前段时间不知道从哪里弄来的一份知乎数据,数据量不多,只有二十万的样子,今天就以这二十万数据来进行一次简单地数据可视化,主要的工具就是两个:pandas和matplotlib。
以下相关的代码和示例数据在文末有相应的下载链接,你可以下载数据自己尝试。
实际上,你也可以使用BI软件进行分析,速度和可视化效果很好,最主要的是操作相对容易,但是我们拿到的这份示例数据并不规整,也就是有部分内容是乱的,爬虫爬下来的数据有错位的情况,因此对于数据的清洗需要一定的时间,为了方便,我们就直接编程实现。
导入数据
我们使用jupyter notebook作为我们的ide工具
首先来看一下我们的原始数据的样子。
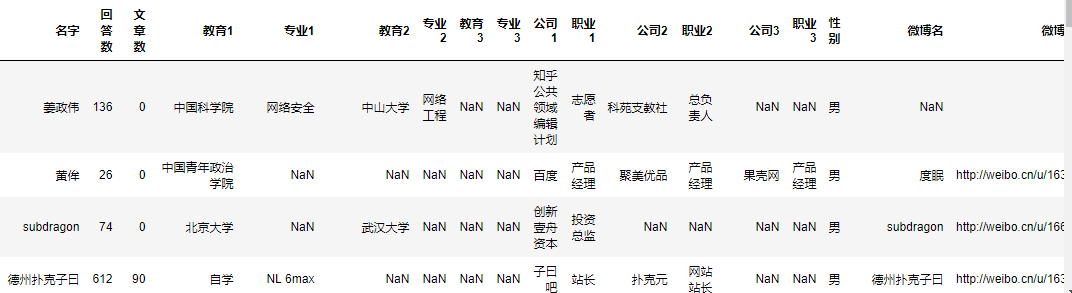
我们习惯于使用英文作为我们的列索引,因此我们在导入数据的时候指定索引的名称,如下所示。

其中,%matplotlib inline指定我们的plt做的图嵌入在ide之中,而不是弹窗显示。
其结果如下所示,后面还有数据列,只是截图容不下了。

知乎用户高校分布情况
我们首先来看一下哪些高校的知乎用户数量最多,核心思路就是我们对高校进行计数,然后按照数量进行降序排序,选择选取前十位进行绘图表示。在实际操作的过程总,我发现了一个问题,计数结果排名比较靠前的数据中有一些是诸如”大学“, ’大学本科‘这样的数据,显然我们需要先将其去掉。
我们自定义一个函数,如果其学校填写的是某一些特定的数据,我们就将其置为空。
因为我们只需要排名靠前的大学,那些名字更加奇葩的我们就不管了,毕竟我们用不到。

下面就直接开始绘图了。

其结果如下
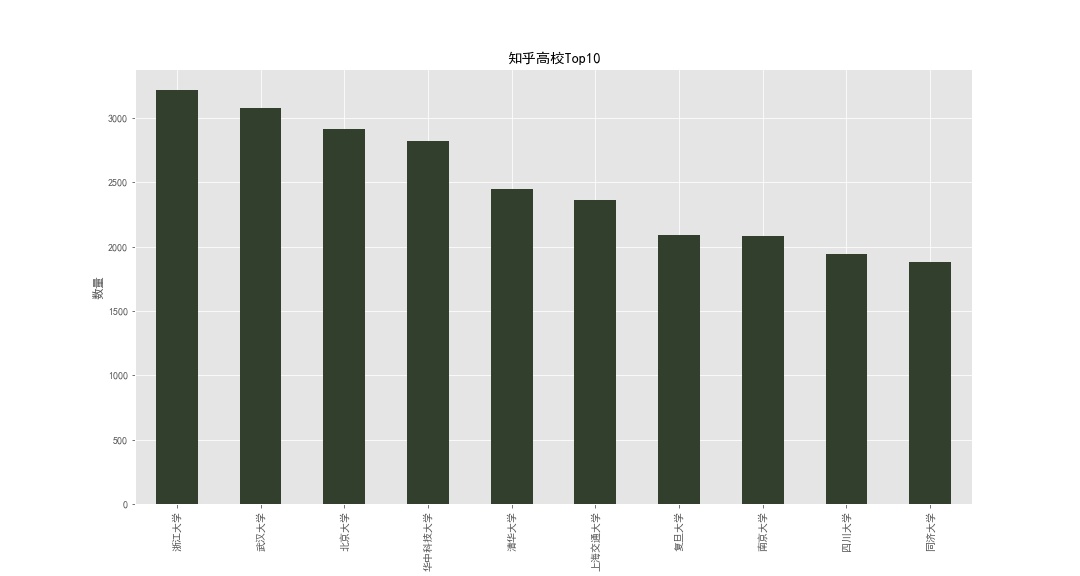
一眼望过去,你会发现全是985高校,真是着实让人悲伤。
既然那么多的985,那么我们下一步的思路就是,看一下985的人数在总人数中所占的比例。
985高校用户占比
思路就是我们定义一个函数,如果这所学校是985的话,我们就给他一个记号为1,如果不是就为0,为什么是1/0而不是其他的呢,待会我们作图的时候你就知道了。

