文章很长,建议收藏起来慢慢读!疯狂创客圈总目录 语雀版 | 总目录 码云版| 总目录 博客园版 为您奉上珍贵的学习资源 :
-
免费赠送 :《尼恩Java面试宝典》持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
-
免费赠送 经典图书:《Java高并发核心编程(卷1)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Java高并发核心编程(卷2)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《SpringCloud Nginx高并发核心编程》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
| 入大厂 、做架构、大力提升Java 内功 必备的精彩博文 | 秋招涨薪1W + 必备的精彩博文 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 3: Redis与MySQL双写一致性如何保证? (面试必备) | 4: 面试必备:秒杀超卖 解决方案 (史上最全) |
| 5:面试必备之:Reactor模式 | 6: 10分钟看懂, Java NIO 底层原理 |
| 7:TCP/IP(图解+秒懂+史上最全) | 8:Feign原理 (图解) |
| 9:DNS图解(秒懂 + 史上最全 + 高薪必备) | 10:CDN图解(秒懂 + 史上最全 + 高薪必备) |
| 11: 分布式事务( 图解 + 史上最全 + 吐血推荐 ) | 12:限流:计数器、漏桶、令牌桶 三大算法的原理与实战(图解+史上最全) |
| 13:架构必看:12306抢票系统亿级流量架构 (图解+秒懂+史上最全) |
14:seata AT模式实战(图解+秒懂+史上最全) |
| 15:seata 源码解读(图解+秒懂+史上最全) | 16:seata TCC模式实战(图解+秒懂+史上最全) |
| SpringCloud 微服务 精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| SpringCloud gateway (史上最全) | 分库分表sharding-jdbc底层原理与实操(史上最全,5W字长文,吐血推荐) |
推荐:尼恩Java面试宝典(持续更新 + 史上最全 + 面试必备)具体详情,请点击此链接
尼恩Java面试宝典,32个最新pdf,含2000多页,不断更新、持续迭代 具体详情,请点击此链接

Jmeter分布式压力测试(史上最全)
压测问题
社群小伙压测问题一
jmeter 测试网关,单体吞吐量7000,分布式才600
问题还在解决中,后面会再次贴出解决方案
此文的作用
下面讲分布式测试过程中分析问题,用到的命令,工具,统一记录下来
供大家参考
Jmeter分布式测试
使用Jmeter分布式测试的背景:
1、GUI、非GUI的区别
首先,我们知道Jmeter有两种运行方式,GUI、非GUI。
GUI:在Windows系统上运行,图形化界面,方便查看测试结果,但是消耗压力机资源较高,容易卡死,有并发限制。
非GUI:通过命令行运行,无图形化界面,不方便查看测试结果,但是消耗压力机资源较低,可以支持较大并发。
2、GUI、非GUI遇到的问题
Jmeter是基于java程序运行的,在windows上使用Jmeter进行性能测试时,非常耗费客户机的CPU和内存,如果并发数稍微大一点(比如100、1000...并发),单台电脑的配置经常无法支持,很容易卡死,即使不卡死也会使电脑运行很慢,导致我们没办法进行其它操作。
通过cmd命令行,或者是在Linux上使用Jmeter进行性能测试时,能够大大缩减所需要的系统资源;但是需要将jmeter脚本上传到Linux上使用命令行方式运行,如果脚本经常改动就要频繁上传;测试完成后要把结果数据下载到本地GUI环境中查看,当结果文件较大时,下载要花费大量时间,总是有很多不方便。
3、如何解决?
