一.概述及设计目标
分布式文件系统是为了让文件多副本存储,当某个节点瘫痪,在另外的节点可以访问到副本,提高系统可靠性。这是传统的设计方法。但也存在缺点:
1)不管文件多大,都存储在一个节点上,在进行数据处理的时候很难进行并行处理,节点成为网络瓶颈,很难进行大数据处理;
2)存储负载不均衡,每个节点利用率很低
什么是HDFS?
- Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS
- 源于Google的GFS论文
HDFS的设计目标
- 巨大的分布式文件系统
- 运行在普通廉价的硬件上
- 易扩展
架构图:
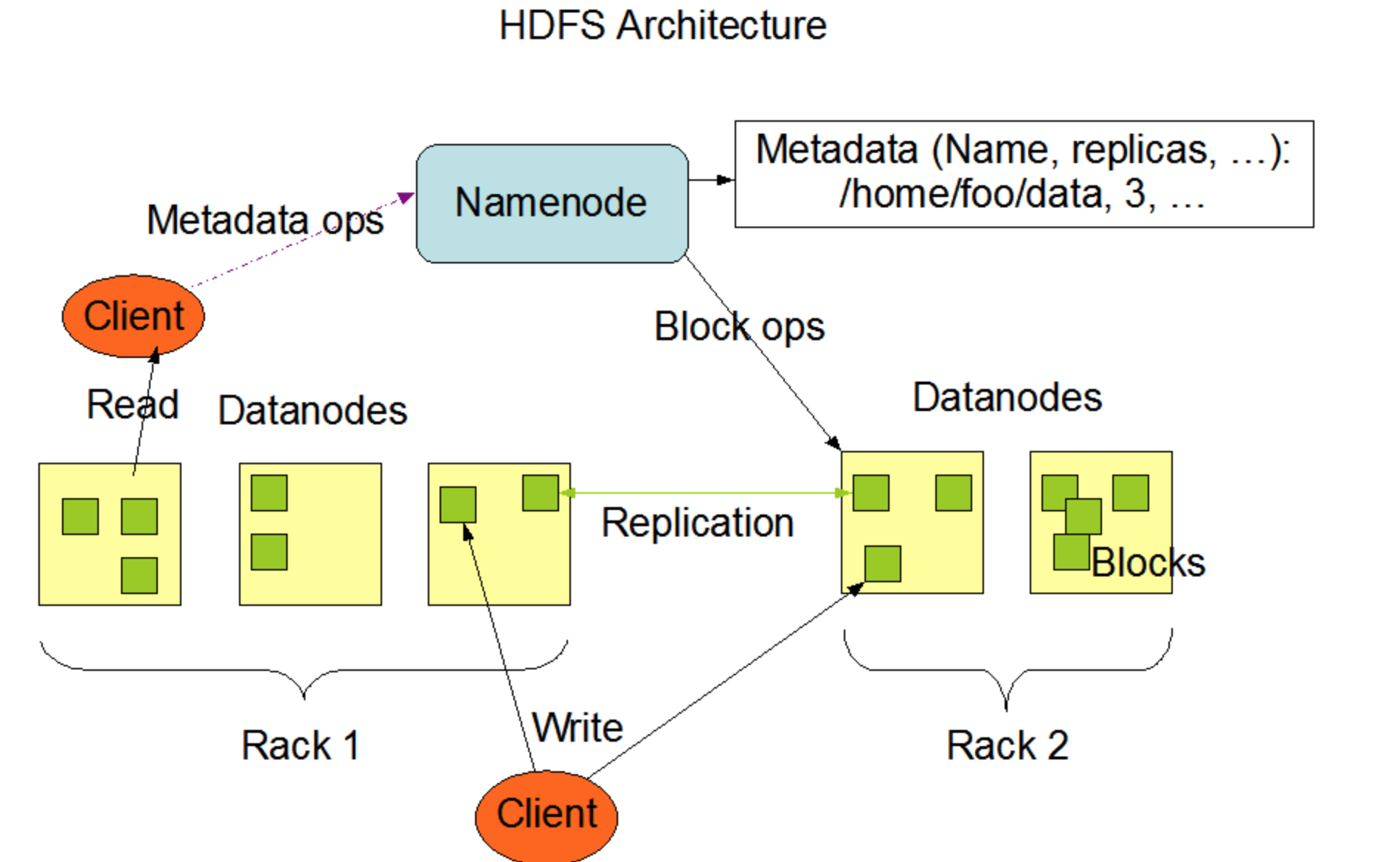
一个文件会被拆分成多个Block
blocksize:128M
130M==>2个Block:128M 和 2M
NN:
1)负责客户端请求的响应
2)元数据的管理
DN:
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
一个典型的部署架构是运行一个NameNode节点,集群里每一个其他机器运行一个DataNode节点。
实际生产环境中建议:NameNode、DataNode部署在不同节点上。
二.单机的伪分布式集群搭建
环境:Centos7
1.jdk安装
省略
2.安装SSH
sudo yum install ssh
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
3.安装hadoop
1)官网下载,我选择的版本是第三方商业化版本cdh,hadoop-2.6.0-cdh5.7.0。
2)解压 tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C ~/app/
4.配置文件修改
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.102:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/app/tmp</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
5.启动hdfs
格式化(第一次执行即可):
cd bin
./hadoop namenode -format
cd sbin
./start-dfs.sh
验证是否成功:
jps
Jps
SecondaryNameNode
DataNode
NameNode
或者浏览器验证:http://192.168.56.102:50070
6.停止hdfs
cd sbin
./stop-dfs.sh
三.Java API操作HDFS文件
- IDEA+Maven创建Java工程
- 添加HDFS相关依赖--pom.xml


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.imooc.hadoop</groupId> <artifactId>hadoop-train</artifactId> <version>1.0</version> <name>hadoop-train</name> <!-- FIXME change it to the project's website --> <url>http://www.example.com</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <hadoop.version>2.6.0-cdh5.7.0</hadoop.version> </properties> <repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> </dependencies> <build> <pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) --> <plugins> <plugin> <artifactId>maven-clean-plugin</artifactId> <version>3.0.0</version> </plugin> <!-- see http://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging --> <plugin> <artifactId>maven-resources-plugin</artifactId> <version>3.0.2</version> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> </plugin> <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>2.20.1</version> </plugin> <plugin> <artifactId>maven-jar-plugin</artifactId> <version>3.0.2</version> </plugin> <plugin> <artifactId>maven-install-plugin</artifactId> <version>2.5.2</version> </plugin> <plugin> <artifactId>maven-deploy-plugin</artifactId> <version>2.8.2</version> </plugin> </plugins> </pluginManagement> </build> </project>
- HDFSApp.java
