 (2017-04-10 银河统计)
(2017-04-10 银河统计)KNN算法即K Nearest Neighbor算法。这个算法是机器学习里面一个比较经典的、相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法是用来做归类的,也就是说,一个样本空间里的样本已经分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
一个比较经典的KNN图如下:
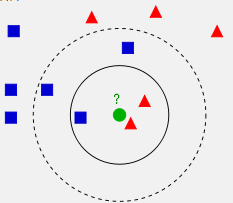
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看到,机器学习的本质是基于一种数据统计的方法或准则,k近邻(KNN)方法和其它聚类、分类等数据挖掘方法的理论基础是地理学第一定律(Tobler's First Law),即:
All attribute values on a geographic surface are related to each other, but closer values are more strongly related than are more distant ones.
“任何事物都相关,相近的事物关联更紧密”。KNN的基本思想类似于“物以类聚,人以群分”,打个通俗的比方就是“如果你要了解一个人,可以从他最亲近的几个朋友去推测他是什么样的人”,如果要判断一个样本点的类别,去看看和它相似的样本点的类别就行了。
这个算法如何用呢?我们来看2个示例。
一、KNN算法介绍
实例一:KNN分类(产品质量判断问题)###
假设我们需要判断纸巾的品质好坏,纸巾的品质好坏可以抽像出两个向量,一个是“酸腐蚀的时间”,一个是“能承受的压强”。如果我们的样本空间如下:(所谓样本空间,又叫Training Data,也就是用于机器学习的数据),
| 耐酸时间(秒)- $X_1$ | 圧强(公斤/平方米) - $X_2$ | 品质 - Y |
|---|---|---|
| 7 | 7 | 坏 |
| 7 | 4 | 坏 |
| 3 | 4 | 好 |
| 1 | 4 | 好 |
那么,如果(X_1=3)和(X_2=7), 这个毛巾的品质是什么呢?这里就可以用KNN算法来判断。
假设K=3,K应该是一个奇数,这样可以保证不会有平票,下面是我们计算(3,7)到所有点的欧氏距离。
| 耐酸时间(秒)- $X_1$ | 圧强(公斤/平方米) - $X_2$ | 计算各点到 (3, 7)的距离 | 品质 - Y |
|---|---|---|---|
| 7 | 7 | $sqrt{(7-3)^2+(7-7)^2}=4$ | 坏 |
| 7 | 4 | $sqrt{(7-3)^2+(4-7)^2}=5$ | N/A |
| 3 | 4 | $sqrt{(3-3)^2+(4-7)^2}=3$ | 好 |
| 1 | 4 | $sqrt{(1-3)^2+(4-7)^2}=3.61$ | 好 |
所以,最后的投票,好的有2票,坏的有1票,最终需要测试的(3,7)是合格品。
实例二:KNN预测(回归问题)###
设有多元样本如下表:
| 样本序号 | $X_1$ | $X_2$ | $X_3$ | Y |
|---|---|---|---|---|
| S1 | 1 | 2.1 | 5.5 | 22 |
| S2 | 1.3 | 3.2 | 4.4 | 17 |
| S3 | 3.5 | 4.4 | 6.8 | 20 |
| S4 | 4.1 | 5 | 8 | 27 |
| S5 | 5.1 | 7 | 8.9 | 30 |
自变量样本向量S0为,(X_1=5)、(X_2=6)、(X_3=8),(Y=?)。
解、依次计算S0到S1、S2、...、S5的欧氏距离为,6.12、5.87、2.5、1.345、1.349,取K=2,(Y=frac{27+31}{2}=28.5);取K=3,(Y=frac{20+27+31}{3}=25.67)。
通过示例可以看出,KNN算法要解决好下面几个问题:
I、如何度量邻居之间的相似度,也就是如何选取邻居的问题。相似性的度量方式在很大程度上决定了选取邻居的准确性,也决定了分类的效果,因为判定一个样本点的类别是要利用到它的邻居的,如果邻居都没选好,准确性就无从谈起。因此我们需要用一个量来定量的描述邻居之间的距离(如欧氏距离),也可以形象的表述为邻居之间的相似度;
