优化资源分配
- 在Spark的集群管理器(Yarn、Mesos和Spark单机)之间,这里的建议和配置略有不同,但是我们只关注Yarn,Cloudera向所有用户推荐Yarn。
- Spark(和YARN) 考虑的两个主要资源是CPU和内存。当然,磁盘和网络I/O也对Spark性能有影响,但是Spark和YARN目前都没有对它们进行积极的管理。
- 当从命令行调用spark-submit、spark-shell和pyspark时,或者通过设置spark.executor,可以使用 --executor指定内核的数量。类似地,堆大小可以使用--executormemory标记或spark.executor.memory。
- 内核属性 - 控制excecuter可以运行的并发task的数量。 “--executor-core 5” 意味着每个executor最多可以同时运行五个任务。
- 内存属性 - 会影响Spark可以缓存的数据量,以及用于分组、聚合和连接的shuffle数据结构的最大大小。
需要考虑的因素
1.考虑Spark所请求的资源如何与现有Yarn相匹配。
Yarn性能如下:
- yarn.nodemanager.resource.memory-mb 控制每个节点上容器使用的内存的最大和.
- yarn.nodemanager.resource.cpu-vcores 控制每个节点上容器使用的内核的最大和。
下面显示了Spark和YARN中内存属性的层次结构:
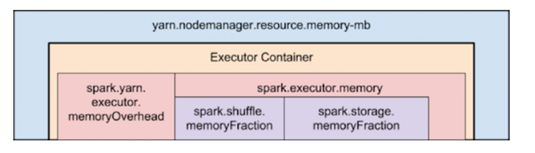
在确定Spark执行者的规模时,还有一些最后要考虑的问题:
- 应用程序Dirver容器是一个非执行容器,具有从Yarn请求容器的特殊能力,它占用资源。
- 在yarn-client模式中,它默认为一个1024MB和一个vcore。
- 在yarn-cluster模式中,应用程序主程序运行驱动程序,占用驱动程序资源。
运行拥有太多内存的执行器通常会导致过多的垃圾收集延迟。64GB是对单个执行程序的一个良好上限的粗略估计。
例子:
假设一个集群有6个节点,每个节点都配备了16个内核和64GB内存。

解析:
- 避免将100%的资源分配给Yarn容器,每个节点需要一些资源来运行OS和Hadoop守护进程。在本例中,我们为这些系统进程保留了一个GB 内存和一个内核。
- Yarn 的AM(Application Manager)需要一个executer
- 每个执行器15个内核会导致糟糕的HDFS I/O吞吐量(只能使用少于5个)。
- 每个core 可用的 executer = 6×15/5 -1 =17
- 每个node上有3个executor 18/6 可用:(63/3)×(1-0.07) = 19.xx.
所以更好的选择是:--num-executors 17 --executor-cores 5 --executor-memory 19G.
2. 优化的并行性
- Spark是一个并行处理引擎,您可能已经了解到这一点。
- Spark不是一个完美的并行处理引擎,它计算出最佳并行度的能力有限。
- 每个Spark阶段都有一些任务,每个任务都按顺序处理数据。在优化Spark作业时,这个数字可能是决定性能的最重要的参数。
为什么分区并行很关键?
-
- 主要的问题是taks的数量太少。如果可用的task比vcore少,那么阶段就不会利用所有可用的CPU。
- 少量的任务也意味着对每个任务中发生的任何聚合操作施加更多的内存压力。任何join、cogroup或*ByKey操作都涉及在hashmap或内存缓冲区中保存对象以进行分组或排序。当用于这些聚合操作的记录不容易放入内存时,可能会出现一些混乱。首先,在这些数据结构中保存许多记录会对垃圾收集造成压力,这可能会导致行暂停。其次,当记录不适合内存时,Spark会将它们溢出到磁盘,这将导致磁盘I/O和排序。在大型洗牌期间的这种开销可能是我在Cloudera客户中看到的导致工作停滞的首要原因。
那么如何增加分区的数量呢?
- 如果所讨论的阶段是从Hadoop读取数据,您的选择是:
-
- 使用重新分区转换,这将触发洗牌。
- 配置InputFormat以创建更多的分割。
- 将输入数据写入具有较小块大小的HDFS。
2. 如果阶段从另一个阶段获得输入,则触发阶段边界的转换将接受numPartitions参数,例如

X应该是什么? 优化分区数量最直接的方法是进行实验:查看父RDD中的分区数量,然后将其乘以1.5,直到性能停止改善。
3. 精简数据结构
- Spark 中记录有两种表示: 反序列化的Java对象表示和序列化的二进制表示。
- 通常,Spark对内存中的记录使用反序列化表示,对存储在磁盘上或通过网络传输的记录使用序列化表示。
序列化器属性(org.apache.spark.serializer) - 用于在这两个表示之间进行转换的序列化器。Kryo序列化器, KryoSerializer是首选的选项。不幸的是,这不是默认值,因为在Spark的早期版本中Kryo中存在一些不稳定性,而且不希望破坏兼容性,但是应该始终使用Kryo序列化器。在这两种表示中记录的占用空间对Spark性能有很大的影响。值得检查传递的数据类型,并寻找可以减少冗余的地方。
- 膨胀的反序列化对象将导致Spark更频繁地将数据溢出到磁盘,并减少Spark可以缓存的反序列化记录的数量(例如,在内存存储级别)。
- 膨胀的序列化对象将导致更大的磁盘和网络I/O,并减少Spark可以缓存的序列化记录的数量(例如,在MEMORY_SER存储级别)。
4. 数据格式
当在磁盘上存储数据时,请使用可扩展的二进制格式,如Avro、Parquet、Thrift或Protobuf。