源码仓库
https://github.com/Cpaulyz/BigDataAnalysis/tree/master/Assignment3
工作流程
尝试
本次作业的难点在于OCR,对于OCR开源库/API/工具的使用
经过初步分析,认为本次OCR的目标有两个难点
- 手写
- 数学公式
因此,本人先后进行了以下尝试
- python的TesseractOCR库,无法识别
- 讯飞OCR API,无法识别
- 百度OCR API,无法识别
- 腾讯OCR API,无法识别
- Mathpix,可识别
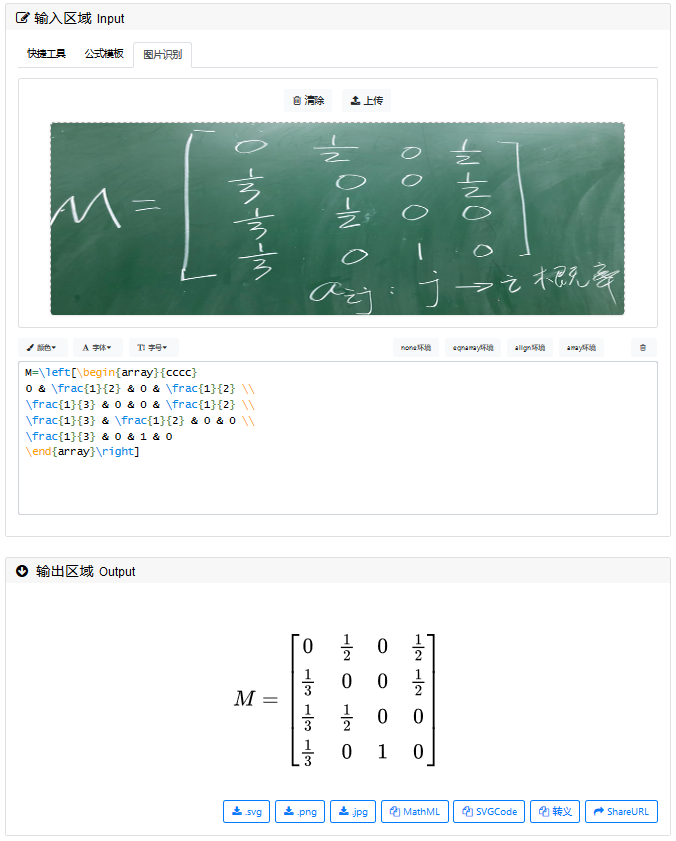
因此,最终选取Mathpix作为OCR部分的工具
思路
Mathpix的图像识别特殊之处在于,它将识别数学公式并将其转换为latex
因此,工作思路如下图所示:

1 OCR
OCR部分采用的是Mathpix提供的服务(https://mathpix.com/)
但由于Mathpix需要收费,且需要信用卡注册,这边取巧使用了国内的一个翻版网站提供的服务(https://www.latexlive.com/##)
通过监控其HTTP请求,可以看到其图像识别的请求API是对mathpix服务的封装,因此可以认为是一致的
响应内容为latex文本
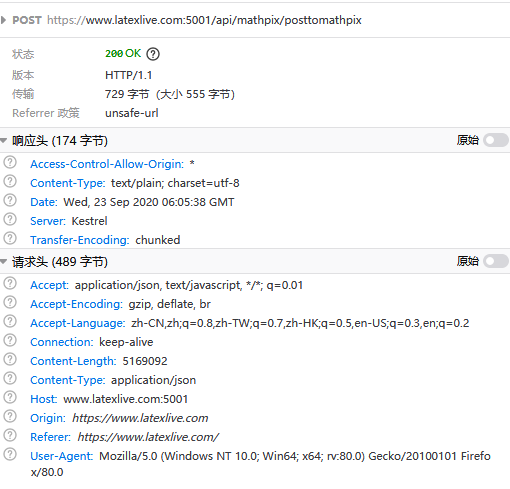
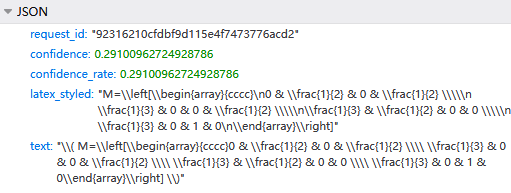
考虑到如果是1万张图片呢的情况,我们必须使用python脚本对其请求进行封装,以实现自动化和可修改性
import base64
import json
import requests
def encode_base64(file):
with open(file, 'rb') as f:
img_data = f.read()
base64_data = base64.b64encode(img_data)
# 如果想要在浏览器上访问base64格式图片,需要在前面加上:data:image/jpeg;base64,
base64_str = str(base64_data, 'utf-8')
return base64_str
# 传入本地图片路径,发起请求,返回latex文本
def get_latex_from_file(img_path: str):
base64code = encode_base64(img_path)
url = "https://www.latexlive.com:5001/api/mathpix/posttomathpix"
# headers = {'Content-Type': 'application/json'}
payload = {"src": "data:image/png;base64," + base64code}
r = requests.post(url, json=payload)
print(r.text)
content = json.loads(r.text).get('latex_styled')
print(content)
return content
返回结果如下
N=left[egin{array}{cccc}
0 & frac{1}{2} & 0 & frac{1}{2} \
frac{1}{3} & 0 & 0 & frac{1}{2} \
frac{1}{3} & frac{1}{2} & 0 & 0 \
frac{1}{3} & 0 & 1 & 0
end{array}
ight]
2 LatexParser
OCR识别后的值是一个latex格式的文本,因此我们需要对其进行语法解析
假设OCR识别出的内容是可信且没有问题的,我们需要做的是提取矩阵部分,将其保存到一个二维数组中
主要实现思路是使用正则表达式进行提取
# 对外暴露的接口
def latex_to_array(latex):
content = get_array_str(latex)
return matrix_to_array(content)
# 提取egin{array}到end{array}中间的部分
def get_array_str(latex):