II、找多少个邻居才合适。如果K选大了的话,可能求出来的k最近邻集合可能包含了太多隶属于其它类别的样本点,最极端的就是k取训练集的大小,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用信息。如果K选小了的话,结果对噪音样本点很敏感。那么到底如何选取K值,一般靠经验或者交叉验证(一部分样本做训练集,一部分做测试集)的方法,就是是K值初始取一个比较小的数值,之后不段来调整K值的大小来时的分类最优,得到的K值就是我们要的,但是这个K值也只是对这个样本集是最优的。一般采用k为奇数,跟投票表决一样,避免因两种票数相等而难以决策;
III、如何去寻找这k个邻居。因为对每一个待测样本点来说,都要对整个样本集逐一计算其与待测点的距离,计算并存储好以后,再查找K近邻,这是最简单、直接的方法,但计算量非常大。因此KNN的一大缺点需要存储全部训练样本,以及繁重的距离计算量。样本过的时,应该寻找简单算法,如KD树等;
IV、用k个邻居估计待测样本点。根据样本特征,采用投票制少数服从多数或算术平均数(也可以考虑中位数)、加权平均数等。加权平均数一般采用两者之间距离的倒数为权重。
二、KNN分类代码样例
鸢尾花[iris]数据(R语言经典聚类、分类案例数据)
| ID | Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 6 | 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 7 | 4.6 | 3.4 | 1.4 | 0.3 | setosa |
| 8 | 5.0 | 3.4 | 1.5 | 0.2 | setosa |
| 9 | 4.4 | 2.9 | 1.4 | 0.2 | setosa |
| 10 | 4.9 | 3.1 | 1.5 | 0.1 | setosa |
| 11 | 5.4 | 3.7 | 1.5 | 0.2 | setosa |
| 12 | 4.8 | 3.4 | 1.6 | 0.2 | setosa |
| 13 | 4.8 | 3.0 | 1.4 | 0.1 | setosa |
| 14 | 4.3 | 3.0 | 1.1 | 0.1 | setosa |
| 15 | 5.8 | 4.0 | 1.2 | 0.2 | setosa |
| 16 | 5.7 | 4.4 | 1.5 | 0.4 | setosa |
| 17 | 5.4 | 3.9 | 1.3 | 0.4 | setosa |
| 18 | 5.1 | 3.5 | 1.4 | 0.3 | setosa |
| 19 | 5.7 | 3.8 | 1.7 | 0.3 | setosa |
| 20 | 5.1 | 3.8 | 1.5 | 0.3 | setosa |
| 21 | 5.4 | 3.4 | 1.7 | 0.2 | setosa |
| 22 | 5.1 | 3.7 | 1.5 | 0.4 | setosa |
| 23 | 4.6 | 3.6 | 1.0 | 0.2 | setosa |
| 24 | 5.1 | 3.3 | 1.7 | 0.5 | setosa |
| 25 | 4.8 | 3.4 | 1.9 | 0.2 | setosa |
| 26 | 5.0 | 3.0 | 1.6 | 0.2 | setosa |
| 27 | 5.0 | 3.4 | 1.6 | 0.4 | setosa |
| 28 | 5.2 | 3.5 | 1.5 | 0.2 | setosa |
| 29 | 5.2 | 3.4 | 1.4 | 0.2 | setosa |
| 30 | 4.7 | 3.2 | 1.6 | 0.2 | setosa |
| 31 | 4.8 | 3.1 | 1.6 | 0.2 | setosa |
| 32 | 5.4 | 3.4 | 1.5 | 0.4 | setosa |
| 33 | 5.2 | 4.1 | 1.5 | 0.1 | setosa |
| 34 | 5.5 | 4.2 | 1.4 | 0.2 | setosa |
| 35 | 4.9 | 3.1 | 1.5 | 0.2 | setosa |
| 36 | 5.0 | 3.2 | 1.2 | 0.2 | setosa |
| 37 | 5.5 | 3.5 | 1.3 | 0.2 | setosa |
| 38 | 4.9 | 3.6 | 1.4 | 0.1 | setosa |
| 39 | 4.4 | 3.0 | 1.3 | 0.2 | setosa |
| 40 | 5.1 | 3.4 | 1.5 | 0.2 | setosa |
| 41 | 5.0 | 3.5 | 1.3 | 0.3 | setosa |
| 42 | 4.5 | 2.3 | 1.3 | 0.3 | setosa |
| 43 | 4.4 | 3.2 | 1.3 | 0.2 | setosa |
| 44 | 5.0 | 3.5 | 1.6 | 0.6 | setosa |
| 45 | 5.1 | 3.8 | 1.9 | 0.4 | setosa |
| 46 | 4.8 | 3.0 | 1.4 | 0.3 | setosa |
| 47 | 5.1 | 3.8 | 1.6 | 0.2 | setosa |
| 48 | 4.6 | 3.2 | 1.4 | 0.2 | setosa |
| 49 | 5.3 | 3.7 | 1.5 | 0.2 | setosa |
| 50 | 5.0 | 3.3 | 1.4 | 0.2 | setosa |
| 51 | 7.0 | 3.2 | 4.7 | 1.4 | versicolor |
| 52 | 6.4 | 3.2 | 4.5 | 1.5 | versicolor |
| 53 | 6.9 | 3.1 | 4.9 | 1.5 | versicolor |
| 54 | 5.5 | 2.3 | 4.0 | 1.3 | versicolor |
| 55 | 6.5 | 2.8 | 4.6 | 1.5 | versicolor |
| 56 | 5.7 | 2.8 | 4.5 | 1.3 | versicolor |
| 57 | 6.3 | 3.3 | 4.7 | 1.6 | versicolor |
| 58 | 4.9 | 2.4 | 3.3 | 1.0 | versicolor |
| 59 | 6.6 | 2.9 | 4.6 | 1.3 | versicolor |
| 60 | 5.2 | 2.7 | 3.9 | 1.4 | versicolor |
| 61 | 5.0 | 2.0 | 3.5 | 1.0 | versicolor |
| 62 | 5.9 | 3.0 | 4.2 | 1.5 | versicolor |
| 63 | 6.0 | 2.2 | 4.0 | 1.0 | versicolor |
| 64 | 6.1 | 2.9 | 4.7 | 1.4 | versicolor |
| 65 | 5.6 | 2.9 | 3.6 | 1.3 | versicolor |
| 66 | 6.7 | 3.1 | 4.4 | 1.4 | versicolor |
| 67 | 5.6 | 3.0 | 4.5 | 1.5 | versicolor |
| 68 | 5.8 | 2.7 | 4.1 | 1.0 | versicolor |
| 69 | 6.2 | 2.2 | 4.5 | 1.5 | versicolor |
| 70 | 5.6 | 2.5 | 3.9 | 1.1 | versicolor |
| 71 | 5.9 | 3.2 | 4.8 | 1.8 | versicolor |
| 72 | 6.1 | 2.8 | 4.0 | 1.3 | versicolor |
| 73 | 6.3 | 2.5 | 4.9 | 1.5 | versicolor |
| 74 | 6.1 | 2.8 | 4.7 | 1.2 | versicolor |
| 75 | 6.4 | 2.9 | 4.3 | 1.3 | versicolor |
| 76 | 6.6 | 3.0 | 4.4 | 1.4 | versicolor |
| 77 | 6.8 | 2.8 | 4.8 | 1.4 | versicolor |
| 78 | 6.7 | 3.0 | 5.0 | 1.7 | versicolor |
| 79 | 6.0 | 2.9 | 4.5 | 1.5 | versicolor |
| 80 | 5.7 | 2.6 | 3.5 | 1.0 | versicolor |
| 81 | 5.5 | 2.4 | 3.8 | 1.1 | versicolor |
| 82 | 5.5 | 2.4 | 3.7 | 1.0 | versicolor |
| 83 | 5.8 | 2.7 | 3.9 | 1.2 | versicolor |
| 84 | 6.0 | 2.7 | 5.1 | 1.6 | versicolor |
