-
疯狂创客圈 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 面试必备 + 面试必备 【博客园总入口 】
-
疯狂创客圈 经典图书 : 《SpringCloud、Nginx高并发核心编程》 大厂必备 + 大厂必备 + 大厂必备 【博客园总入口 】
-
入大厂+涨工资必备: 高并发【 亿级流量IM实战】 实战系列 【 SpringCloud Nginx秒杀】 实战系列 【博客园总入口 】
JUC 高并发工具类(3文章)与高并发容器类(N文章) :
说明:阅读本文之前,请先掌握本文前置知识: BlockingQueue 阻塞队列 -秒懂-图解。
1 LinkedBlockingQueue的基本概要
LinkedBlockingQueue是一个基于链表的阻塞队列,其内部维持一个基于链表的数据队列,实际上我们对LinkedBlockingQueue的API操作都是间接操作该内部数据队列,
7.5.1 LinkedBlockingQueue 构造函数
LinkedBlockingQueue是一个由链表实现的有界队列阻塞队列,但大小默认值为Integer.MAX_VALUE,所以我们在使用LinkedBlockingQueue时建议手动传值,为其提供我们所需的大小,避免队列过大造成机器负载或者内存爆满等情况。其构造函数如下
/**
* 默认情况下,创建一个容量为 Integer.MAX_VALUE 的 LinkedBlockingQueue
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
/**
* 创建一个具有给定(固定)容量的 LinkedBlockingQueue
*/
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
/**
* 创建一个容量为 Integer.MAX_VALUE 的 LinkedBlockingQueue,
* 最初包含给定 collection 的元素,元素按该 collection 迭代器的遍历顺序添加。
*/
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
for (E e : c)
add(e);
}
三个构造函数的说明如下:
-
默认构造方法创建一个容量为 Integer.MAX_VALUE的 LinkedBlockingQueue实例。
-
第二种构造方法,指定了队列容量,首先判断指定容量是否大于零,否则抛出异常。然后为 capacity 赋值,最后创建空节点,并指向 head与 last,两者的 item与 next此时均为 null。
-
第3种,利用循环向队列中添加指定集合中的元素。
LinkedBlockingQueue队列也是按 FIFO(先进先出)排序元素。队列的头部元素是入队时间最长的元素,队列的尾部元素是在入队时间最短的元素,队列执行获取操作会获得位于队列头部的元素,而新元素会被插入到队列的尾部。
| 说 明 |
|---|
| LinkedBlockingQueue和ArrayBlockingQueue的API几乎是一样的,只是它们的内部实现原理不太相同。 |
使用LinkedBlockingQueue,我们同样也能实现生产者消费者模式。只需把前面ArrayBlockingQueue案例中的阻塞队列对象换成LinkedBlockingQueue即可,这里限于篇幅就不贴重复代码了。
7.5.2 内部成员
LinkedBlockingQueue是一个基于链表的阻塞队列,其内部维持一个基于链表的数据队列,实际上我们对LinkedBlockingQueue的API操作都是间接操作该数据队列,这里我们先看看LinkedBlockingQueue的内部成员变量
