时间模块
时间分为三种类型:时间戳,结构化时间,格式化时间


#时间模块,time import time #时间戳 x = time.time() time.gmtime() #将时间戳转换成UTC时间元组 y = time.localtime() #将时间戳转换成本地时区的时间元组 print(y) #结构化数据,为元组的形式 y = time.mktime(y) #将结构化数据转换成时间戳 print(y) #格式化数据 z = time.strftime("%Y-%m-%d %H:%M:%S",y) #将结构化数据转换成格式化数据 #time.strftime("格式","结构化的时间数据(元组)") --->将结构化时间数据转化成格式化时间数据 #time.strptime("格式化时间字符串","格式") ----->按着给定的格式进行匹配格式化时间字符串,并转换成格式化时间数据 示例 # >>> x = time.localtime() # >>> print(x) # time.struct_time(tm_year=2017, tm_mon=7, tm_mday=9, tm_hour=23, tm_min=11, tm_se # c=32, tm_wday=6, tm_yday=190, tm_isdst=0) # >>> time.strftime("%Y-%m-%d %H:%M:%S",x) #即%Y去匹配tm_year,%m匹配tm_mon,无须注意顺序 # '2017-07-09 23:11:32' # >>> # >>> time.strptime('2017-07-09 23:11:32',"%Y-%m-%d %H:%M:%S") %Y 匹配2017,必须注意顺序 # time.struct_time(tm_year=2017, tm_mon=7, tm_mday=9, tm_hour=23, tm_min=11, tm_se # c=32, tm_wday=6, tm_yday=190, tm_isdst=-1) # # time.ctime(x) #将时间戳数据转换成特定格式 # >>> time.ctime(x) # 'Mon Jul 10 19:26:16 2017' # >>> time.asctime(y) #将结构化数据转换成特定格式 # 'Mon Jul 10 19:26:45 2017'
时间加减
import datetime print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 print(datetime.datetime.now() ) print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 c_time = datetime.datetime.now() print(c_time.replace(minute=3,hour=2)) #时间替换
时间转换图
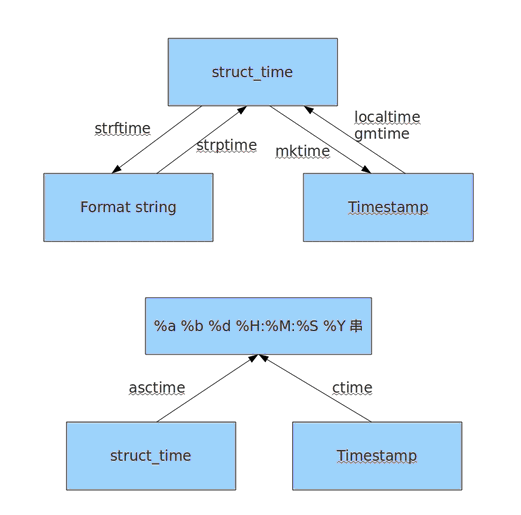
随机模块
1 import random 2 # print(random.randint(1,9)) 3 # print(random.random()) 4 # 5 # print(random.randrange(2,10,4)) 6 # print(random.sample('chenglv',2)) 7 # print(random.randrange(0,99,2)) 8 # print(random.uniform(1,10)) 生成验证码 10 checkcode = "" 11 for i in range(4): 12 x = random.randint(0, 9) 13 y = random.choice("adbcdefglikopnm") 14 if i == random.randint(0,3): 15 tmp = x 16 else: 17 tmp = y 18 checkcode += str(tmp) 19 20 print(checkcode)
os 模块
1 import os 2 os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 3 os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd 4 os.curdir #返回当前目录: ('.') 5 os.pardir #获取当前目录的父目录字符串名:('..') 6 os.makedirs('dirname1/dirname2') #可生成多层递归目录 7 os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 8 os.mkdir('dirname') #生成单级目录;相当于shell中mkdir dirname 9 os.rmdir('dirname') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 10 os.listdir('dirname') #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 11 os.remove() #删除一个文件 12 os.rename("oldname","newname") #重命名文件/目录 13 os.stat('path/filename') # 获取文件/目录信息 14 os.sep #输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" 15 os.linesep #输出当前平台使用的行终止符,win下为" ",Linux下为" " 16 os.pathsep #输出用于分割文件路径的字符串 17 os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 18 os.system("bash command") #运行shell命令,直接显示 19 os.environ #获取系统环境变量 20 os.path.abspath('dirname') #返回path规范化的绝对路径 21 os.path.split('dirname') #将path分割成目录和文件名二元组返回 22 os.path.dirname('dirname') #返回path的目录。其实就是os.path.split(path)的第一个元素 23 os.path.basename('dirname') #返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 24 os.path.exists('dirname') #如果path存在,返回True;如果path不存在,返回False 25 os.path.isabs('dirname') #如果path是绝对路径,返回True 26 os.path.isfile('dirname') #如果path是一个存在的文件,返回True。否则返回False 27 os.path.isdir('dirname') #如果path是一个存在的目录,则返回True。否则返回False 28 os.path.join('dirname'[, 'dirname'[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 29 os.path.getatime('dirname') #返回path所指向的文件或者目录的最后存取时间 30 os.path.getmtime('dirname') #返回path所指向的文件或者目录的最后修改时间
sys模块
1 import sys 2 # print(sys.argv[1]) #可以处理传递的参数 3 # F:pythonoldboyday5>python os_module.py 1 2 3 4 # 1 5 # 6 # sys.argv 7 # F:pythonoldboyday5>python os_module.py 1 2 3 #1,2,3是参数 8 # ['os_module.py', '1', '2', '3'] 9 # import time 10 # for i in range(100): 11 # time.sleep(0.1) 12 # sys.stdout.flush() #在控制台输出,flush是立刻输出 13 # sys.stdout.write('!') #write是输出内容 14 15 # print(sys.path) 16 # print(sys.platform) 17 print(sys.version) #输出python版本信息
配置更改 模块 configparser
1 config = configparser.ConfigParser() 2 # config["DEFAULT"] ={'ServerAliveInterval':'45', 3 # 'Compression':'yes', 4 # 'CompressionLevel':'9' 5 # 6 # } 7 # config['bitbucket.org'] = {} 8 # config['bitbucket.org']['User'] = 'LC' 9 # config['topsecret.server.com'] = {} 10 # topsecret = config['topsecret.server.com'] 11 # topsecret['Host Port'] = '80' 12 # topsecret['ForwardX11'] = 'no' 13 # config['DEFAULT']['USER'] = 'LC' 14 # with open('example.ini','w') as f: 15 # config.write(f) 16 config.read('example.txt') 17 # sec = config.remove_section('bitbucket.org') 18 # config.write(open('example.txt','w')) 19 20 # config.add_section('XMMMMMM') 21 # config.write(open('example.txt','w')) 22 a = config.has_section('XMMMMMM') 23 config.set("XMMMMMM","server",'10.1.1.2') 24 config.write(open('example.txt','w'))
运行效果,根据需求,可以保存成文件,并通过调用configparser进行修改
[DEFAULT] serveraliveinterval = 45 compression = yes compressionlevel = 9 user = LC [bitbucket.org] user = LC [topsecret.server.com] host port = 80 forwardx11 = no [XMMMMMM] server = 10.1.1.2
文件压缩,复制模块shutil
1 import shutil 2 # f1 = open("file1",encoding="utf-8") 3 # f2 = open("file2","w",encoding="utf-8") 4 # shutil.copyfileobj(f1,f2) 5 # shutil.copy("file2","file3") #复制文件和权限 6 # shutil.copystat("file3","file2") #复制权限信息,但是内容不拷贝 7 # shutil.copyfile() #复制文件 8 # shutil.copytree() #递归复制,即复制整一个目录,包含内容 9 # shutil.rmtree() #递归删除,即将目录所有内容删除 10 # shutil.copymode() #仅拷贝权限,内容,组,用户均不变 11 # shutil.move() #移动目录 12 # shutil.make_archive("shutil_archive_test","zip","F:pythonoldboyday5") #压缩文件名,压缩类型,要压缩的文件目录 13 14 import zipfile 15 z = zipfile.ZipFile("day5.zip","w") 16 z.write("file2") 17 z.write("file1")
xml模块
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) # 遍历xml文档 # for child in root: # print(child.tag, child.attrib) # for i in child: # print(i.tag, i.text,i.attrib) # # # 只遍历year 节点 # for node in root.iter('year'): # print(node.tag, node.text) #修改xml # for node in root.iter('year'): # new_year = int(node.text) +1 # node.text = str(new_year) # node.set("update_by","LC") # tree.write("xmltest.xml") #删除node # for country in root.findall('country'): # rank = int(country.find('rank').text) # if rank > 50: # root.remove(country) # tree.write("output.xml") new_xml = ET.Element("namelist") name = ET.SubElement(new_xml, "name", attrib={"enrolled": "yes"}) name.text = "XMM" age = ET.SubElement(name, "age", attrib={"checked": "no"}) sex = ET.SubElement(name, "sex") sex.text = '33' name2 = ET.SubElement(new_xml, "name", attrib={"enrolled": "no"}) age = ET.SubElement(name2, "age") age.text = '19' name2.text = "Huang Dou" et = ET.ElementTree(new_xml) # 生成文档对象 et.write("test.xml", encoding="utf-8", xml_declaration=True) ET.dump(new_xml) # 打印生成的格式
xml模块运行效果
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year update_by="LC">2009</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
<info>
<hello1>what1</hello1>
<hello2>what2</hello2>
</info>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year update_by="LC">2012</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year update_by="LC">2012</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
shelve模块:通过shelve模块,实现key,value的存储,即通过shelve模块,可以将k,v的值直接存入文件中,并可以通过shelve直接通过key调用
import shelve import datetime d = shelve.open('shelve_test') info = {'age':22,'job':'it'} name = ['alex','rain','test'] d['name'] = name #将name信息存入文件中 d['info'] = info d['date'] = datetime.datetime.now() d.close() ====== print(d.get('name')) #可以直接获取 print(d.get('info')) print(d.get('date'))