# re_array =
pattern = re.compile(r'\begin{array}{.*}[wW]*\end{array}', re.DOTALL)
# pattern = re.compile(r'[.|
]*',re.DOTALL)
array = pattern.findall(latex)[0]
content = re.sub(r'(\begin{array}{.*}(
)*)|((
)*\end{array})', "", array)
# print(content)
return content
# 将latex中的数组部分转为二维数组
def matrix_to_array(content: str):
res = []
rows = content.split('\\
')
for row in rows:
res.append(row_to_array(row))
# print(res)
return res
# 将latex中的一行转为list
def row_to_array(row: str):
res = []
expr_array = row.split('&')
for expr in expr_array:
res.append(expr_to_num(expr))
return res
# 将latex中的一个表达式转为数字
def expr_to_num(expr: str):
expr = expr.strip()
if expr.isdigit():
return expr
else:
matchObj = re.match(r'\frac{(d+)}{(d+)}', expr)
fenzi = int(matchObj.group(1))
fenmu = int(matchObj.group(2))
return fenzi / fenmu
以本题为例,提取后的结果如下
[['0', 0.5, '0', 0.5],
[0.3333333333333333, '0', '0', 0.5],
[0.3333333333333333, 0.5, '0', '0'],
[0.3333333333333333, '0', '1', '0']]
3 PageRank
pagerank部分使用了迭代的方式进行计算,有两个可变参数迭代次数和阻尼系数,实现如下
初始pagerank值r=[1/N]N
计算公式为
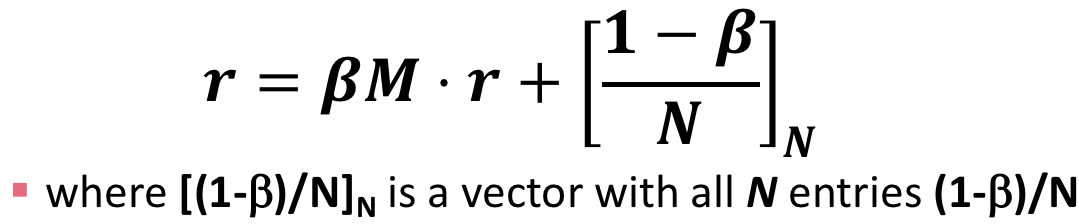
代码实现如下:
# array: 转移矩阵(二维数组)
# time:迭代次数
# d: 阻尼系数
def calculate(array, time=10, d=0.85):
length = len(array)
value = [1 / length] * length # page rank value list
for i in range(time):
new_value = [] # new page rank value list
for row_index in range(length):
row = array[row_index]
tmp = (1 - d) / length # tmp is new value item
for col_index in range(len(row)):
tmp += d * float(row[col_index]) * value[col_index]
new_value.append(tmp)
print('iter', i + 1, new_value)
value = new_value
技术选型
使用python进行实现
迭代结果
若不考虑阻尼系数,十次迭代的计算结果如下
init [0.25, 0.25, 0.25, 0.25]
iter 1 [0.25, 0.20833333333333331, 0.20833333333333331, 0.3333333333333333]
iter 2 [0.2708333333333333, 0.25, 0.1875, 0.29166666666666663]
iter 3 [0.2708333333333333, 0.23611111111111108, 0.21527777777777776, 0.2777777777777778]