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/**
* 节点类,用于存储数据
*/
static class Node<E> {
E item;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next;
Node(E x) { item = x; }
}
/** 阻塞队列的大小,默认为Integer.MAX_VALUE */
private final int capacity;
/** 当前阻塞队列中的元素个数 */
private final AtomicInteger count = new AtomicInteger();
/**
* 阻塞队列的头结点
*/
transient Node<E> head;
/**
* 阻塞队列的尾节点
*/
private transient Node<E> last;
/** 获取并移除元素时使用的锁,如take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** notEmpty条件对象,当队列没有数据时用于挂起执行删除的线程 */
private final Condition notEmpty = takeLock.newCondition();
/** 添加元素时使用的锁如 put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** notFull条件对象,当队列数据已满时用于挂起执行添加的线程 */
private final Condition notFull = putLock.newCondition();
}
在正常情况下,LinkedBlockingQueue的吞吐量要高于基于数组的队列ArrayBlockingQueue,为什么呢?因为前者的添加和删除操作使用的两个显示锁(ReenterLock)来控制并发执行,而ArrayBlockingQueue只是使用一个ReenterLock控制并发。
两个显示锁(ReenterLock)一个控制头部,相当于控制新增元素;一个控制尾部部,相当于控制删除元素;可以简单理解为 读写分离吧。
每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。这里再次强调如果没有给LinkedBlockingQueue指定容量大小,其默认值将是Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出,这点在使用前希望慎重考虑。至于LinkedBlockingQueue的实现原理图与ArrayBlockingQueue是类似的,除了对添加和移除方法使用单独的锁控制外,两者都使用了不同的Condition条件对象作为等待队列,用于挂起take线程和put线程。
ok~,下面我们看看其其内部添加过程和删除过程是如何实现的。
2 非阻塞式添加元素:add、offer方法原理
接下来看看非阻塞式添加元素add方法和offer方法的实现。
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
从源码可以看出,add方法间接调用的是offer方法,如果offer方法添加失败将抛出IllegalStateException异常,offer方法添加成功则返回true,
offer的实现
这里的Offer()方法做了两件事:
(1)第一件事是判断队列是否满,满了就直接释放锁,没满就将节点封装成Node入队,然后再次判断队列添加完成后是否已满,不满就继续唤醒等到在条件对象notFull上的添加线程。
(2)第二件事是,判断是否需要唤醒等到在notEmpty条件对象上的消费线程。
