1.处理数据集:将用户行为数据集按照均匀分布随机分成M份,挑选一份作为测试集,剩下的M-1份作为训练集

import random
def splitData(data,M,k,seed):
test={}
train={}
random.seed(seed)
for user,item in data:
if random.randint(0,M)==k:
test.append([user.item])
else:
train.append([user.item])
return test,train
2.评测指标
①准确率和召回率
对用户u推荐N个物品(记为R(u)),令用户u在测试集上喜欢的物品的集合为T(u),召回率和准确率可以用来评测推荐算法的精度,计算公式为
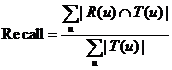
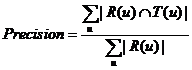
def Recall(train,test,N):
hit=0
all=0
for user in train.keys():
Tu=test[user]
rank=GetRecommendation(user,N)
for item,pui in rank:
if item in Tu:
hit+=1
all+=len(Tu)
return hit/(all*1.0)
def Precision(train,test,N):
hit=0
all=0
for user in train.keys():
Tu=test[user]
rank=GetRecommendation(user,N)
for item,pui in rank:
if item in Tu:
hit+=1
all+=N
return hit/(all*1.0)
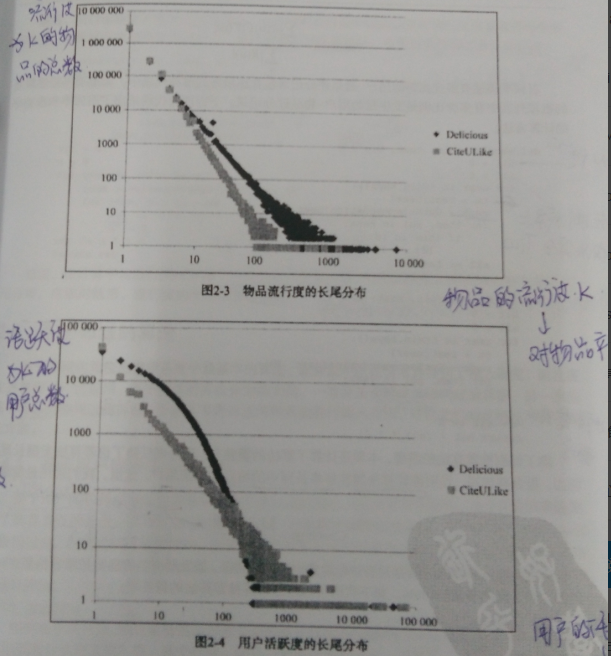
②覆盖率覆盖率反应了推荐算法发掘长尾的能力,覆盖率越高,说明推荐算法越能将长尾中的物品推荐给用户,覆盖率定义为:
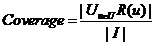
其中I表示所有物品的集合,覆盖率表示最终的推荐列表中包含多大比例的物品,如果所有用户都被推荐给至少一个用户,则覆盖率为100%,计算覆盖率的算法为:
def Coverage(train,test,N):
recommend_items=set()
all_items=set()
for user in train.keys():
for item in train[user].keys():
all_items.add(item)
rank=GetRecommendation(user,N)
for item,Pui in rank:
recommend_items.add(item)
return len(recommend_items)/(len(all_items)*1.0)
③推荐的新颖度,用推荐列表中物品的平均流行度度量推荐结果的新颖都,如果推荐出的物品都很热门,说明推荐的新颖度较低,否则说明推荐结果比较新颖
def Popularity(train,test,N):
item_popularity=dict()
for user,items in train.items():
for item in items.keys():
if item not in item_popularity:
item_popularity[item]=0
item_popularity[item]+=1
ret=0
n=0
for user in train.keys():
ret+=math.log(1+item_popularity[item])
n+=1
ret/=n*1.0
return ret
在计算平均流行度时对每个物品发流行度取对数,这是因为武平的流行度分布满足长尾分布,在取对数后,流行度的平均值更加稳定。