看一下效果
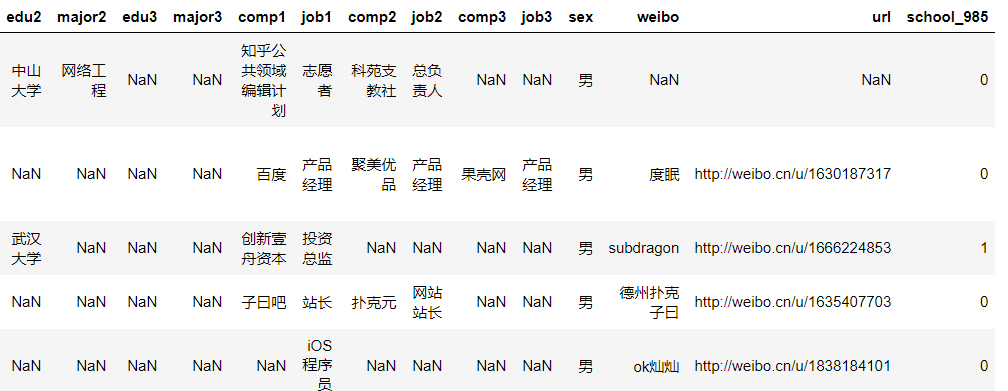
检查一下是不是已经完全的实现了标记情况。

直接开始绘图吧

简单地解释一下clean_name.name = ''在绘制饼图的时候,Series的name会默认以标签的形式出现在饼图的左边,好好的一个饼图,左边多了一个label显然是不美观的,因此我们直接将Series的name去掉,你可以尝试注释掉这一行,来看一下会是什么样子。
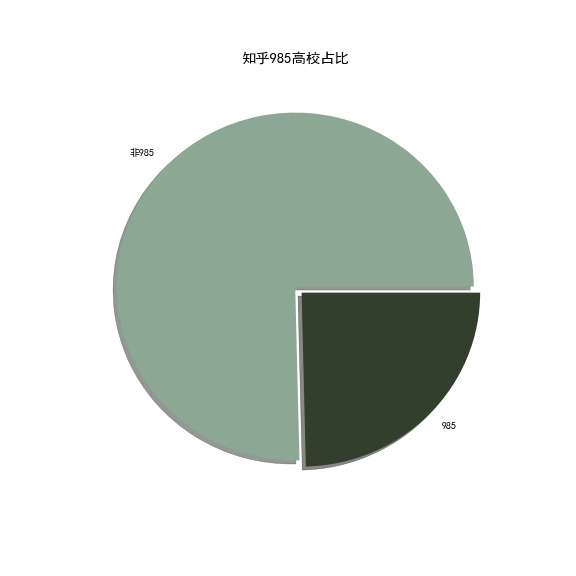
从上面的饼图可以看到,虽然985高校只有34所,但是其占比达到了1/4,真是让人怀疑这些高校的学生是不是人手一个知乎App。