那么下面我们直接看看offer的相关方法实现
public boolean offer(E e) {
//添加元素为null直接抛出异常
if (e == null) throw new NullPointerException();
//获取队列的个数
final AtomicInteger count = this.count;
//判断队列是否已满
if (count.get() == capacity)
return false;
int c = -1;
//构建节点
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
//再次判断队列是否已满,考虑并发情况
if (count.get() < capacity) {
enqueue(node);//添加元素
c = count.getAndIncrement();//拿到当前未添加新元素时的队列长度
//如果容量还没满
if (c + 1 < capacity)
notFull.signal();//唤醒下一个添加线程,执行添加操作
}
} finally {
putLock.unlock();
}
// 由于存在添加锁和消费锁,而消费锁和添加锁都会持续唤醒等到线程,因此count肯定会变化。
//这里的if条件表示如果队列中还有1条数据
if (c == 0)
signalNotEmpty();//如果还存在数据那么就唤醒消费锁
return c >= 0; // 添加成功返回true,否则返回false
}
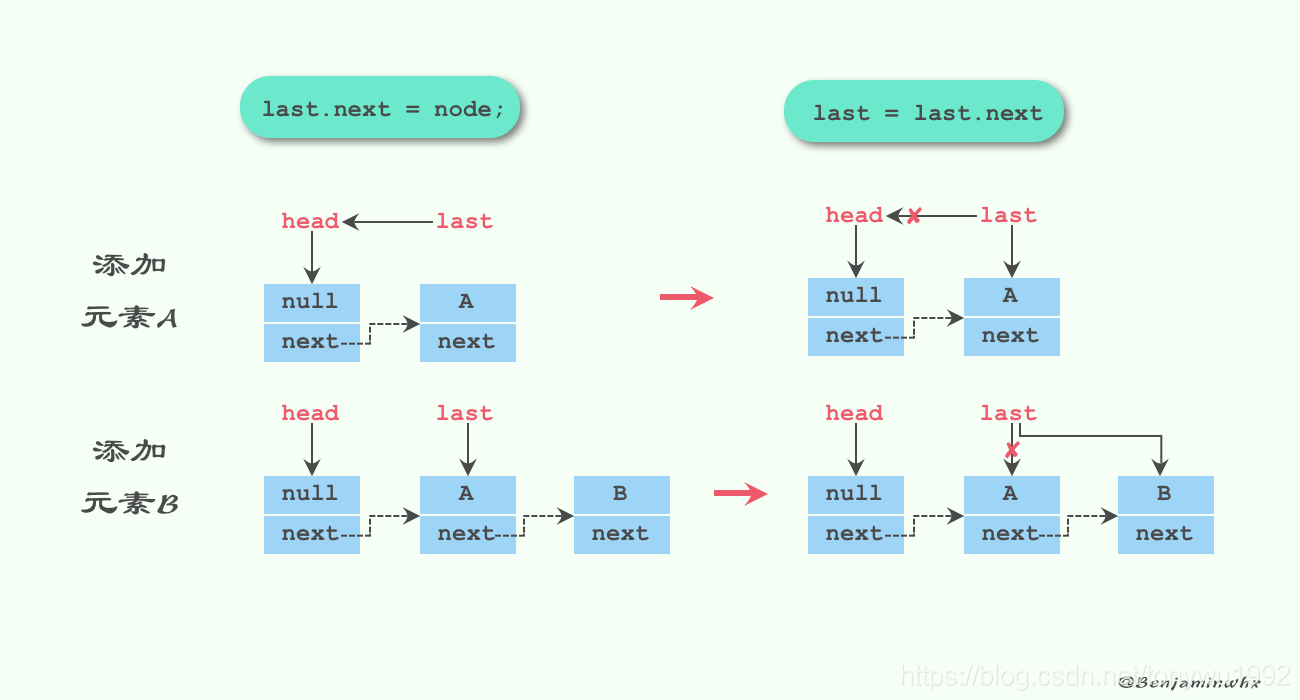
enqueue入队操作
//入队操作
private void enqueue(Node
//队列尾节点指向新的node节点
last = last.next = node;
}
来看看往队列里依次放入元素A和元素B,具体如下图:
signalNotEmpty唤醒 删除线程(如消费者线程)
//signalNotEmpty方法
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
//唤醒获取并删除元素的线程
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
这里我们可能会有点疑惑,为什么添加完成后是继续唤醒在条件对象notFull上的添加线程,而不是像ArrayBlockingQueue那样直接唤醒notEmpty条件对象上的消费线程?而又为什么要当if (c == 0)时才去唤醒消费线程呢?
唤醒添加线程的原因,在添加新元素完成后,会判断队列是否已满,不满就继续唤醒在条件对象notFull上的添加线程,这点与前面分析的ArrayBlockingQueue很不相同,在ArrayBlockingQueue内部完成添加操作后,会直接唤醒消费线程对元素进行获取,这是因为ArrayBlockingQueue只用了一个ReenterLock同时对添加线程和消费线程进行控制,这样如果在添加完成后再次唤醒添加线程的话,消费线程可能永远无法执行,而对于LinkedBlockingQueue来说就不一样了,其内部对添加线程和消费线程分别使用了各自的ReenterLock锁对并发进行控制,也就是说添加线程和消费线程是不会互斥的,所以添加锁只要管好自己的添加线程即可,添加线程自己直接唤醒自己的其他添加线程,如果没有等待的添加线程,直接结束了。如果有就直到队列元素已满才结束挂起,当然offer方法并不会挂起,而是直接结束,只有put方法才会当队列满时才执行挂起操作。注意消费线程的执行过程也是如此。这也是为什么LinkedBlockingQueue的吞吐量要相对大些的原因。
为什么要判断if (c == 0)时才去唤醒消费线程呢?