| 85 | 5.4 | 3.0 | 4.5 | 1.5 | versicolor |
| 86 | 6.0 | 3.4 | 4.5 | 1.6 | versicolor |
| 87 | 6.7 | 3.1 | 4.7 | 1.5 | versicolor |
| 88 | 6.3 | 2.3 | 4.4 | 1.3 | versicolor |
| 89 | 5.6 | 3.0 | 4.1 | 1.3 | versicolor |
| 90 | 5.5 | 2.5 | 4.0 | 1.3 | versicolor |
| 91 | 5.5 | 2.6 | 4.4 | 1.2 | versicolor |
| 92 | 6.1 | 3.0 | 4.6 | 1.4 | versicolor |
| 93 | 5.8 | 2.6 | 4.0 | 1.2 | versicolor |
| 94 | 5.0 | 2.3 | 3.3 | 1.0 | versicolor |
| 95 | 5.6 | 2.7 | 4.2 | 1.3 | versicolor |
| 96 | 5.7 | 3.0 | 4.2 | 1.2 | versicolor |
| 97 | 5.7 | 2.9 | 4.2 | 1.3 | versicolor |
| 98 | 6.2 | 2.9 | 4.3 | 1.3 | versicolor |
| 99 | 5.1 | 2.5 | 3.0 | 1.1 | versicolor |
| 100 | 5.7 | 2.8 | 4.1 | 1.3 | versicolor |
| 101 | 6.3 | 3.3 | 6.0 | 2.5 | virginica |
| 102 | 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 103 | 7.1 | 3.0 | 5.9 | 2.1 | virginica |
| 104 | 6.3 | 2.9 | 5.6 | 1.8 | virginica |
| 105 | 6.5 | 3.0 | 5.8 | 2.2 | virginica |
| 106 | 7.6 | 3.0 | 6.6 | 2.1 | virginica |
| 107 | 4.9 | 2.5 | 4.5 | 1.7 | virginica |
| 108 | 7.3 | 2.9 | 6.3 | 1.8 | virginica |
| 109 | 6.7 | 2.5 | 5.8 | 1.8 | virginica |
| 110 | 7.2 | 3.6 | 6.1 | 2.5 | virginica |
| 111 | 6.5 | 3.2 | 5.1 | 2.0 | virginica |
| 112 | 6.4 | 2.7 | 5.3 | 1.9 | virginica |
| 113 | 6.8 | 3.0 | 5.5 | 2.1 | virginica |
| 114 | 5.7 | 2.5 | 5.0 | 2.0 | virginica |
| 115 | 5.8 | 2.8 | 5.1 | 2.4 | virginica |
| 116 | 6.4 | 3.2 | 5.3 | 2.3 | virginica |
| 117 | 6.5 | 3.0 | 5.5 | 1.8 | virginica |
| 118 | 7.7 | 3.8 | 6.7 | 2.2 | virginica |
| 119 | 7.7 | 2.6 | 6.9 | 2.3 | virginica |
| 120 | 6.0 | 2.2 | 5.0 | 1.5 | virginica |
| 121 | 6.9 | 3.2 | 5.7 | 2.3 | virginica |
| 122 | 5.6 | 2.8 | 4.9 | 2.0 | virginica |
| 123 | 7.7 | 2.8 | 6.7 | 2.0 | virginica |
| 124 | 6.3 | 2.7 | 4.9 | 1.8 | virginica |
| 125 | 6.7 | 3.3 | 5.7 | 2.1 | virginica |
| 126 | 7.2 | 3.2 | 6.0 | 1.8 | virginica |
| 127 | 6.2 | 2.8 | 4.8 | 1.8 | virginica |
| 128 | 6.1 | 3.0 | 4.9 | 1.8 | virginica |
| 129 | 6.4 | 2.8 | 5.6 | 2.1 | virginica |