iter 4 [0.2569444444444444, 0.22916666666666666, 0.20833333333333331, 0.3055555555555555]
iter 5 [0.2673611111111111, 0.2384259259259259, 0.20023148148148145, 0.29398148148148145]
iter 6 [0.26620370370370366, 0.2361111111111111, 0.20833333333333331, 0.2893518518518518]
iter 7 [0.26273148148148145, 0.23341049382716045, 0.2067901234567901, 0.29706790123456783]
iter 8 [0.2652391975308641, 0.23611111111111105, 0.20428240740740738, 0.29436728395061723]
iter 9 [0.2652391975308641, 0.23559670781893, 0.20646862139917688, 0.29269547325102874]
iter 10 [0.2641460905349794, 0.23476080246913572, 0.20621141975308638, 0.29488168724279823]
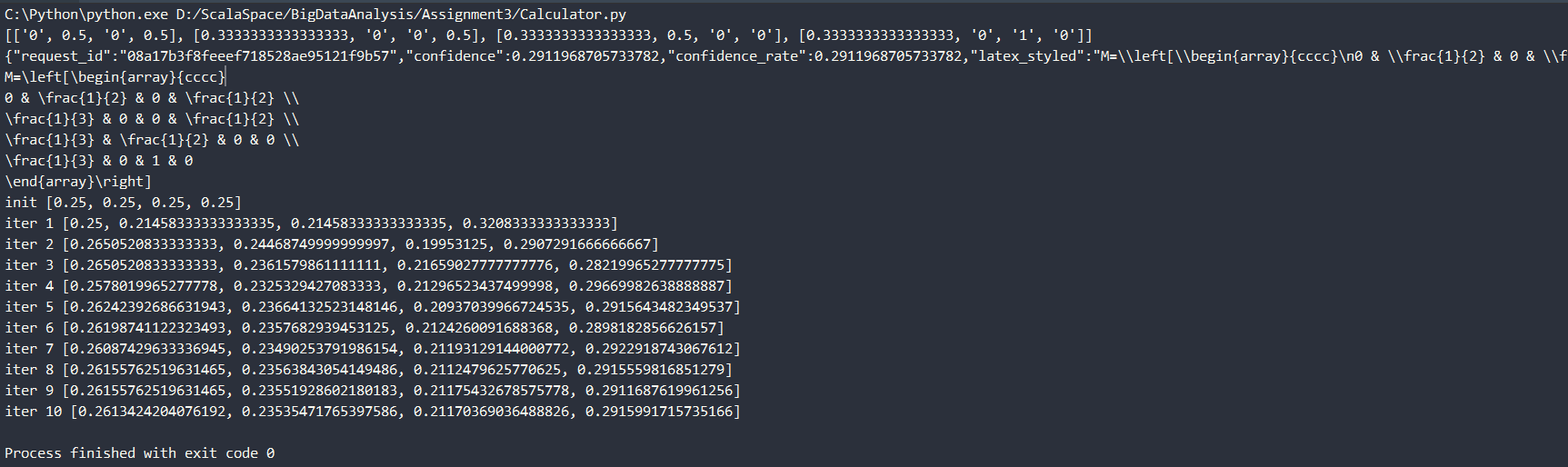
若考虑阻尼系数,假设d=0.85,十次迭代结果如下
init [0.25, 0.25, 0.25, 0.25]
iter 1 [0.25, 0.21458333333333335, 0.21458333333333335, 0.3208333333333333]
iter 2 [0.2650520833333333, 0.24468749999999997, 0.19953125, 0.2907291666666667]
iter 3 [0.2650520833333333, 0.2361579861111111, 0.21659027777777776, 0.28219965277777775]
iter 4 [0.2578019965277778, 0.2325329427083333, 0.21296523437499998, 0.29669982638888887]
iter 5 [0.26242392686631943, 0.23664132523148146, 0.20937039966724535, 0.2915643482349537]
iter 6 [0.26198741122323493, 0.2357682939453125, 0.2124260091688368, 0.2898182856626157]
iter 7 [0.26087429633336945, 0.23490253791986154, 0.21193129144000772, 0.2922918743067612]
iter 8 [0.26155762519631465, 0.23563843054149486, 0.2112479625770625, 0.2915559816851279]
iter 9 [0.26155762519631465, 0.23551928602180183, 0.21175432678575778, 0.2911687619961256]
iter 10 [0.2613424204076192, 0.23535471765397586, 0.21170369036488826, 0.2915991715735166]
附:运行截图
拓展
考虑:如果是1万张图片呢?
# 传入文件路径列表
def page_rank(paths):
for img_path in paths:
latex = get_latex_from_file('test.png')
arr = latex_to_array(latex)
# calculate(arr, 10, 1) # 不考虑阻尼系数
calculate(arr, 10) # 考虑阻尼系数
只需要传入图片文件路径列表即可