以上问题,都可以使用Jmeter的分布式测试功能来解决:
通过Jmeter远程启动功能,把一台windows机器做为控制器,远程控制其它多个windows或linux压力机,从而把压力分散到多台机器上,实现高并发功能;并在master上收集测试结果。
jmeter分布式原理
二、jmeter分布式原理
jmeter的分布式控制,说的通俗一点,就是指远程启动功能,具体原理如下图:
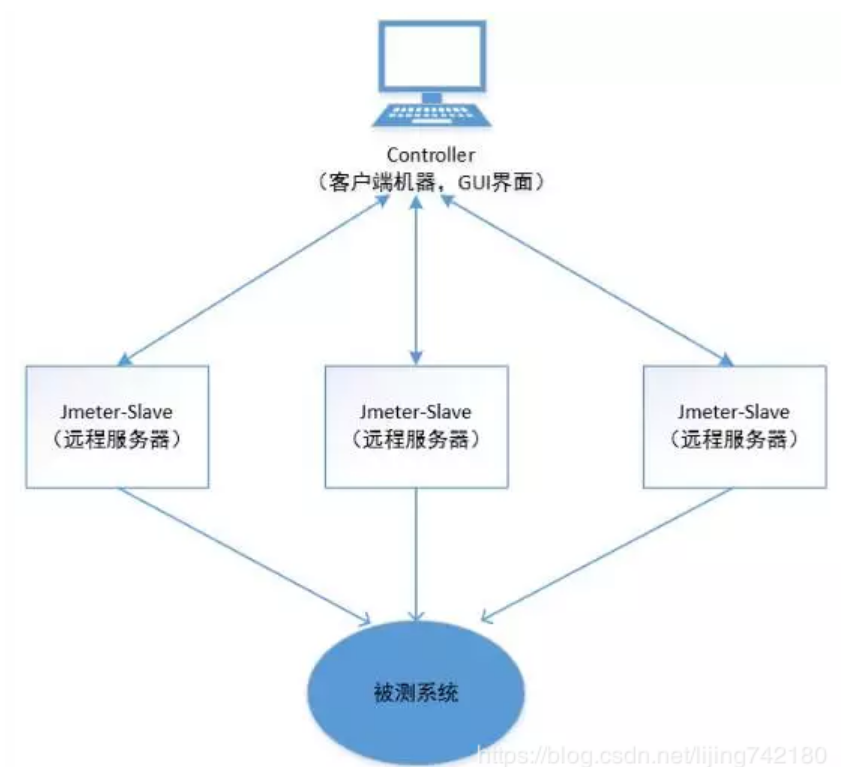

1、客户端机器(window系统)作为一个控制器controller,控制多台slave机器的操作。
2、Controller和slave机器上最好装有相同版本的jdk和jmeter,并配置好环境变量,安装和配置方法跟windows环境类似。
3、controller通过GUI界面启动slave机器,将jmeter压测脚本发送给每台启动的slave,slave获得脚本后开始执行。slave本地不需预先存储脚本,但是需要有脚本中的依赖文件(如csv文件等)。
4、各台slave执行完成后,将结果传回给controller,controller收集后整合显示出来。
jmeter分布式配置
三、jmeter分布式(远程启动)配置
1、slave远程机配置
slave远程机需安装jdk和jmeter,最好与controller上的版本保持一致,无法满足时至少保证slave上的jmeter能正常运行(如jmeter3.0以后需要jdk1.7及以上版本)。
启动salve机的jmeter-server
在slave的%JMETER_HOME%bin目录下执行./jmeter-server命令启动jmeter服务,启动成功如下图:

修改slave机jmeter默认端口
上图红框中的ip为slave机的ip地址,红框中的端口号port为启动 jmeter服务监听的port,一般会有个默认端口号1099,但最好自定义,确保端口号不冲突。修改方法如下:
在slave机器的%JMETER_HOME%bin目录下找到jmeter.properties,修改文件中server_port和server.rmi.localport,即可自定义端口号:
server_port=1029
server.rmi.localport=1029
注意这两项必须同时修改,且一样。
修改后执行slave的jmeter-server即可看到控制台消息中修改是否生效;
2、控制机controller配置
在控制机上要保证执行命令能发送到远程slave机,需要在控制机上配置远程机的ip地址和port。
在控制机jmeter安装目录的bin文件夹下,找到jmeter.properties,修改配置如下图,其中ip和port即为上一步slave的ip和port,如上图中jmeter-server启动时红框中显示的内容。多个slave机器的配置可通过逗号分隔。
remote_hosts=10.165.124.6:1029
若要添加多个slave机,重复上面的步骤即可。
3、远程启动和停止
配置完成后打开控制机jmeter的GUI界面,在运行-远程启动中即可看到自己配置的slave机器。
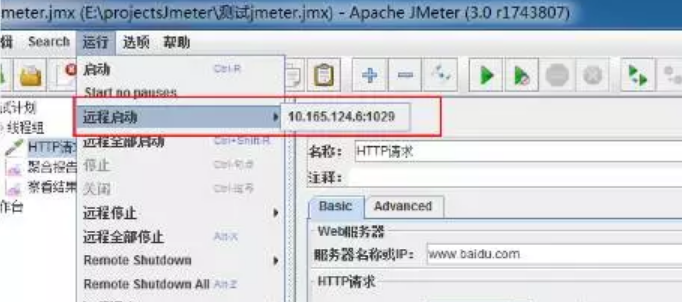
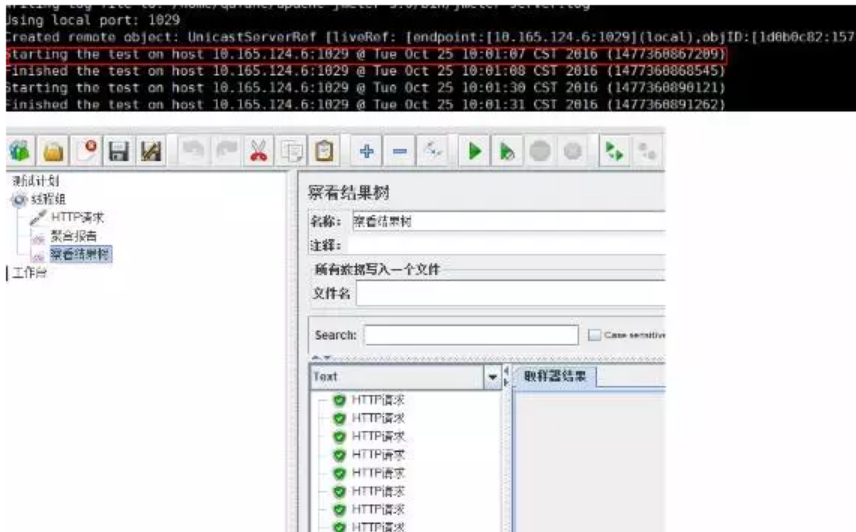
 添加一个脚本,点击远程启动即可启动运行slave机器,此时在slave机上可看到控制台信息,在控制机通过监听器-聚合报告或察看结果树可看到执行结果。
添加一个脚本,点击远程启动即可启动运行slave机器,此时在slave机上可看到控制台信息,在控制机通过监听器-聚合报告或察看结果树可看到执行结果。
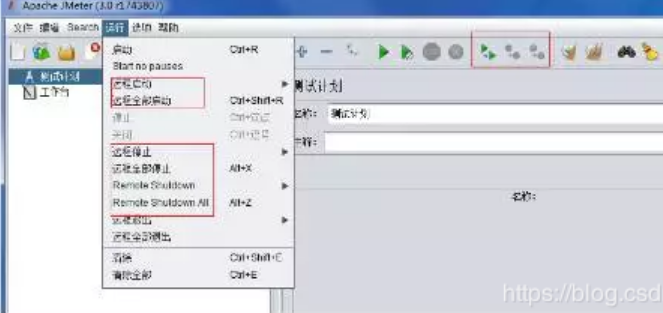
同样的,也可以进行远程停止操作:
 需要注意的问题:
需要注意的问题:
1、修改配置文件后必须重启jmeter才能生效
2、在控制机上远程启动之前,必须先运行slave机的jmeter-server.bat
3、当jmeter脚本中需要依赖csv等数据文件时,该文件需上传至slave机,并需要设置正确的路径。
4、先配置一个slave机成功后,再依次配置多个slave机
5、当slave机是linux系统时,一般只配置一个slave机即可,除非并发特别大时,才需要配置多个slave.