| 130 | 7.2 | 3.0 | 5.8 | 1.6 | virginica |
| 131 | 7.4 | 2.8 | 6.1 | 1.9 | virginica |
| 132 | 7.9 | 3.8 | 6.4 | 2.0 | virginica |
| 133 | 6.4 | 2.8 | 5.6 | 2.2 | virginica |
| 134 | 6.3 | 2.8 | 5.1 | 1.5 | virginica |
| 135 | 6.1 | 2.6 | 5.6 | 1.4 | virginica |
| 136 | 7.7 | 3.0 | 6.1 | 2.3 | virginica |
| 137 | 6.3 | 3.4 | 5.6 | 2.4 | virginica |
| 138 | 6.4 | 3.1 | 5.5 | 1.8 | virginica |
| 139 | 6.0 | 3.0 | 4.8 | 1.8 | virginica |
| 140 | 6.9 | 3.1 | 5.4 | 2.1 | virginica |
| 141 | 6.7 | 3.1 | 5.6 | 2.4 | virginica |
| 142 | 6.9 | 3.1 | 5.1 | 2.3 | virginica |
| 143 | 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 144 | 6.8 | 3.2 | 5.9 | 2.3 | virginica |
| 145 | 6.7 | 3.3 | 5.7 | 2.5 | virginica |
| 146 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 147 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 148 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 149 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 150 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
KNN分类算法代码
## 函数 - Knn分类
webTJ.Datamining.getKNNClass(xarrs,yarr,sarrs,k,dtype,p);
##参数
【xarrs,yarr,sarrs,k,dtype,p】
【学习样本,分类属性样本,测试样本,k近邻,距离类型,闵氏距离系数】
注:距离类型dtype取1、2、3、4、5、6、7、8,9分别为欧氏距离、曼哈顿距离、切比雪夫距离、闵氏距离、马氏距离、皮尔逊相关系数、斯皮尔曼秩相关系数、肯德尔秩相关系数、余弦相似度
代码样例
webTJ.clear();
var oData=oIRIS; //鸢尾花数据字符串
var oArrs=webTJ.getArrs(oData,"|",","); //鸢尾花数据转数组
var oK=5; //5个近邻
var oDType=1; //欧氏距离
var oP=1.5; //闵氏系数
var oSarrs=[[4.9,3.5,1.6,0.2],
[4.5,3.0,1.5,0.2],
[6.2,3.5,4.5,1.5],
[5.7,3.8,1.8,0.3]]; //测试样本1
var oYarr=webTJ.Array.getColData(oArrs,4); //获得鸢尾花数组第4列,分类属性样本
var oXarrs=webTJ.Matrix.getRemoveCol(oArrs,4); //删除数组第4列,学习样本
var oKNNarrs=webTJ.Datamining.getKNNClass(oXarrs,oYarr,oSarrs,oK,oDType,oP); //测试样本1KNN计算
webTJ.show(oKNNarrs[0],2); //k近邻分类属性
webTJ.show(oKNNarrs[1],2); //k近测试样本距离
webTJ.show(oKNNarrs[2],2); //k近测分类
