需要的库:
requests
urllib.parse下的urlencode
csv
time
通过查看NetWork中的Ajax请求的xhr文件发现这条Ajax请求包含的信息如下:

可以看到,包含了前20条电影的所有信息
当再次向下滑动时,会出现新的xhr文件:
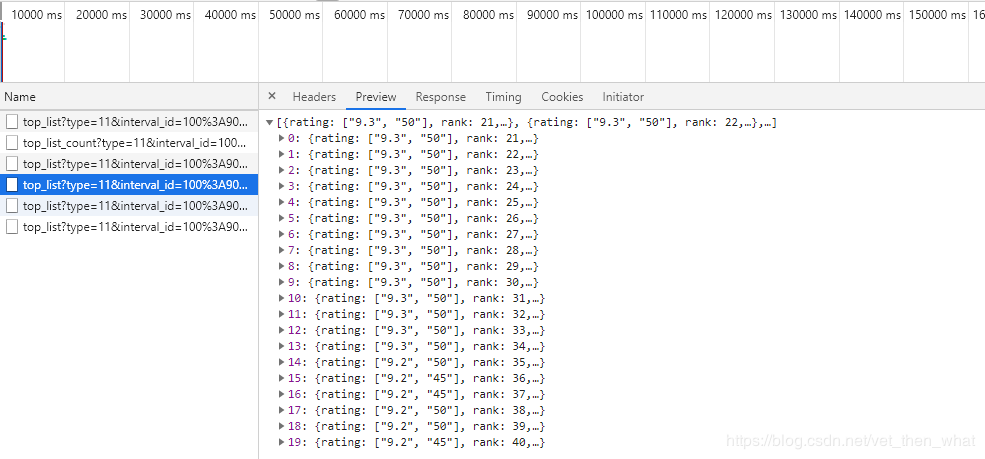
每个新的xhr文件内包含了20条电影的相关信息
对比每个xhr的请求url
第一个:Request URL: https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20
第二个:Request URL: https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=20&limit=20
第三个:Request URL: https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=40&limit=20
可以分析出每次滚动Ajax请求的url不同在于查询字符串中的start参数不同,以20的倍数递增
通过这样就可以实现爬取xhr文件获取电影信息:
源码如下:
import requests from urllib.parse import urlencode import json import csv import time headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0', } def get_page(start): params={ 'action':'', 'start':start, 'limit':'20' } url='https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&'+urlencode(params) print(url) try: res=requests.get(url,headers=headers) #爬取豆瓣需要加一个包含User-Agent字段的请求头 if res.status_code==200: return res.json() except requests.ConnectionError: return None #这里获取的res.json()是一个大的列表,里面存储的是一个个的字典 def get_one_film(json0): for item in json0: data=[] d={} #排名 rank=item['rank'] #标题 title=item['title'] #评分 score=item['rating'][0] #类型 types=item['types'] #主演 actor=item['actors'] d['rank']=rank d['title']=title d['score']=score d['types']=types d['actor']=actor #print(d,' ') data.append(d) print(rank) #存储为json格式 with open('豆瓣剧情片排行.json','a',encoding="utf-8") as f: f.write(json.dumps(data,indent=1,ensure_ascii=False)) #存储为CSV格式 with open('豆瓣剧情排行榜.csv','a',encoding="utf-8") as f: fieldnames=['rank','title','score','types','actor'] writer=csv.DictWriter(f,fieldnames=fieldnames) writer.writeheader() writer.writerow(d) def main(): for i in range(20): start=str(i*20) json0=get_page(start) get_one_film(json0) time.sleep(0.8) main()