xml的解析方式:dom解析和sax解析
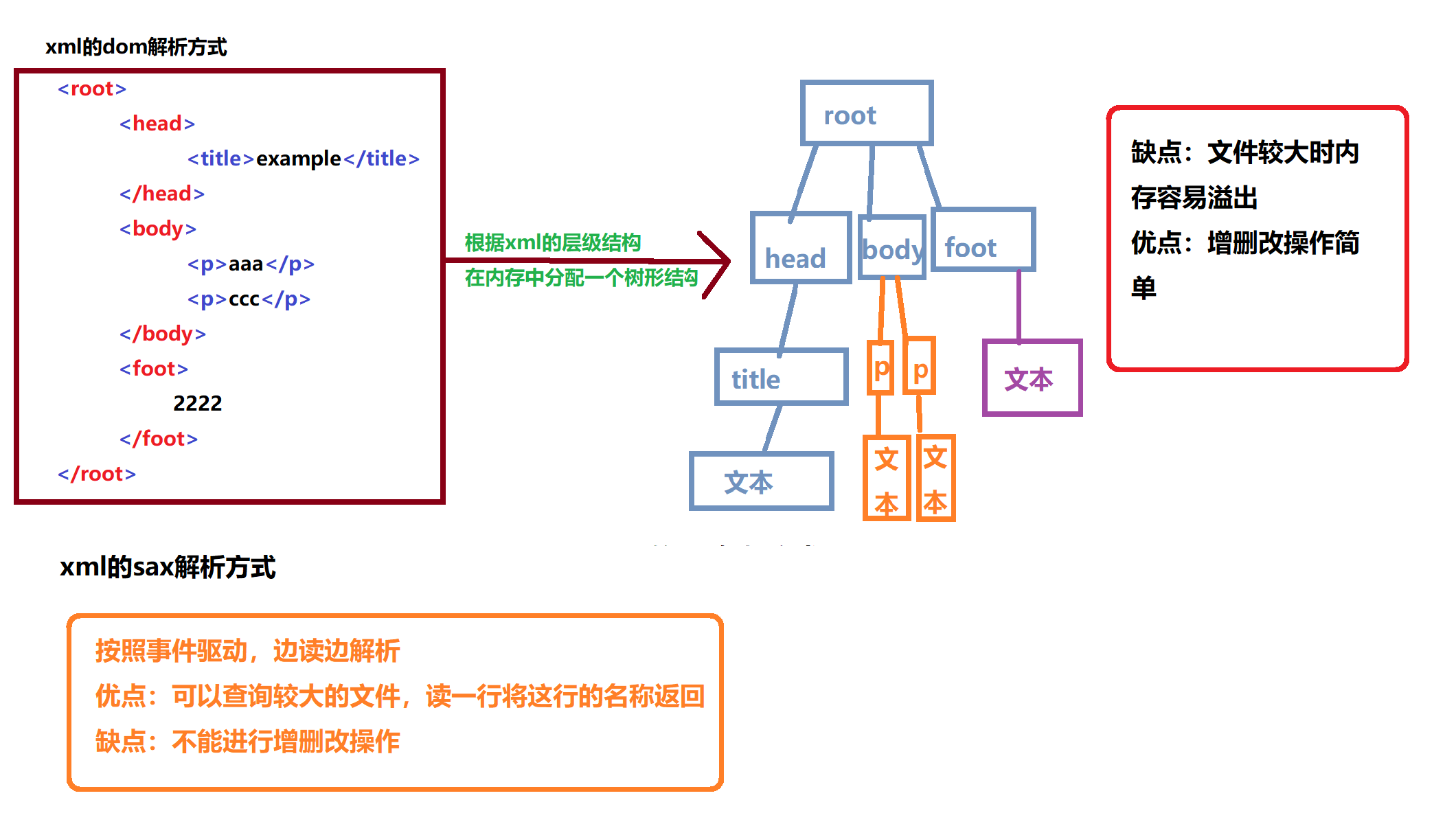
DOM解析
使用jaxp进行增删改查
1.创建DocumentBuilderFactory工厂
2.通过DocumentBuilderFactory工厂创建DocumentBuilder
3.解析xml,得到Document对象
*在对document进行增删改查操作时,需要回写到xml中:
1.创建TransformerFactory回写工厂
2.通过回写工厂,获得Transformer
3.Transformer.transform(new DOMSource(document),new StreamResult(""))
查
1 private static void selectALL() throws Exception {
2 /**
3 *
4 * 1.创建DocumentFacTory工厂
5 * 2.通过Document Factory工厂得到DocumentBuilder
6 * 3.解析xml得到Document对象
7 */
8
9 //创建工厂
10 DocumentBuilderFactory documentBuilderFactory=DocumentBuilderFactory.newInstance();
11 //创建BUilder
12 DocumentBuilder documentBuilder=documentBuilderFactory.newDocumentBuilder();
13 //解析xml 获得document对象
14 Document document=documentBuilder.parse("src/com//zyf/test.xml");
15
16 //获得所有name元素
17 NodeList list=document.getElementsByTagName("sex");
18 //遍历
19 for(int i=0;i<list.getLength();i++){
20 Node node1=list.item(i);
21 System.out.println(node1.getTextContent());
22 }
23 }
增
public static void addSex() throws Exception{
//创建工厂
DocumentBuilderFactory documentBuilderFactory=DocumentBuilderFactory.newInstance();
//获得builder
DocumentBuilder documentBuilder=documentBuilderFactory.newDocumentBuilder();
//获得deocument
Document document=documentBuilder.parse("src/com/zyf/test.xml");
//创建节点<sex>nv</sex>