var oStr="4.60,5.35,3.87,2.93|3.03,4.33,3.64,2.14|5.73,3.38,3.37,2.41|3.74,4.12,2.64,1.57|5.66,4.84,2.93,0.60|6.49,6.00,3.92,2.14|6.46,3.53,3.56,2.21|5.64,5.27,3.18,0.49|6.34,3.39,2.99,0.17|3.14,3.60,3.57,2.83|3.43,4.18,3.60,1.98|3.15,5.81,2.77,2.14|6.30,3.72,3.54,0.05|6.23,4.07,2.03,2.05|5.86,3.46,3.09,2.15|4.55,3.86,3.16,1.79|3.47,4.11,3.95,0.64|4.18,4.49,2.85,2.79|4.48,3.54,3.34,1.95|3.47,5.86,3.38,0.68"; //测试样本字符串
var oArrs=webTJ.getArrs(oStr,"|",","); //转换为数组,测试样本2
oArrs=webTJ.Array.getQuantify(oArrs); //量化测试样本数组
oXarrs=webTJ.Array.getQuantify(oXarrs); //量化学习样本数组
var oKNNarrs=webTJ.Datamining.getKNNClass(oXarrs,oYarr,oArrs,oK,oDType,oP); //测试样本2KNN计算
webTJ.show(oKNNarrs[0],2); //k近邻分类属性
webTJ.show(oKNNarrs[1],2); //k邻近测试样本距离
webTJ.show(oKNNarrs[2],2); //测试样本和分类数组
注:样例代码可进行批量分类,分类结果为三个数组。如果有m组测试样本、取k近邻,第1个数组返回(m imes k)分类属性数组,即每组测试样本k个最邻近的分类属性;第2个数组返回(m imes k)距离数组,即每组测试样本k个最邻近的距离;第3个数组返回每组测试样本分类属性和判别比例(最后一列);
三、KNN预测代码样例
男孩身高、体重和胸围数据(1个月 - 10岁)
| 月数 | 体重(kg) | 身高(cm) | 男胸围(cm) |
|---|---|---|---|
| 1 | 4.3 | 50.5 | 32.8 |
| 2 | 5.15 | 54.55 | 37.9 |
| 3 | 5.95 | 58.1 | 40 |
| 4 | 6.65 | 61.1 | 41.3 |
| 5 | 7.25 | 63.7 | 42.3 |
| 6 | 7.85 | 67.8 | 42.9 |
| 7 | 8.8 | 70.95 | 43.8 |
| 10 | 9.6 | 73.65 | 44.7 |
| 12 | 10.2 | 76.1 | 45.4 |
| 15 | 10.9 | 79.45 | 46.1 |
| 18 | 11.5 | 82.4 | 47.6 |
| 21 | 12.05 | 85.15 | 48.9 |
| 24 | 12.6 | 87.65 | 50.2 |
| 30 | 13.7 | 92.35 | 50.5 |
| 36 | 14.7 | 94.9 | 50.8 |
| 42 | 15.75 | 99.05 | 52.4 |
| 48 | 16.75 | 102.95 | 54 |
| 54 | 17.8 | 106.55 | 55.5 |
| 60 | 18.85 | 109.9 | 57 |
| 66 | 19.85 | 113.1 | 58.5 |
| 72 | 21 | 116.1 | 60 |
| 84 | 23.35 | 121.7 | 61.5 |
| 96 | 26.1 | 126.9 | 62.75 |
| 108 | 29.15 | 132.15 | 64 |
| 120 | 32.75 | 137.5 | 68 |
KNN预测算法代码
## 函数 - Knn预测
webTJ.Datamining.getKNNForecast(xarrs,yarr,sarrs,k,dtype,f,r,p);
##参数
【xarrs,yarr,sarrs,k,dtype,f,r,p】
【学习样本,因变量值样本,测试样本,k近邻,距离类型,预测模式,反距离权重幂,闵氏距离系数】
注:距离类型dtype取1、2、3、4、5、6、7、8,9分别为欧氏距离、曼哈顿距离、切比雪夫距离、闵氏距离、马氏距离、皮尔逊相关系数、斯皮尔曼秩相关系数、肯德尔秩相关系数、余弦相似度;预测模式f取1、2、3分别为K近邻均值、反距离权重法、调整反距离权重法预测
代码样例
webTJ.clear();
