项目代码是python写的,之前的很不好用,开发、维护性都不行,经过我独立进行重构,效率得到了很大的提高
一、基础
1、函数式编程
函数是一等公民,可以像普通变量一样,作为参数传入,作为返回值传出

运行结果:
((1, 2, 3), {'a': 1})
begin
((1, 2, 3), {'a': 1})
end
2、包装函数
类似于Spring AOP面向切面,使用注解的形式增强函数。本质仍是函数式编程,只是运用了python的一个语法糖
作用:可在原有代码基础上简单加上注解形式的包装函数,附加新的功能

运行结果:
in simple_foo()
in simple_foo()
used: 3.657145977907425e-06
二、代码重构之剥离业务无关代码
1、重构前
如图所示,第一部分是初始化参数,第二部分是业务sql,第三部分是数据库操作
业务无关代码:40行
业务代码:1行
业务代码占比 2.5%
问题分析:
- 业务代码占比过低,对于业务开发人员来说,代码难懂,且难改
- 初始化参数部分,这块不是固定的,按天、小时、小时间隔、分钟、分钟间隔等频率触发的任务的参数都不一样,如果全靠业务开发人员独立实现,会影响开发效率(即使通过复制粘贴,每次还要检查一下是否复制正确),且无法保证正确性

2、重构后
业务无关代码:1行 (@oss_func)
业务代码:2行
业务代码占比 66%
将初始化参数、数据库操作部分全放到oss_func包装函数里,指定触发频率时配置freq、tot参数即可,目前支持的参数值有:
1天 (freq:1d)
1小时 (freq:1h)
5分钟间隔 (freq:5m)
5分钟累积 (freq:5m, tot:True)

三、代码重构之剥离维度聚合公有逻辑
1、重构前
这是一个按渠道维度统计的例子,对应两个sql
逻辑相同、聚合维度不同的sql
代码重复度几乎达到100%
问题分析:
若有n个维度,则会有2^n个sql,每增加一个维度,复杂度都是指数级的。开发、维护都将变得异常艰难。
在实际开发过程中,经常会出现新增维度统计的场景。如2017年底野蛮人全球服上线前夕要求新增按国家统计,光影对决要求新增按操作系统统计等

2、重构后
(1)剥离出来的维度聚合公有逻辑,在group by处使用{group},在select处使用“{维度名} 列名”
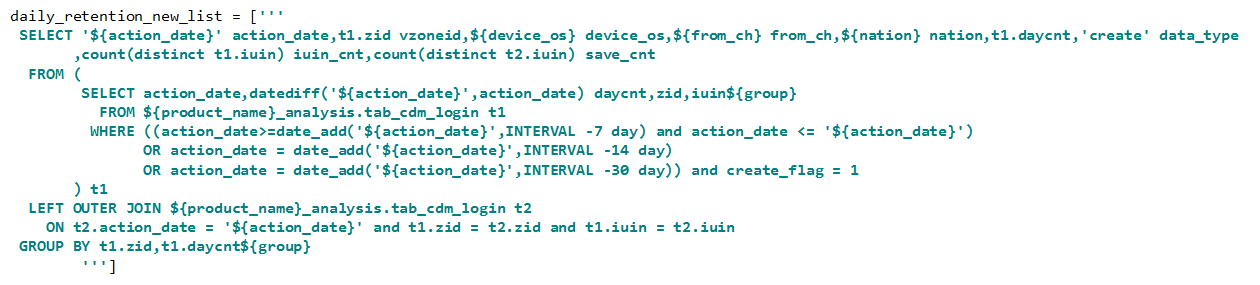
(2)只要简单调用replace_dim函数,配置要按哪些维度聚合即可


附relpace_dim函数实现:
