Kaka日志的结构概览可见之前的博客。
日志段代码解析
日志段是kafka保存消息的最小载体,阅读日志段代码可更好的去定位分析问题,鉴于网上对日志段的说明文档较少,本文对Kafka日志段进行详细说明,重点介绍Kafka日志段LogSegment的声明、append、read、recover方法。
日志段代码位置
日志段代码在Kafka的core工程目录下,详细位置:core/scala/kafka/log/LogSegment.scala,日志相关的代码都在core/scala/kafka/log目录下。
LogSegment.scala文件包含LogSegment class、LogSegment object、LogFlushStats object.
说明:scala语法中,允许scala中包含同名的class 和object,这种用法称之为伴生(Companion),class 对象称之为伴生类,和java语法中的类是一样的。而 object是一个单例对象
里面包含静态方法和变量,用java比喻时,object相当于java的utils工具类
日志段LogSegment 注释说明
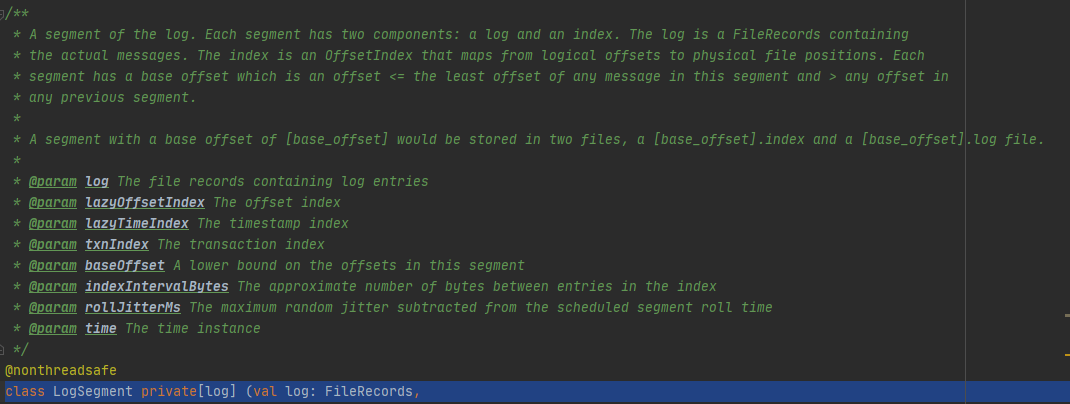
具体翻译为:日志段。每个日志段包含两个部分,分别是日志和索引。日志是一个文件记录,包含真实的消息。索引是一个偏移量,是物理位置到逻辑的映射。每一个段有一个基础的偏移。<=段中所有的消息>之前的段。段包含两个偏移文件,分别是索引和文件。
日志段声明分析
class LogSegment private[log] (val log: FileRecords,
val lazyOffsetIndex: LazyIndex[OffsetIndex],
val lazyTimeIndex: LazyIndex[TimeIndex],
val txnIndex: TransactionIndex,
val baseOffset: Long,
val indexIntervalBytes: Int,
val rollJitterMs: Long,
val time: Time) extends Logging {...}
字段解析和说明
从日志段的声明中我们发现,需要日志文件、三个索引文件(位移索引、时间戳索引、已终止的事务索引)等,我们同时也发现其中两个索引是延迟索引。
baseoffset:每个日志段都保留了自身的起始位移。
indexIntervalBytes:即为Broker段参数,log.index.interval.bytes,控制了日志段对象新增索引项的频率。默认情况下日志段写入4KB的消息才会新增一条索引项目
rollJitterMs:是一个抖动值,如果没有这个干扰值,未来某个时刻可能同时创建多个日志段对象,将会大大的增加IO压力。
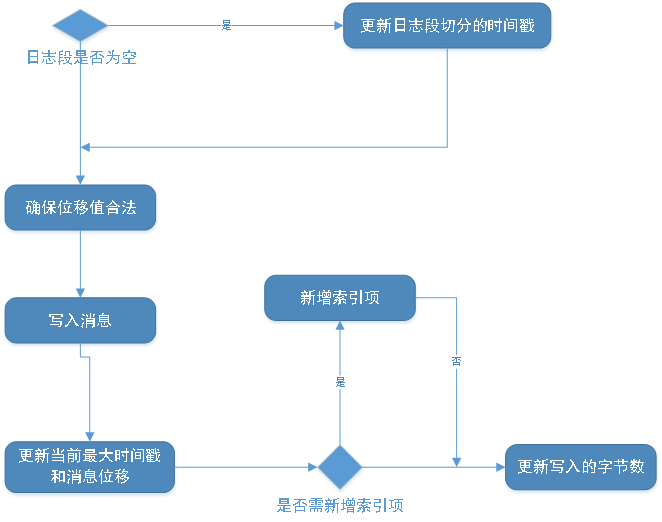
Append方法介绍
以下append源码实现即为写入消息的具体操作
/**
* Append the given messages starting with the given offset. Add
* an entry to the index if needed.