var oStr="1,4.3,50.5,32.8|2,5.15,54.55,37.9|3,5.95,58.1,40|4,6.65,61.1,41.3|5,7.25,63.7,42.3|6,7.85,67.8,42.9|7,8.8,70.95,43.8|10,9.6,73.65,44.7|12,10.2,76.1,45.4|15,10.9,79.45,46.1|18,11.5,82.4,47.6|21,12.05,85.15,48.9|24,12.6,87.65,50.2|30,13.7,92.35,50.5|36,14.7,94.9,50.8|42,15.75,99.05,52.4|48,16.75,102.95,54|54,17.8,106.55,55.5|60,18.85,109.9,57|66,19.85,113.1,58.5|72,21,116.1,60|84,23.35,121.7,61.5|96,26.1,126.9,62.75|108,29.15,132.15,64|120,32.75,137.5,68";
var oArrs=webTJ.getArrs(oStr,"|",","); //转换为数组,测试样本2
oArrs=webTJ.Array.getQuantify(oArrs); //量化测试样本数组
var oK=5; //5个近邻
var oDType=1; //欧氏距离
var oF=1; //均值预测
var oR=2; //反距离权重幂
var oP=1.5; //闵氏系数
var oSarrs=[[6,60,41],
[8.7,70,44],
[19,110,57],
[28,132,65]]; //测试样本
var oYarr=webTJ.Array.getColData(oArrs,0); //获得数组第0列,因变量值样本
var oXarrs=webTJ.Matrix.getRemoveCol(oArrs,0); //删除数组第0列,学习样本
var oCMSD=webTJ.Datamining.getCMSD(oXarrs); //获取学习样本列均值和标准差数组
//oXarrs=webTJ.Datamining.getSZarr(oXarrs,oCMSD); //学习样本标准化
//oSarrs=webTJ.Datamining.getYZarrs(oSarrs,1); //测试差标准化
var oKNNarrs=webTJ.Datamining.getKNNForecast(oXarrs,oYarr,oSarrs,oK,oDType,oF,oP); //测试样本KNN计算
webTJ.show(oKNNarrs[0],2); //k近邻因变量值
webTJ.show(oKNNarrs[1],2); //k邻近测试样本距离
webTJ.show(oKNNarrs[2],2); //测试样本和因变量预测值数组
用KNN算法处理数据时,通常学习样本数据较多,需要将EXCEL或网络表格数据转换为格式化字符串、进而转换为数组,并使用webTJ.Array.getQuantify函数量化数组。具体过程参见银河统计博文:数据输入、转换、展示和存储 - 网络统计类函数(1)
反距离权重法
反距离加权插值(IDW,Inverse Distance Weighted),也可以称为距离倒数乘方法。反距离权重插值使用一组样本和某特点样本间的距离的倒数为权数,在运用KNN方法进行预测时,将用K近邻样本量值简单算术平均改为反距离加权平均,体现了距离越近,对估计值影响越大的基本思想。
在KNN预测样例代码中,对4组测试样本取k=5(5个近邻),可得4组样本最近5个样本量值和对应距离表如下:
| 测试样本 | Y1 | Y2 | Y3 | Y4 | Y5 |
|---|---|---|---|---|---|
| 1 | 4 | 3 | 5 | 2 | 6 |
| 2 | 7 | 6 | 10 | 12 | 5 |
| 3 | 60 | 66 | 54 | 72 | 48 |
| 4 | 108 | 96 | 120 | 84 | 72 |
| 测试样本 | D1 | D2 | D3 | D4 | D5 |
|---|---|---|---|---|---|
| 1 | 1.31 | 2.15 | 4.12 | 6.33 | 8.24 |
| 2 | 0.98 | 2.6 | 3.82 | 6.44 | 6.68 |
| 3 | 0.18 | 3.55 | 3.95 | 7.09 | 7.99 |
| 4 | 1.53 | 5.89 | 7.86 | 11.83 | 18.08 |