6、分布式运行时,总并发数是脚本中设置的线程数 * slave机的个数,如线程数设置为10,使用3个slave机运行,则总并发数是30.
Linux内网网络测速
一、iperf 和 iperf3 介绍
perf是一个网络性能测试工具。
- 可以测试TCP和UDP带宽质量,
- -可以测量最大TCP带宽,
- 具有多种参数和UDP特性,
- 可以报告带宽,
- 延迟抖动
- 数据包丢失。
- Iperf在linux和windows平台均有二进制版本供自由使用。
iperf3是用来测量一个网络最大带宽的工具。
- 它支持调节各种参数比如发送持续时间,
- 发送/接收缓存,
- 通信协议。
- 每次测试,它都会报告网络带宽,丢包率和其他参数。
- 更多信息请登陆官网:https://iperf.fr/
二、安装
rpm -i iperf3-3.1.3-1.fc24.x86_64.rpm
或
yum install iperf3.x86_64 -y
ipert 和 ipert3 服务和客户端
1、iperf
server端:
iperf -s -p 25001 -B 192.168.33.103 (-u)
- s 指定server端
- p 指定端口(要和客户端一致)
- B 绑定ip地址
- u udp协议,,默认是tcp协议
client端:
iperf -c -p 25001 -B 192.168.33.104 -4 -f K -n 10M -b 10M (-u)
- c 指定client端
- p 指定端口(要和服务器端一致)
- B 绑定客户端的ip地址
- 4 指定ipv4
- f 格式化带宽数输出
- n 指定传输的字节数
- b 使用带宽数量
- u 指定udp协议
2、iperf3
server端:
iperf3 -s -p 25001
- s 指定服务器端
- p 指定端口号
iperf3的server端不支持“-u”参数,,默认可以测试tcp和udp
client端:
iperf3 -c -p 25001 -B 192.168.33.104 -4 -f K -n 10M -b 10M --get-server-output(-u)
- c 指定client端
- p 指定端口(要和服务器端一致)
- B 绑定客户端的ip地址
- 4 指定ipv4
- f 格式化带宽数输出
- n 指定传输的字节数
- b 使用带宽数量
- u 指定udp协议
--get-server-output 获取来自服务器端的结果
区别:
1、iperf3不支持双工模式测试
本机连接测试
- 服务器端:在t1中输入命令:
iperf3 -s
- 客户端:在t2中输入命令:
iperf3 -c 127.0.0.1 -t 10
本例中t2向t1发送10秒中的数据包
- 结果
[root@iZbp11sdj1sc8o3r17rnwgZ ~]# iperf3 -s
-----------------------------------------------------------
Server listening on 5201
-----------------------------------------------------------
Accepted connection from 127.0.0.1, port 44816
[ 5] local 127.0.0.1 port 5201 connected to 127.0.0.1 port 44818
[ ID] Interval Transfer Bitrate
[ 5] 0.00-1.00 sec 4.18 GBytes 35.9 Gbits/sec
[ 5] 1.00-2.00 sec 3.61 GBytes 31.0 Gbits/sec
[ 5] 2.00-3.00 sec 4.27 GBytes 36.7 Gbits/sec
[ 5] 3.00-4.00 sec 3.56 GBytes 30.5 Gbits/sec
[ 5] 4.00-5.00 sec 4.43 GBytes 38.1 Gbits/sec
[ 5] 5.00-6.00 sec 3.67 GBytes 31.5 Gbits/sec
[ 5] 6.00-7.00 sec 4.45 GBytes 38.2 Gbits/sec
[ 5] 7.00-8.00 sec 4.45 GBytes 38.2 Gbits/sec
[ 5] 8.00-9.00 sec 4.36 GBytes 37.5 Gbits/sec
[ 5] 9.00-10.00 sec 4.09 GBytes 35.1 Gbits/sec
[ 5] 10.00-10.04 sec 116 MBytes 25.0 Gbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate
[ 5] 0.00-10.04 sec 41.2 GBytes 35.2 Gbits/sec receiver
-----------------------------------------------------------