*
* It is assumed this method is being called from within a lock.
*
* @param largestOffset The last offset in the message set
* @param largestTimestamp The largest timestamp in the message set.
* @param shallowOffsetOfMaxTimestamp The offset of the message that has the largest timestamp in the messages to append.
* @param records The log entries to append.
* @return the physical position in the file of the appended records
* @throws LogSegmentOffsetOverflowException if the largest offset causes index offset overflow
*/
@nonthreadsafe
def append(largestOffset: Long,
largestTimestamp: Long,
shallowOffsetOfMaxTimestamp: Long,
records: MemoryRecords): Unit = {
if (records.sizeInBytes > 0) {
trace(s"Inserting ${records.sizeInBytes} bytes at end offset $largestOffset at position ${log.sizeInBytes} " +
s"with largest timestamp $largestTimestamp at shallow offset $shallowOffsetOfMaxTimestamp")
val physicalPosition = log.sizeInBytes()
if (physicalPosition == 0)
rollingBasedTimestamp = Some(largestTimestamp)
ensureOffsetInRange(largestOffset)
// append the messages
val appendedBytes = log.append(records)
trace(s"Appended $appendedBytes to ${log.file} at end offset $largestOffset")
// Update the in memory max timestamp and corresponding offset.
if (largestTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = largestTimestamp
offsetOfMaxTimestampSoFar = shallowOffsetOfMaxTimestamp
}
// append an entry to the index (if needed)
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0
}
bytesSinceLastIndexEntry += records.sizeInBytes
}
}
append方法入参介绍:
largestOffset:写入消息批次中消息的最大位移值
largestTimestamp:写入消息批次中最大的时间戳
shallowOffsetOfMaxTimestamp:写入消息批次中最大时间戳对应消息的位移
records:真正要写入的的消息。
具体实现步骤如下
基于append步骤绘制流程图如下
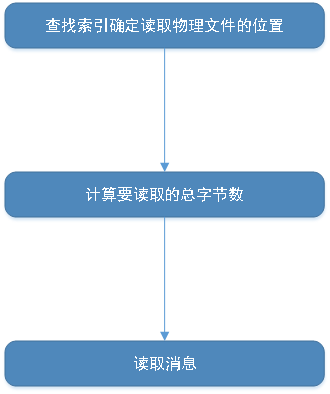
Read方法
read方法接收四个参数
startOffset:要读取的第一条消息的位移
maxSize:能读取的最大字节数
maxPosition:能读取的最大文件的位置
minOneMessage:是否允许在消息体过大时至少返回第1条消息,为了解决消费饿死的情况
具体代码如下
def read(startOffset: Long,
maxSize: Int,
maxPosition: Long = size,
minOneMessage: Boolean = false): FetchDataInfo = {
if (maxSize < 0)
throw new IllegalArgumentException(s"Invalid max size $maxSize for log read from segment $log")
val startOffsetAndSize = translateOffset(startOffset)
// if the start position is already off the end of the log, return null
if (startOffsetAndSize == null)
return null
val startPosition = startOffsetAndSize.position
val offsetMetadata = LogOffsetMetadata(startOffset, this.baseOffset, startPosition)
val adjustedMaxSize =
if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)
else maxSize
// return a log segment but with zero size in the case below
if (adjustedMaxSize == 0)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)
// calculate the length of the message set to read based on whether or not they gave us a maxOffset
val fetchSize: Int = min((maxPosition - startPosition).toInt, adjustedMaxSize)
FetchDataInfo(offsetMetadata, log.slice(startPosition, fetchSize),
firstEntryIncomplete = adjustedMaxSize < startOffsetAndSize.size)
}
实现流程图如下所示