如果采用简单算术平均数进行预测,将每组测试样本的最近的k个样本量值计算平均数即可,每组测试样本预测值如下表:
| 测试样本 | X1 | X2 | X3 | 预测值Yc |
|---|---|---|---|---|
| 1 | 6 | 60 | 41 | 4 |
| 2 | 8.7 | 70 | 44 | 8 |
| 3 | 19 | 110 | 57 | 60 |
| 4 | 28 | 132 | 65 | 96 |
表中第1个测试样本的5个k近邻样本量值为4、3、5、2、6,(frac{(4+3+5+2+6)}{5}=4),其它测试样本同样处理。
由于最近的k个样本量值的距离不同,本着距离越近相似度越大的原则,可采用反距离加权插值计算。反距离加权公式为,
4组测试样本反距离权数表为,
| 测试样本 | H1 | H2 | H3 | H4 | H5 |
|---|---|---|---|---|---|
| 1 | 0.76 | 0.47 | 0.24 | 0.16 | 0.12 |
| 2 | 1.02 | 0.38 | 0.26 | 0.16 | 0.15 |
| 3 | 5.56 | 0.28 | 0.25 | 0.14 | 0.13 |
| 4 | 0.65 | 0.17 | 0.13 | 0.08 | 0.06 |
注:表中每个权数都是距离的倒数,如第1个测试样本的最邻近距离是1.31,其倒数为(frac{1}{1.31}:approx 0.76)
根据反距离权数计算样本量值加权算术平均数,4组测试样本预测值表如下,
| 测试样本 | X1 | X2 | X3 | 预测值$widehat{Y}$ |
|---|---|---|---|---|
| 1 | 6 | 60 | 41 | 3.83 |
| 2 | 8.7 | 70 | 44 | 7.45 |
| 3 | 19 | 110 | 57 | 60.06 |
| 4 | 28 | 132 | 65 | 103.85 |
以第1个测试样本为例,反距离加权插值算式为,
通常,反距离加权插值预测效果优于简单算术平均数。但有时会出现距离很小或等于0的情况。距离很小时反距离加权插值会过分夸大对应样本量值在估值中的权重,距离为0时则无法使用反距离加权插值。为此可以使用调整反距离权重法。
设k个近邻距离最大值和最小值为Dmax和Dmin。将Dmax向上取整为DUmax、Dmin向下取整为DLmin。例如,k个近邻距离最大值和最小值为12.3和2.6,分别向上和向下取整结果为13和2。调整后的反距离加权公式为,
式中(p)为反距离权数的幂,反距离权重法主要依赖于反距离的幂值。幂参数是一个正实数,默认值为2。幂值大,可进一步强调邻近数据的影响,表面会变得更加详细(更不平滑)。随着幂数的增大,内插值将逐渐接近最近采样点的值。指定较小的幂值将对距离较远的周围点产生更大影响,从而导致更加平滑的表面。
以第1个测试样本为例,取(p=1.5),最大值向上取整为9、最小值向下取整为1,调整反距离权数算式为,
计算4组测试样本每个距离的调整反距离权数,计算表如下,
| 测试样本 | W1 | W2 | W3 | W4 | W5 |
|---|---|---|---|---|---|
| 1 | 0.94 | 0.79 | 0.48 | 0.19 | 0.03 |
| 2 | 0.80 | 0.50 | 0.31 | 0.02 | 0.01 |
| 3 | 0.97 | 0.41 | 0.36 | 0.04 | 0 |
| 4 | 0.96 | 0.62 | 0.49 | 0.25 | 0.01 |
第1个测试样本为例,取(p=1.5),预测值为,
4组测试样本的调整反距离预测值如下表,
| 测试样本 | X1 | X2 | X3 | 预测值$widehat{Y}$ |
|---|---|---|---|---|
| 1 | 6 | 60 | 41 | 3.74 |
| 2 | 8.7 | 70 | 44 | 7.31 |
| 3 | 19 | 110 | 57 | 60.44 |
| 4 | 28 | 132 | 65 | 104.35 |
KNN分类和KNN预测函数返回结果为k近邻因变量值、k邻近距离和测试样本分类或因变量预测值数组,运用KNN进行数据挖掘可以在k近邻因变量值、k邻近距离数组基础上灵活处理。
代码窗口
注:可将例题实例代码复制、粘贴到“代码窗口”,点击“运行代码”获得计算结果(Ctrl+C:复制;Ctrl+V:粘贴;Ctrl+A:全选)
运行效果