Server listening on 5201
-----------------------------------------------------------
[root@iZbp11sdj1sc8o3r17rnwgZ ~]# iperf3 -c 127.0.0.1 -t 10
Connecting to host 127.0.0.1, port 5201
[ 5] local 127.0.0.1 port 44818 connected to 127.0.0.1 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 4.30 GBytes 36.9 Gbits/sec 1 3.06 MBytes
[ 5] 1.00-2.00 sec 3.61 GBytes 31.0 Gbits/sec 2 3.31 MBytes
[ 5] 2.00-3.00 sec 4.27 GBytes 36.7 Gbits/sec 1 3.31 MBytes
[ 5] 3.00-4.00 sec 3.56 GBytes 30.5 Gbits/sec 1 3.31 MBytes
[ 5] 4.00-5.00 sec 4.43 GBytes 38.1 Gbits/sec 0 3.31 MBytes
[ 5] 5.00-6.00 sec 3.67 GBytes 31.5 Gbits/sec 0 3.12 MBytes
[ 5] 6.00-7.00 sec 4.45 GBytes 38.2 Gbits/sec 0 3.12 MBytes
[ 5] 7.00-8.00 sec 4.44 GBytes 38.2 Gbits/sec 0 3.12 MBytes
[ 5] 8.00-9.00 sec 4.37 GBytes 37.5 Gbits/sec 0 3.12 MBytes
[ 5] 9.00-10.00 sec 4.09 GBytes 35.1 Gbits/sec 5 3.12 MBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 41.2 GBytes 35.4 Gbits/sec 10 sender
[ 5] 0.00-10.04 sec 41.2 GBytes 35.2 Gbits/sec receiver
iperf Done.
在并发度默认为 1 且未做任何调优的情况下,传输就达到了 41Mbps。
网卡流量监控
iftop
iftop可以用来监控网卡的实时流量(可以指定网段)、反向解析IP、显示端口信息等

界面参数说明
=>代表发送数据
<=代表接收数据
TX:发送流量
RX:接收流量
TOTAL:总流量
Cumm:运行iftop到目前时间的总流量
peak:流量峰值
rates:分别表示过去 2s 10s 40s 的平均流量
常用的命令参数
-i设定监测的网卡,如:# iftop -i eth1
-B 以bytes为单位显示流量(默认是bits),如:# iftop -B
-n使host信息默认直接都显示IP,如:# iftop -n
-N使端口信息默认直接都显示端口号,如: # iftop -N
-F显示特定网段的进出流量,如# iftop -F 10.10.1.0/24或# iftop -F 10.10.1.0/255.255.255.0
-h(display this message),帮助,显示参数信息
-p使用这个参数后,中间的列表显示的本地主机信息,出现了本机以外的IP信息;
-b使流量图形条默认就显示;
-f这个暂时还不太会用,过滤计算包用的;
-P使host信息及端口信息默认就都显示;
-m设置界面最上边的刻度的最大值,刻度分五个大段显示,例:# iftop -m 100M
-P显示端口号
用法示例:
#显示网卡eth0的信息,主机通过ip显示
> iftop -i eth0 -n
#显示端口号(添加-P参数,进入界面可通过p参数关闭)
> iftop -n -P
#显示将输出以byte为单位显示网卡流量,默认是bit
> iftop -i eth0 -n -B
#显示流量进度条
> iftop -i eth0 -n(进入界面后按下L)
#显示每个连接的总流量
> iftop -i eth0 -n(进入界面后按下T)
#显示指定ip 8.8.8.8的流量
> iftop -i eth0 -n(进入界面后按下l,输入8.8.8.8回车)
nethogs
有很多适用于Linux系统的开源网络监视工具.比如说,你可以用命令iftop来检查带宽使用情况. netstat用来查看接口统计报告,还有top监控系统当前运行进程.但是如果你想要找一个能够按进程实时统计网络带宽利用率的工具,那么NetHogs值得一看。
NetHogs是一个小型的net top工具,不像大多数工具那样拖慢每个协议或者是每个子网的速度而是按照进程进行带宽分组.NetHogs不需要依赖载入某个特殊的内核模块. 如果发生了网络阻塞你可以启动NetHogs立即看到哪个PID造成的这种状况.这样就很容易找出哪个程序跑飞了然后突然占用你的带宽.