Node sex=document.createElement("sex");
//在sex中创建文本
Node text=document.createTextNode("nv");
// sex.setTextContent("nv");
sex.appendChild(text);
//得到sex的父节点<p1>
NodeList list=document.getElementsByTagName("p1");
Node node1=list.item(0);
//添加进父节点p1
node1.appendChild(sex);
//回写
TransformerFactory transformerFactory=TransformerFactory.newInstance();
Transformer transformer=transformerFactory.newTransformer();
transformer.transform(new DOMSource(document),new StreamResult("src/com/zyf/test.xml"));
}
删
public static void removeSex()throws Exception{
//创建工厂
DocumentBuilderFactory documentBuilderFactory=DocumentBuilderFactory.newInstance();
//闯将builder
DocumentBuilder documentBuilder=documentBuilderFactory.newDocumentBuilder();
//获得document
Document document=documentBuilder.parse("src/com/zyf/test.xml");
//获得sex的父节点
//获得sex
NodeList list=document.getElementsByTagName("sex");
Node node1=list.item(0);
//获得sex的父节点
Node parent=node1.getParentNode();
//remove
parent.removeChild(node1);
//回写
//回写工厂
TransformerFactory transformerFactory=TransformerFactory.newInstance();
Transformer transformer=transformerFactory.newTransformer();
transformer.transform(new DOMSource(document), new StreamResult("src/com/zyf/test.xml"));
}[Document是Node的子类]
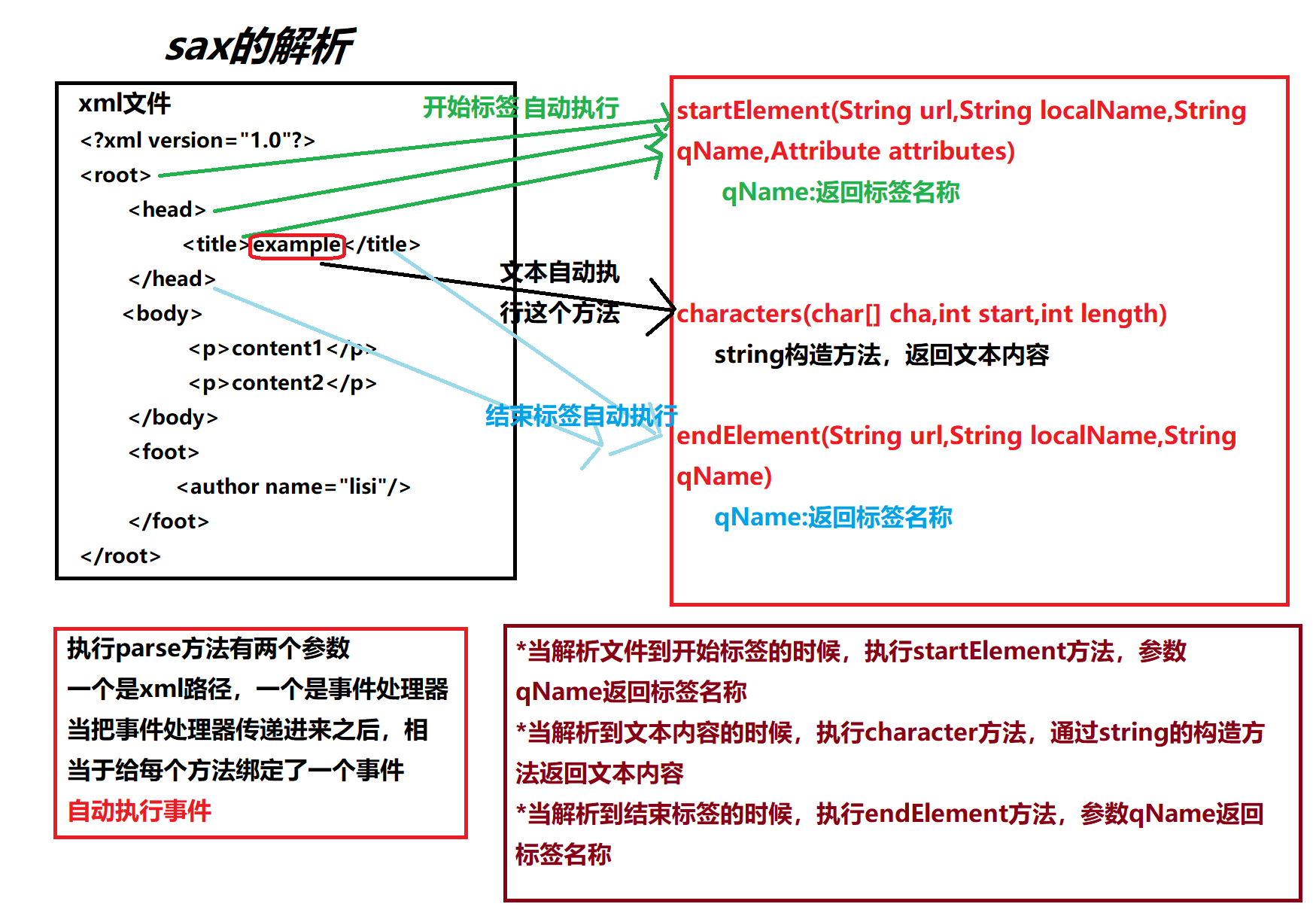
xml的sax解析方式