一:阻塞IO模型
阻塞 I/O 是最简单的 I/O 模型,一般表现为进程或线程等待某个条件,如果条件不满足,则一直等下去。条件满足,则进行下一步操作。

应用进程通过系统调用 recvfrom 接收数据,但由于内核还未准备好数据报,应用进程就会阻塞住,直到内核准备好数据报,recvfrom 完成数据报复制工作,应用进程才能结束阻塞状态。
二.非阻塞IO模型
应用进程与内核交互,目的未达到之前,不再一味的等着,而是直接返回。然后通过轮询的方式,不停的去问内核数据准备有没有准备好。如果某一次轮询发现数据已经准备好了,那就把数据拷贝到用户空间中。
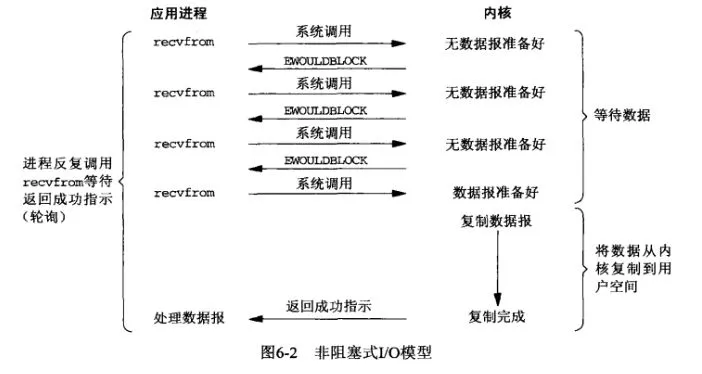
应用进程通过 recvfrom 调用不停的去和内核交互,直到内核准备好数据。如果没有准备好,内核会返回error,应用进程在得到error后,过一段时间再发送recvfrom请求。在两次发送请求的时间段,进程可以先做别的事情。
三.信号驱动IO模型
应用进程在读取文件时通知内核,如果某个 socket 的某个事件发生时,请向我发一个信号。在收到信号后,信号对应的处理函数会进行后续处理。

应用进程预先向内核注册一个信号处理函数,然后用户进程返回,并且不阻塞,当内核数据准备就绪时会发送一个信号给进程,用户进程便在信号处理函数中开始把数据拷贝的用户空间中。
四.IO复用模型
多个进程的IO可以注册到同一个管道上,这个管道会统一和内核进行交互。当管道中的某一个请求需要的数据准备好之后,进程再把对应的数据拷贝到用户空间中。(就是只用这个管道进程去轮询了,不用像非阻塞模型,每个进程线程都去轮询)
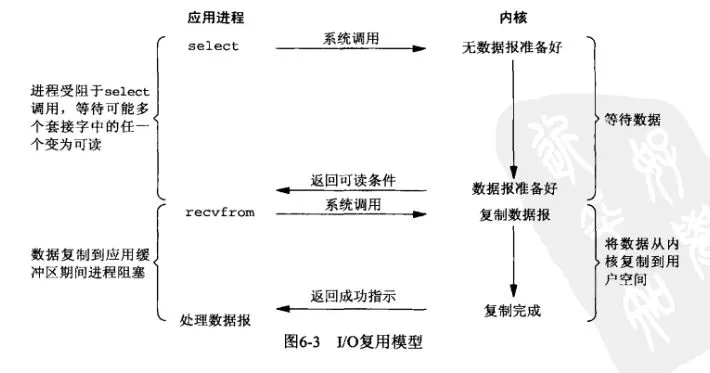
IO多路转接是多了一个select函数,多个进程的IO可以注册到同一个select上,当用户进程调用该select,select会监听所有注册好的IO,如果所有被监听的IO需要的数据都没有准备好时,select调用进程会阻塞。当任意一个IO所需的数据准备好之后,select调用就会返回,然后进程在通过recvfrom来进行数据拷贝。
以上四种都是同步的,因为真正的数据拷贝过程都还是由用户进程来完成的,都是同步进行的。
五.异步IO模型
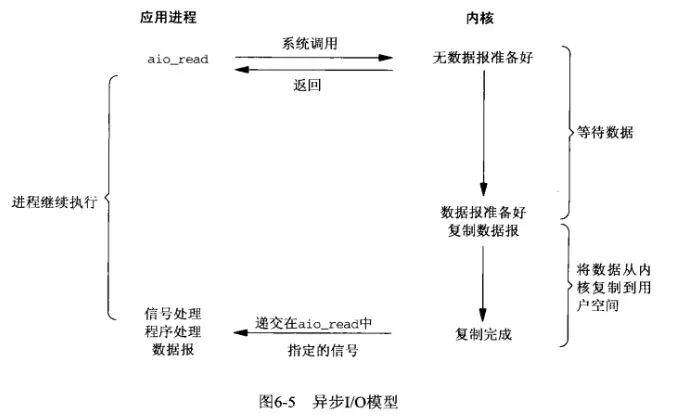
异步IO模型。应用进程把IO请求传给内核后,完全由内核去操作文件拷贝。内核完成相关操作后,会发信号告诉应用进程本次IO已经完成。(就是将数据从内核缓冲区拷贝到进程缓存区也是由内核完成,不是由用户进程来完成)
关于上面的多路复用IO模型有select,poll,epoll,kqueue(unix)这几种
从前往后是在不断进步的
select:
select主要缺陷是,对单个进程打开的文件描述是有一定限制的,它由FD_SETSIZE设置,默认值是1024,虽然可以通过编译内核改变,但相对麻烦,另外在检查数组中是否有文件描述需要读写时,采用的是线性扫描的方法,即不管这些socket是不是活跃的,我都轮询一遍(线性轮询),所以效率比较低。
select具体操作:
- 1.:select创建3个文件描述符集,并将这些文件描述符拷贝到内核中,这里限制了文件句柄的最大的数量为1024(注意是全部传入---第一次拷贝);
- 2.:内核针对读缓冲区和写缓冲区来判断是否可读可写,这个动作和select无关;
- 3.:内核在检测到文件句柄可读/可写时就产生中断通知监控者select,select被内核触发之后,就返回可读可写的文件句柄的总数;
- 4.:select会将之前传递给内核的文件句柄再次从内核传到用户态(第2次拷贝),select返回给用户态的只是可读可写的文件句柄总数,再使用FD_ISSET宏函数来检测哪些文件I/O可读可写(遍历);
- 5.:select对于事件的监控是建立在内核的修改之上的,也就是说经过一次监控之后,内核会修改位,因此再次监控时需要再次从用户态向内核态进行拷贝(第N次拷贝)
poll:
poll本质和select没有区别,但其采用链表存储,解决了select最大连接数存在限制的问题,但其也是采用遍历的方式来判断是否有设备就绪,所以效率比较低,另外一个问题是大量的fd数组在用户空间和内核空间之间来回复制传递,也浪费了不少性能。
epoll&kqueue:
epoll和kqueue是更先进的IO复用模型,其也没有最大连接数的限制(1G内存,可以打开约10万左右的连接),并且仅仅使用一个文件描述符,就可以管理多个文件描述符,并且将用户关系的文件描述符的事件存放到内核的一个事件表中(底层采用的是mmap的方式红黑树),这样在用户空间和内核空间的copy只需一次。另外这种模型里面,采用了类似事件驱动的回调机制或者叫通知机制,在注册fd时加入特定的状态,一旦fd就绪就会主动通知内核。这样以来就避免了前面说的无脑遍历socket的方法,这种模式下仅仅是活跃的socket连接才会主动通知内核,所以直接将时间复杂度降为O(1)。
一个fd被添加到epoll中之后(EPOLL_ADD),内核会为它生成一个对应的epitem结构对象.epitem被添加到eventpoll的红黑树中.红黑树的作用是使用者调用EPOLL_MOD的时候可以快速找到fd对应的epitem。
epoll具体操作:
- 1.:首先执行epoll_create在内核专属于epoll的高速cache区,并在该缓冲区建立红黑树和就绪链表,用户态传入的文件句柄将被放到红黑树中(第一次拷贝)。
- 2.:内核针对读缓冲区和写缓冲区来判断是否可读可写,这个动作与epoll无关;
- 3.:epoll_ctl执行add动作时除了将文件句柄放到红黑树上之外,还向内核注册了该文件句柄的回调函数,内核在检测到某句柄可读可写时则调用该回调函数,回调函数将文件句柄放到就绪链表。
- 4.:epoll_wait只监控就绪链表就可以,如果就绪链表有文件句柄,则表示该文件句柄可读可写,并返回到用户态(少量的拷贝);
- 5.:由于内核不修改文件句柄的位,因此只需要在第一次传入就可以重复监控,直到使用epoll_ctl删除,否则不需要重新传入,因此无多次拷贝。
- 6.:epoll是继承了select/poll的I/O复用的思想,并在二者的基础上从监控IO流、查找I/O事件等角度来提高效率,具体地说就是内核句柄列表、红黑树、就绪list链表来实现的。