简单地说,可以通过nethogs查看linux下进程的流量。
nethogs --help
# nethogs --help
nethogs: invalid option -- '-'
usage: nethogs [-V] [-b] [-d seconds] [-t] [-p] [device [device [device ...]]]
-V : prints version.
-d : delay for update refresh rate in seconds. default is 1.
-t : tracemode.
-b : bughunt mode - implies tracemode.
-p : sniff in promiscious mode (not recommended).
device : device(s) to monitor. default is eth0
When nethogs is running, press:
q: quit
m: switch between total and kb/s mode
实例1:设置5秒钟刷新一次,通过-d来指定刷新频率
# nethogs -d 5
实例2:监视eth0网络带宽
# nethogs eth0
实例3:同时监视eth0和eth1接口
# nethogs eth0 eth1
交互命令:
以下是NetHogs的一些交互命令(键盘快捷键)
m : 修改单位
r : 按流量排序
s : 按发送流量排序
q : 退出命令提示符
关于NetHogs命令行工具的完整参数列表,可以参考NetHogs的手册,使用方法是在终端里输入man nethogs。更多信息请参考nethogs主页:
GitHub - raboof/nethogs: Linux 'net top' tool
https://github.com/raboof/nethogs#readme
iptraf
iptraf是一个基于ncurses开发的IP局域网监控工具,它可以实时地监视网卡流量,可以生成各种网络统计数据,包括TCP信息、UDP统计、ICMP和OSPF信息、以太网负载信息、节点统计、IP校验和错误和其它一些信息。
iptraf的参数列表
iptraf后面加上不同的参数,可以起到不同的作用,下面是iptraf的参数命令列表:
| 参数命令 | 作用 |
|---|---|
| -i iface | 网络接口:立即在指定网络接口上开启IP流量监视,iface为all指监视所有的网络接口,iface指相应的interface |
| -g | 立即开始生成网络接口的概要状态信息 |
| -d iface | 网络接口:在指定网络接口上立即开始监视明细的网络流量信息,iface指相应的interface |
| -s iface | 网络接口:在指定网络接口上立即开始监视TCP和UDP网络流量信息,iface指相应的interface |
| -z iface | 网络接口:在指定网络接口上显示包计数,iface指相应的interface |
| -l iface | 网络接口:在指定网络接口上立即开始监视局域网工作站信息,iface指相应的interface |
| -t timeout | 时间:指定iptraf指令监视的时间,timeout指监视时间的minute数 |
| -B | 将标注输出重新定向到“/dev/null”,关闭标注输入,将程序作为后台进程运行 |
| -L logfile | 指定一个文件用于记录所有命令行的log,默认文件是地址:/var/log/iptraf |
| -I interval | 指定记录log的时间间隔(单位是minute),不包括IP traffic monitor |
| -u | 允许使用不支持的接口作为以太网设备 |
| -f | 清空所有计数器 |
| -h | 显示帮助信息 |
高并发、大流量网卡调优
下面是关于网卡调优的相关知识,欢迎大家共同探讨,让我们的机器跑的更high。
1、Broadcom的网卡建议关闭GRO功能
ethtool -K eth0 gro off
ethtool -K eth1 gro off
ethtool -K eth2 gro off
ethtool -K eth3 gro off
2、关闭irqbalance服务并手动分配网卡中断
service irqbalance stop
chkconfig irqbalance off
# 查看网卡中断号
grep ethx /proc/interrupts
# 分配到每颗颗CPU核上
cat /proc/irq/{84,85,86,87,88,89,90,91,92,93}/smp_affinity
echo 1 > /proc/irq/84/smp_affinity
echo 2 > /proc/irq/85/smp_affinity
echo 4 > /proc/irq/86/smp_affinity
echo 8 > /proc/irq/87/smp_affinity
echo 10 > /proc/irq/88/smp_affinity
echo 20 > /proc/irq/89/smp_affinity
echo 40 > /proc/irq/90/smp_affinity