if (c == 0) //c拿到当前未添加新元素时的队列长度
signalNotEmpty();//如果还存在数据那么就唤醒消费锁
这是因为消费线程一旦被唤醒是一直在消费的(前提是有数据),所以c值是一直在变化的,c值是添加完元素前队列的大小,此时c只可能是0或c>0,如果是c=0,那么说明之前消费线程已停止,条件对象上可能存在等待的消费线程,添加完数据后应该是c+1,那么有数据就直接唤醒等待消费线程,如果没有就结束啦,等待下一次的消费操作。如果c>0那么消费线程就不会被唤醒,只能等待下一个消费操作(poll、take、remove)的调用,那为什么不是条件c>0才去唤醒呢?我们要明白的是消费线程一旦被唤醒会和添加线程一样,一直不断唤醒其他消费线程,如果添加前c>0,那么很可能上一次调用的消费线程后,数据并没有被消费完,条件队列上也就不存在等待的消费线程了,所以c>0唤醒消费线程得意义不是很大,当然如果添加线程一直添加元素,那么一直c>0,消费线程执行的换就要等待下一次调用消费操作了(poll、take、remove)。
3 阻塞式添加元素:put 方法原理
添加元素的方法有:add,offer以及put。这里先介绍阻塞式添加元素的方法——put 方法。
/**
* 将指定元素插入到此队列的尾部,如有必要,则等待空间变得可用
*/
public void put(E e) throws InterruptedException {
//判断添加元素是否为null
if (e == null)
throw new NullPointerException();
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
//获取插入的可中断锁
putLock.lockInterruptibly();
try {
try {
//判断队列是否已满
while (count.get() == capacity)
//如果已满则阻塞添加线程
notFull.await();
} catch (InterruptedException ie) {
//失败就唤醒添加线程
notFull.signal();
throw ie;
}
//添加元素
insert(e);
//修改c值
c = count.getAndIncrement();
//根据c值判断队列是否已满
if (c + 1 < capacity)
//未满则唤醒添加线程
notFull.signal();
} finally {
//释放锁
putLock.unlock();
}
//c等于0代表添加成功
if (c == 0)
signalNotEmpty();
}
总结一下添加操作流程
1.获取putLock锁
2.如果队列已满, 则等待(notFull.await())
3.元素入队
4.当前生产者添加元素之后如果队列还没有满, 则通知其他生产者添加元素(notFull.signal())
5.释放putLock锁
6.如果队列中已经有元素,则通知消费者
图解:put线程的阻塞过程
在添加元素时,如果队列已满,那么新到来的put线程将被添加到notFull条件等待队列中,具体如下图所示:

图:队列满时put线程加入notFull等待队列示意
notFull 条件队列与putLock 显示锁关联,而不是与takeLock显示锁关联。putLock 显示锁负责对元素添加进行同步,具体的代码如下:
/** putLock显示锁 */
private final ReentrantLock putLock = new ReentrantLock();
/**putLock 条件队列与putLock显示锁关联 */
private final Condition notFull = putLock.newCondition();
4 非阻塞式移除:poll方法原理
poll方法也比较简单,如果队列没有数据,就返回null。
如果队列有数据,那么就poll方法取出来。
取到之后,如果队列还有数据,那么唤醒等待在条件对象notEmpty上的消费线程。让那些线程也来取得数据。
最后,判断if (c == capacity),为true就唤醒生产(或添加)线程,这点与前面分析if(c==0)是一样的道理。因为只有可能队列满了,notFull条件对象上才可能存在等待的添加线程。
public E poll() {
//获取当前队列的大小
final AtomicInteger count = this.count;
if (count.get() == 0)//如果没有元素直接返回null
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
//判断队列是否有数据
if (count.get() > 0) {
//如果有,直接删除并获取该元素值
x = dequeue();
//当前队列大小减一
c = count.getAndDecrement();
//如果队列未空,继续唤醒等待在条件对象notEmpty上的消费线程
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
//判断c是否等于capacity,这是因为如果满说明NotFull条件对象上
//可能存在等待的添加线程
if (c == capacity)
signalNotFull();
return x;
}
dequeue
从头部删除元素
private E dequeue() {
Node<E> h = head;//获取头结点
Node<E> first = h.next; 获取头结的下一个节点(要删除的节点)
h.next = h; // help GC//自己next指向自己,即被删除
head = first;//更新头结点
E x = first.item;//获取删除节点的值
first.item = null;//清空数据,因为first变成头结点是不能带数据的,这样也就删除队列的带数据的第一个节点
return x;
}

5 阻塞式移除元素:take方法原理
take方法是一个可阻塞可中断的移除方法,主要做了两件事:
一是,如果队列没有数据就挂起当前线程到 notEmpty条件对象的等待队列中一直等待,如果有数据就删除节点并返回数据项,同时唤醒后续消费线程,
二是尝试唤醒条件对象notFull上等待队列中的添加线程。 到此关于remove、poll、take的实现也分析完了,其中只有take方法具备阻塞功能。
public E take() throws InterruptedException {
E x;
int c = -1;
//获取当前队列大小
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();//可中断
try {
//如果队列没有数据,挂机当前线程到条件对象的等待队列中
while (count.get() == 0) {
notEmpty.await();
}
//如果存在数据直接删除并返回该数据
x = dequeue();
c = count.getAndDecrement();//队列大小减1
if (c > 1)
notEmpty.signal();//还有数据就唤醒后续的消费线程
} finally {
takeLock.unlock();
}
//满足条件,唤醒条件对象上等待队列中的添加线程
if (c == capacity)
signalNotFull();
return x;
}
remove方法则是成功返回true失败返回false,poll方法成功返回被移除的值,失败或没数据返回null。
图解:take线程的阻塞过程

图:队列空时take线程被阻塞
notEmpty条件队列与takeLock显示锁 关联,而不是与putLock显示锁 关联。takeLock显示锁负责对元素删除进行同步,具体的代码如下:
/** takeLock显示锁 */
private final ReentrantLock takeLock = new ReentrantLock();
/**notEmpty条件队列与takeLock显示锁关联 */
private final Condition notEmpty = takeLock.newCondition();
6 提取元素:peek和element
下面再看看两个获取元素的方法,即peek和element
public E element() {
E x = peek();//直接调用peek
if (x != null)
return x;
else
throw new NoSuchElementException();//没数据抛异常
}
peek方法从头节点直接就可以获取到第一个添加的元素,所以效率是比较高的。如果不存在则返回null。
/**
* 获取但不移除此队列的头;如果此队列为空,则返回 null
*/
public E peek() {
//判断元素数是否为0
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
//获取获取锁
takeLock.lock();
try {
//头节点的 next节点即为添加的第一个节点
Node<E> first = head.next;
//如果不为空则返回该节点
if (first == null)
return null;
else
return first.item;
} finally {
//释放锁
takeLock.unlock();
}
}
从代码来看,head头结节点在初始化时是本身不带数据的,仅仅作为头部head方便我们执行链表的相关操作。peek返回直接获取头结点的下一个节点返回其值,如果没有值就返回null,有值就返回节点对应的值。
7 移除元素 remove的实现原理
关于移除的方法主要是指remove和poll以及take方法,下面一一分析
public boolean remove(Object o) {
if (o == null) return false;
fullyLock();//同时对putLock和takeLock加锁
try {
//循环查找要删除的元素
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
if (o.equals(p.item)) {//找到要删除的节点
unlink(p, trail);//直接删除
return true;
}
}
return false;
} finally {
fullyUnlock();//解锁
}
}
//两个同时加锁
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
remove方法删除指定的对象,这里我们可能会诧异,为什么同时对putLock和takeLock加锁?这是因为remove方法删除的数据的位置不确定,为了避免造成并非安全问题,所以需要对2个锁同时加锁。
8 LinkedBlockingQueue和ArrayBlockingQueue迥异
通过上述的分析,对于LinkedBlockingQueue和ArrayBlockingQueue的基本使用以及内部实现原理我们已较为熟悉了,这里我们就对它们两间的区别来个小结
1.队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
2.数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
3.由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
4.两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
参考资料1:https://www.cnblogs.com/KingIceMou/p/8075343.html
参考资料2:https://blog.csdn.net/tonywu1992/article/details/83419448
参考资料3:https://blog.csdn.net/tonywu1992/article/details/83419448
回到◀疯狂创客圈▶
疯狂创客圈 - Java高并发研习社群,为大家开启大厂之门