推荐:亲身体验,数次踩坑,遂撰写此文,以备各位不时之需。
背景
一天,产品经理递给我了一份word报告,我定睛一看

这个文档有大大小小的标题层级,还有排版好的段落、各种一目了然的饼图、走势图,当然还少不了颜色循环交替的报表。精致程度不亚于小明同学的学习报告。
准备
鲁迅:身为一名Java程序员,任何时候都不要忘记站在巨人的肩膀上。

通过某歌搜索关键词:java+word+导出,我立马得出了很多成熟的方案,通过横向、纵向比较,再结合本次报告样式比较多、用户可灵活选择不同模块导出的特点,最终,我决定使用Freemarker 动态替换模版数据来导出word文档。至于导出文档的最终格式,有两种选择:
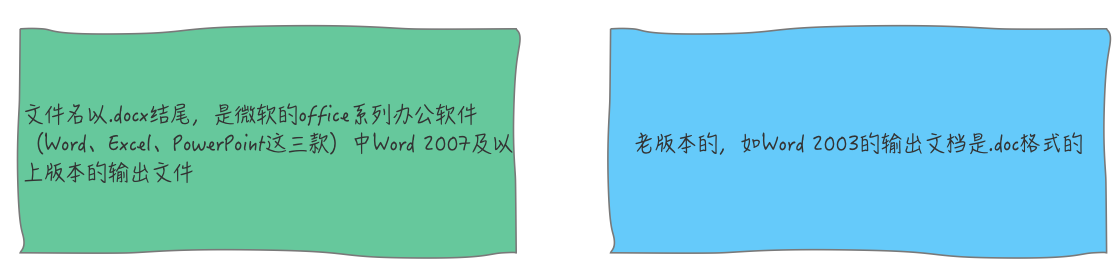
那到底使用doc还是docx格式的文档?
每当人生当中每次面临选择我都很慎重。最终我选择使用docx格式(原因文末会讲),但是为了让大家有更多的选择,满足更多的业务场景,借此机会,小明会给大家分别介绍使用freemarker导出两种格式的word文档方式。
思路
FreeMarker是一个基于Java的模板引擎,最初专注于使用MVC软件架构生成动态网页。但是,它是一个通用的模板引擎,不依赖于servlets或HTTP或HTML,因此它通常还用于生成源代码,配置文件或电子邮件。
此时,我们用它动态生成xml文件,进而导出word文档。

整体流程如下:

准备
- WPS
由金山软件股份有限公司发布,用于办公软件最常用的文字编辑、表格、演示稿等功能。
对,就是这个国产的办公软件。我也是第一次发现在导出文档这件事上,它如多年好友般友好。(word解析后的xml文件阅读性很强,一般人我不告诉他)
- 开发工具(IDEA、Visual Studio Code等)
你喜欢的,顺手的,就是最好的。
实现
集成Freemarker模版引擎
本次项目使用的框架依旧是Springboot,这个框架在集成各个组件表现都很便捷,不再赘述,这次集成Freemarker也不例外。
- 首先我们在项目中增添依赖
spring-boot-starter-freemarker
pom.xml文件如下所示:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
- 按照默认约定,我们可以在resources下创建一个templates文件夹(查看FreeMarkerProperties源码可以发现默认目录就是这个),用于存放模版文档。
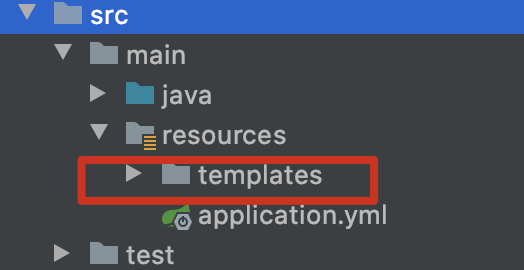
- application.yml增加配置
spring:
freemarker:
template-loader-path: classpath:/templates
cache: false # 开发环境缓存关闭
suffix: xml
charset: UTF-8
生成doc格式的文档
这里先拿使用freemarker导出doc格式的word文档举例。
- 首先将docxTemplate.docx(调整好样式的模版文档)另存为WORD 2003 XML文档(*.xml)
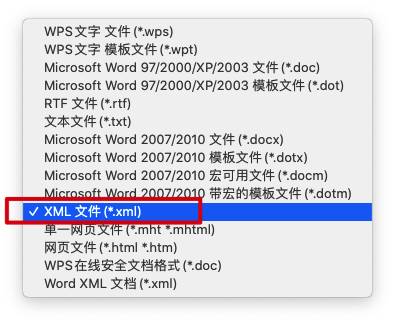
此处命名为docTemplete.xml,使用编辑工具首次打开时,会发现这个文档里面是压缩的xml,因此我们首先需要格式化一下。
注意:如果你使用的是Visual Studio Code开发工具,一定要检查你所使用的xml格式化插件,是否会优化你的xml标签 。比如:
<w:rPr>会变成<rPr>。使用Visual Studio Code的同学,oh my god ! 小明在这里推荐大家使用这个插件:XML Language Support by Red Hat
- 现在,我们就使用freemarker语法编辑docTemplete.xml,比如使用占位符
${}替换当前文档中的文本,以达到动态生成文本的目的,直接上代码。
public static Configuration getConfiguration(){
//创建配置实例
Configuration configuration = new Configuration(Configuration.VERSION_2_3_28);
//设置编码
configuration.setDefaultEncoding("utf-8");
configuration.setClassForTemplateLoading(WordUtil.class, "/templates");
return configuration;
}
/**
* 生成doc文件
*
* @param ftlFileName 模板ftl文件的名称
* @param params 动态传入的数据参数
* @param outFilePath 生成的最终doc文件的保存完整路径
*/
public void ftlToDoc(String ftlFileName, Map params, String outFilePath) {
try {
/** 加载模板文件 **/
Template template = configuration.getTemplate(ftlFileName);
/** 指定输出word文件的路径 **/
File docFile = new File(outFilePath);
FileOutputStream fos = new FileOutputStream(docFile);
Writer bufferedWriter = new BufferedWriter(new OutputStreamWriter(fos, "utf-8"), 10240);
template.process(params, bufferedWriter);
if (bufferedWriter != null) {
bufferedWriter.close();
}
} catch (TemplateException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
生成docx格式的文档
高能预警! 在成功使用Freemarker动态导出doc格式的文档之后,相信大家和我的心情一样非常激动。但以上操作只是一个小铺垫,接下来我们来看看如何实现docx格式的文档导出,小明相信一定会让各位看官大跌眼镜!不,大开眼界!
首先,告诉大家一个秘密:docx格式的文档其实是一个ZIP格式的压缩文件哦! 什么?你不信?验证如下:
- windows的小伙伴
将docx文档修改为ZIP格式(修改.docx后缀名为.zip),然后通过解压工具解压。 - MacOS的小伙伴
直接使用unzip命令解压word文档,解压过后我们会发现该文档其实还有自己的目录结构!