echo 80 > /proc/irq/91/smp_affinity
echo 100 > /proc/irq/92/smp_affinity
echo 200 > /proc/irq/93/smp_affinity
PS:smp_affinity的值可以用下面脚本算哈,此脚本来自:http://rfyiamcool.blog.51cto.com/1030776/1335700
#!/bin/bash
#
echo "统计cpu的16进制"
[ $# -ne 1 ] && echo ‘$1 is Cpu core number’ && exit 1
CCN=$1
echo “Print eth0 affinity”
for((i=0; i<${CCN}; i++))
do
echo ==============================
echo "Cpu Core $i is affinity"
((affinity=(1<<i)))
echo "obase=16;${affinity}" | bc
done
使用方法:sh 脚本名字 空格 cpu核数
3、开启网卡的RPS功能 (Linux内核2.6.38或以上版本支持)
# Enable RPS (Receive Packet Steering)
rfc=4096
cc=$(grep -c processor /proc/cpuinfo)
rsfe=$(echo $cc*$rfc | bc)
sysctl -w net.core.rps_sock_flow_entries=$rsfe
for fileRps in $(ls /sys/class/net/eth*/queues/rx-*/rps_cpus)
do
echo fff > $fileRps
done
for fileRfc in $(ls /sys/class/net/eth*/queues/rx-*/rps_flow_cnt)
do
echo $rfc > $fileRfc
done
tail /sys/class/net/eth*/queues/rx-*/{rps_cpus,rps_flow_cnt}
献上一个完整的脚本:
vi /opt/sbin/change_irq.sh
#!/bin/bash
ethtool -K eth0 gro off
ethtool -K eth1 gro off
ethtool -K eth2 gro off
ethtool -K eth3 gro off
service irqbalance stop
chkconfig irqbalance off
cat /proc/irq/{84,85,86,87,88,89,90,91,92,93}/smp_affinity
echo 1 > /proc/irq/84/smp_affinity
echo 2 > /proc/irq/85/smp_affinity
echo 4 > /proc/irq/86/smp_affinity
echo 8 > /proc/irq/87/smp_affinity
echo 10 > /proc/irq/88/smp_affinity
echo 20 > /proc/irq/89/smp_affinity
echo 40 > /proc/irq/90/smp_affinity
echo 80 > /proc/irq/91/smp_affinity
echo 100 > /proc/irq/92/smp_affinity
echo 200 > /proc/irq/93/smp_affinity
# Enable RPS (Receive Packet Steering)
rfc=4096
cc=$(grep -c processor /proc/cpuinfo)
rsfe=$(echo $cc*$rfc | bc)
sysctl -w net.core.rps_sock_flow_entries=$rsfe
for fileRps in $(ls /sys/class/net/eth*/queues/rx-*/rps_cpus)
do
echo fff > $fileRps
done
for fileRfc in $(ls /sys/class/net/eth*/queues/rx-*/rps_flow_cnt)
do
echo $rfc > $fileRfc
done
tail /sys/class/net/eth*/queues/rx-*/{rps_cpus,rps_flow_cnt}
chmod +x /opt/sbin/change_irq.sh
echo "/opt/sbin/change_irq.sh" >> /etc/rc.local
PS:记得修改网卡中断号,别直接拿来用哦
每秒上下文切换数优化

策略: 保持通用的吞吐量的情况下,去调整线程数
vmstat命令
1、介绍
vmstat命令是最常见的Linux/Unix监控工具,属于sysstat包。可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
2、安装
yum install -y sysstat
vmstat 2 1
表示每个两秒采集一次服务器状态,表示只采集一次
vmstat 2
这表示vmstat每2秒采集数据,一直采集,直到我结束程序
3、命令显示字段
| 类别 | 项目 | 含义 | 说明 |
|---|---|---|---|
| Procs(进程) | r | 等待执行的任务数 | 展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。 |
| b | 等待IO的进程数量 | ||
| Memory(内存) | swpd | 正在使用虚拟的内存大小,单位k | |
| free | 空闲内存大小 | ||
| buff | 已用的buff大小,对块设备的读写进行缓冲 | ||
| cache | 已用的cache大小,文件系统的cache | ||
| inact | 非活跃内存大小,即被标明可回收的内存,区别于free和active | ||
| active | 活跃的内存大小 | 具体含义见:概念补充(当使用-a选项时显示) | |
| Swap | si | 每秒从交换区写入内存的大小(单位:kb/s) | |
| so | 每秒从内存写到交换区的大小 | ||
| IO | bi | 每秒读取的块数(读磁盘) | 块设备每秒接收的块数量,单位是block,这里的块设备是指系统上所有的磁盘和其他块设备,现在的Linux版本块的大小为1024bytes |
| bo | 每秒写入的块数(写磁盘) | 块设备每秒发送的块数量,单位是block | |
| system | in | 每秒中断数,包括时钟中断 | 这两个值越大,会看到由内核消耗的cpu时间sy会越多 |
| cs | 每秒上下文切换数 | 秒, 上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目 | |
| CPU(以百分比表示) | us | 用户进程执行消耗cpu时间(user time) | us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
| sy | 系统进程消耗cpu时间(system time) | sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。 | 这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足 |
| Id | 空闲时间(包括IO等待时间) | 一般来说 us+sy+id=100 | |
| wa | 等待IO时间 | wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。 |
4、常用参数
用法
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
5、常见性能问题分析
IO/CPU/men连锁反应
1.free急剧下降
2.buff和cache被回收下降,但也无济于事
3.依旧需要使用大量swap交换分区swpd
4.等待进程数,b增多
5.读写IO,bi bo增多
6.si so大于0开始从硬盘中读取
7.cpu等待时间用于 IO等待,wa增加
内存不足
1.开始使用swpd,swpd不为0
2.si so大于0开始从硬盘中读取
io瓶颈
1.读写IO,bi bo增多超过2000
2.cpu等待时间用于 IO等待,wa增加 超过20
3.sy 系统调用时间长,IO操作频繁会导致增加 >30%
4.wa io等待时间长
iowait% <20% 良好
iowait% <35% 一般
iowait% >50%
5.进一步使用iostat观察
CPU瓶颈:load,vmstat中r列
1.反应为CPU队列长度
2.一段时间内,CPU正在处理和等待CPU处理的进程数之和,直接反应了CPU的使用和申请情况。
3.理想的load average:核数CPU数0.7
CPU个数:grep 'physical id' /proc/cpuinfo | sort -u
核数:grep 'core id' /proc/cpuinfo | sort -u | wc -l
4.超过这个值就说明已经是CPU瓶颈了
CPU瓶颈
1.us 用户CPU时间高超过90%
涉及到web服务器,cs 每秒上下文切换次数
例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
1.cs可以对apache和nginx线程和进程数限制起到一定的参考作用
2.我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了
较好的趋势:主要是 swap使用少,swpd数值低。si so分页读取写入数值趋近于零
6、其他说明:
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
参考文献
https://www.xxshell.com/2664.html
https://blog.csdn.net/DeepMindMan/article/details/66973529
http://t.zoukankan.com/tcicy-p-10193615.html
https://blog.csdn.net/xiao_yi_xiao/article/details/120546346