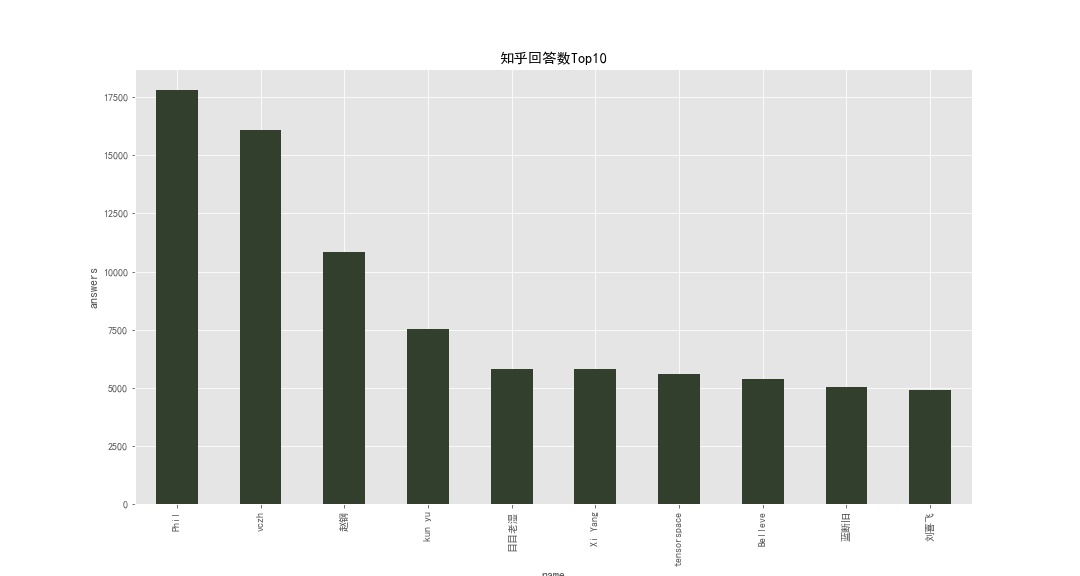
回答数Top10
这个地方就出现了数据混乱的情况,按理说,回答都是整数,但是这里面的部分数据出现了值为汉字的情况,因此,要想进行下一步的分析,只能先对这些数据进行处理。
使用正则表达式,将非数字全部替换为0,最后把这一列的数据类型转换成整型。

我们这里将用户名作为我们的索引,方便下一步的绘图。

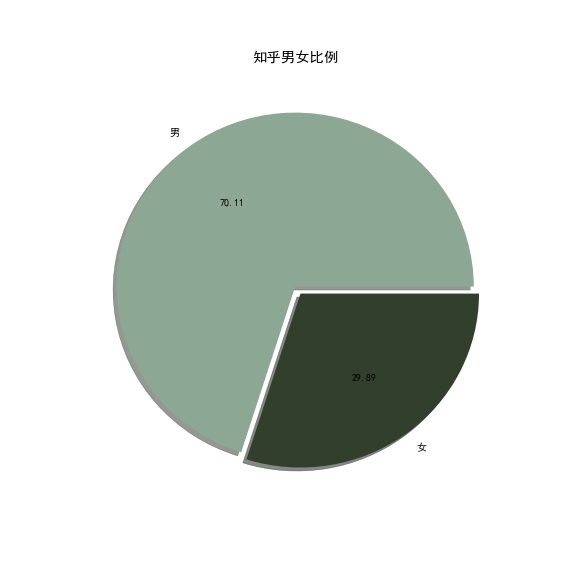
知乎性别比例

词云展示
最后,我们将以上数据中所呈现的专业进行一下词频统计,并制作出词云。


计算机,金融完胜。
既然做到这了,顺便在看一下这些大V的就职公司。


做的非常的粗糙,看到的同学请见谅。
你可以去github下载以上的代码和相应的数据。