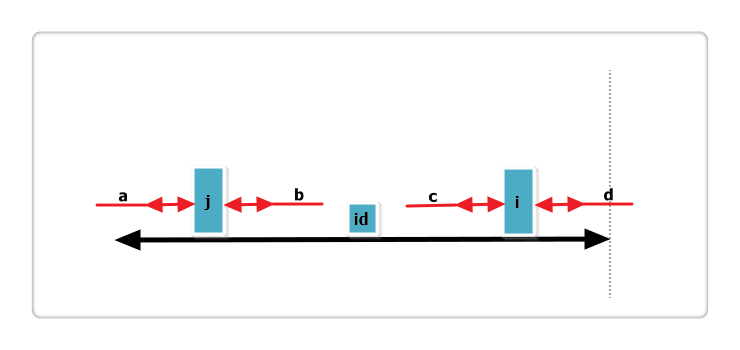
假设右侧新增的红色部分是p[i]可以增加的部分,那么根据回文的性质,a 等于 b ,也就是说 j 的回文应该再加上 a 和 b ,矛盾,所以假设不成立,故p[i] = p[j],也不可以再增加一分。
(3):j 回文串左端正好与 id 的回文串左端重合,见下图:
根据代码,此时p[i] = p[j]或p[i] = mx - i,并且p[i]还可以继续增加,所以需要
while (s_new[i - p[i]] == s_new[i + p[i]])
p[i]++;根据(1)(2)(3),很容易推出Manacher算法的最坏情况,即为字符串内全是相同字符的时候。在这里我们重点研究Manacher()中的for语句,推算发现for语句内平均访问每个字符5次,即时间复杂度为:$T_{worst}(n)=O(n)$。
同理,我们也很容易知道最佳情况下的时间复杂度,即字符串内字符各不相同的时候。推算得平均访问每个字符4次,即时间复杂度为:$T_{best}(n)=O(n)$。
综上,Manacher算法的时间复杂度为$O(n)$。
参考文献:
[1] Stephen__. hdu3068之manacher算法+详解
文章转自我的个人博客:https://subetter.com/articles/2018/03/manacher-algorithm.html