package com.cracker.hadoop.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.util.Progressable; import org.junit.After; import org.junit.Before; import org.junit.Test; import javax.swing.*; import java.io.BufferedInputStream; import java.io.File; import java.io.FileInputStream; import java.io.InputStream; import java.net.URI; /** * Hadoop HDFS Java API 操作 */ public class HDFSApp { public static final String HDFS_PATH = "hdfs://192.168.56.102:8020"; FileSystem fileSystem = null; Configuration configuration = null; /** * 创建HDFS目录 * @throws Exception */ @Test public void mkdir() throws Exception { fileSystem.mkdirs(new Path("/hdfsapi/test")); } /** * 创建文件 */ @Test public void create() throws Exception { FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test/a.txt")); output.write("hello hadoop".getBytes()); output.flush(); output.close(); } /** * 查看HDFS文件上的内容 */ @Test public void cat() throws Exception { FSDataInputStream in = fileSystem.open(new Path("/hdfsapi/test/a.txt")); IOUtils.copyBytes(in, System.out, 1024); in.close(); } /** * 重命名 */ @Test public void rename() throws Exception { Path oldPath = new Path("/hdfsapi/test/a.txt"); Path newPath = new Path("/hdfsapi/test/b.txt"); fileSystem.rename(oldPath, newPath); } /** * 上传文件到HDFS */ @Test public void copyFromLocalFile() throws Exception { Path localPath = new Path("/Users/chen/Downloads/hello2.txt"); Path hdfsPath = new Path("/hdfsapi/test"); fileSystem.copyFromLocalFile(localPath, hdfsPath); } /** * 上传文件到HDFS */ @Test public void copyFromLocalFileWithProgress() throws Exception { Path localPath = new Path("/Users/chen/Downloads/hello2.txt"); Path hdfsPath = new Path("/hdfsapi/test"); fileSystem.copyFromLocalFile(localPath, hdfsPath); InputStream in = new BufferedInputStream( new FileInputStream( new File("/Users/chen/Downloads/hive.tar.gz"))); FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test/hive1.0.tar.gz"), new Progressable() { public void progress() { System.out.print("."); } }); IOUtils.copyBytes(in, output, 4096); } public void copyToLocalFile() throws Exception { Path localPath = new Path("/Users/chen/Downloads/h.txt"); Path hdfsPath = new Path("/hdfsapi/test/b.txt"); fileSystem.copyToLocalFile(hdfsPath, localPath); } /** * 查看某个目录下所有文件 */ @Test public void listFiles() throws Exception { FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/hdfsapi/test")); for (FileStatus fileStatus : fileStatuses) { String isDir = fileStatus.isDirectory()?"文件夹" : "文件"; short replication = fileStatus.getReplication(); long len = fileStatus.getLen(); String path = fileStatus.getPath().toString(); System.out.println(isDir + " " + replication + " " + len + " " +path); } } @Test public void delete() throws Exception { fileSystem.delete(new Path("/hdfsapi/test")); } @Before public void setUp() throws Exception{ System.out.println("HDFSApp.setUp"); configuration =new Configuration(); fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "root"); } @After public void tearDown() throws Exception{ configuration = null; fileSystem = null; System.out.println("HDFSApp.tearDown"); } }