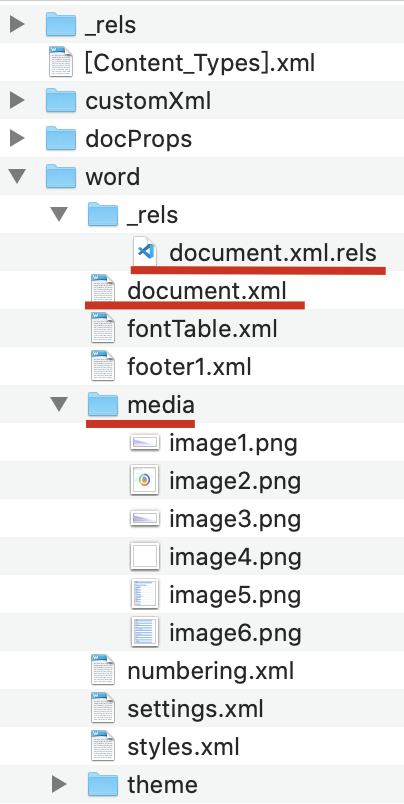
当然,这么多文件我们不必一一知悉,只需关注小明红线标注的文件和目录即可: - document.xml文件用于存放核心数据,文字,表格,图片引用等
- media目录用于存放所有文档的图片
- _rels目录下的document.xml.rels里存放的是配置信息,比如图片引用关系,即在document.xml中引用id对应media中的哪个图片。
- 获取zip里的document.xml文档以及_rels文件夹下的document.xml.rels文档
- 显而易见,如果我们要想根据数据动态导出不同的word文档,只需要:通过freemarker将本次数据填充到document.xml中,并将图片配置信息填充至document.xml.rels文档里,再用文件流把本次图片写入到media目录下替换已经存在的图片,最后把填充过内容的document.xml、document.xml.rels以及media用流的方式写入zip即可输出docx文档!上代码。
好吧,限于篇幅,代码见文末 Github地址
问题及解决方案
当然,大家在第一次尝试去干某一件事时,都不一定是一蹴而就的。就比如在导出word时,就可能会遇到以下问题。
特殊字符
问题:有些文本数据中难免含有特殊字符,如:< > @ ! $ & 等等。
解决方案:这些特殊字符如果不进行转义,就会引起word打不开的现象,比如表格中的超链接的&符号,就需要替换为&,如果你的文档用office打开时提示文件损坏,九成是因为特殊符号引起的,我们可以打开documet.xml定位报错位置;当然还有终极方案,我们可以利用Freemarker的语法直接在模板中使用<![CDATA[ ]]> 处理。比如:
<w:t><![CDATA[ ${article.title} ]]></w:t>
图片变形
问题:因为echarts生成的图表是响应式的,不同的屏幕大小、分辨率,会造成每次前端传过来的图片宽高比例不一致,如果还直接将图片按照之前的比例放进文档,会造成生成后文档中的图片变形。
思路:首先将文档中的图片设置为原图,然后锁定宽高比,将图片调整到合适大小,解压文档从document.xml,得到此时word中该图片宽高对应的值,如下所示:

要想保证不同像素比例的宽高在文档中不变形,我们需要固定cy的值,然后根据固定比例动态求得当前像素比例图片在word中代表的宽cx的值。计算方法如下所示:
公式:
a/b = x/y
其中,a表示图片在word中宽的数值,b代表图片在word中高的数值,x表示前端传过来图片的宽(单位:像素),y表示前端传过来图片的高(单位:像素)。因此,已知b、x、y,根据公式,我们即可求出a;
我就是文末
当然,还有用一些其他注意事项:
- 如果word中的模块比较多的话,使用Freemarker语法要仔细一点;
- 为什么小明最终选择导出docx格式的文档呢?(还不是因为产品经理的需求嘛)因为doc格式的文档,小明尝试导出后,发现该文档并不是一个合法的doc文档,体现在:不能在手机上(微信、钉钉)正常预览,office提示以xml形式打开等。因此在导出doc文档时,通过Freemaker填充document.xml后得到的并不是一个合法的word文档,查了相关资料,还需要借助第三方工具进行签名,而签名还需要在windows系统下才能完成,但是我们平时用的生产环境都是Linux……因此,考虑再三,再三权衡,最终选择导出docx格式的文档。这种方式再适合不过,而且还能保证在当前主流APP上都能正常预览。
- 敲黑板!导出docx文档最重要的一个思想是将本次数据写入覆盖模版文件(在商业中,相当于借壳上市),重新输出一个zip格式压缩的文件,这个文件就是我们最终想要的文档。
以上,就是小明word导出的前前后后,如果你也曾经遇到过或者现在正好遇到word文档导出开发的问题,欢迎一起讨论交流。
相关链接
我上传了工具类,包含doc、docx 的导出,以及导出word文档时特殊符号转义,还有图片Base64转换成文件输出的方法。
GitHub地址:https://github.com/WhenCoding/coder-xiaoming/blob/master/src/main/java/com/xm/coder/util/WordUtil.java
本文可转载,但需声明原文出处。 程序员小明,一个很少加班的程序员。欢迎关注微信公众号,获取更多优质文章。