一、概况
参考http://www.cnblogs.com/mchina/archive/2013/02/20/2883404.html
openstack目前发展迅猛,特别是开放了big tent项目后,一时间各类以openstack为依托的开源工具提交多达1000多个。
openstack网络组建neutron以复杂晦涩著称,其部署和运维都让人头疼。
United Stack开发了steth项目,用以解决网络复杂问题现状。他是一款集成了http、dhcp、ping、iperf等网络诊断工具的开源项目,稍后研究
nagios是一款流行的网络运维工具,可以通过监测和丰富的通知机制帮助运维管理。详细介绍略。
二、工作原理
Nagios的功能是监控服务和主机,但是他自身并不包括这部分功能,所有的监控、检测功能都是通过各种插件来完成的。 启动Nagios后,它会周期性的自动调用插件去检测服务器状态,同时Nagios会维持一个队列,所有插件返回来的状态信息都进入队列,Nagios每次都从队首开始读取信息,并进行处理后,把状态结果通过web显示出来。 Nagios提供了许多插件,利用这些插件可以方便的监控很多服务状态。安装完成后,在nagios主目录下的/libexec里放有nagios自带的可以使用的所有插件,如,check_disk是检查磁盘空间的插件,check_load是检查CPU负载的,等等。每一个插件可以通过运行./check_xxx –h 来查看其使用方法和功能。 Nagios可以识别4种状态返回信息,即 0(OK)表示状态正常/绿色、1(WARNING)表示出现警告/黄色、2(CRITICAL)表示出现非常严重的错误/红色、3(UNKNOWN)表示未知错误/深黄色。Nagios根据插件返回来的值,来判断监控对象的状态,并通过web显示出来,以供管理员及时发现故障。

再说报警功能,如果监控系统发现问题不能报警那就没有意义了,所以报警也是nagios很重要的功能之一。但是,同样的,Nagios 自身也没有报警部分的代码,甚至没有插件,而是交给用户或者其他相关开源项目组去完成的。 Nagios 安装,是指基本平台,也就是Nagios软件包的安装。它是监控体系的框架,也是所有监控的基础。 打开Nagios官方的文档,会发现Nagios基本上没有什么依赖包,只要求系统是Linux或者其他Nagios支持的系统。不过如果你没有安装apache(http服务),那么你就没有那么直观的界面来查看监控信息了,所以apache姑且算是一个前提条件。关于apache的安装,网上有很多,照着安装就是了。安装之后要检查一下是否可以正常工作。 知道Nagios 是如何通过插件来管理服务器对象后,现在开始研究它是如何管理远端服务器对象的。Nagios 系统提供了一个插件NRPE。Nagios 通过周期性的运行它来获得远端服务器的各种状态信息。它们之间的关系如下图所示:
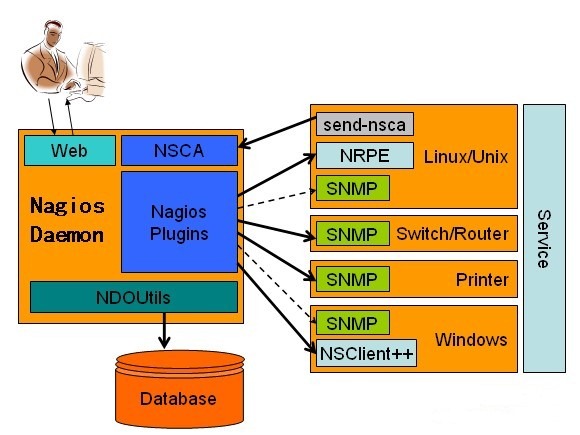
Nagios 通过NRPE 来远端管理服务 1. Nagios 执行安装在它里面的check_nrpe 插件,并告诉check_nrpe 去检测哪些服务。 2. 通过SSL,check_nrpe 连接远端机子上的NRPE daemon 3. NRPE 运行本地的各种插件去检测本地的服务和状态(check_disk,..etc) 4. 最后,NRPE 把检测的结果传给主机端的check_nrpe,check_nrpe 再把结果送到Nagios状态队列中。 5. Nagios 依次读取队列中的信息,再把结果显示出来。
三、安装服务端
我的centos6.8安装在kvm虚机中
服务端hostname vserver ip地址192.168.122.232
查看是否安装过以下软件包 # rpm -q gcc glibc glibc-common gd gd-devel xinetd openssl-devel
如果有没安装的就通过yum install安装
创建用户 用户组 文件夹 # useradd -s /sbin/nologin nagios # mkdir /usr/local/nagios # chown -R nagios.nagios /usr/local/nagios
去官网downdoal最新安装包
# tar zxvf nagios-4.2.1.tar.gz # cd nagios #./configure --help #根据需要选择自己的配置属性 # ./configure --prefix=/usr/local/nagios
#make all
#make install
#make install-init
#make install-commandmode
#make install-config
设置服务自启动和运行级别
# chkconfig --add nagios # chkconfig --level 35 nagios on # chkconfig --list nagios
***目录说明
bin Nagios 可执行程序所在目录 etc Nagios 配置文件所在目录 sbin Nagios CGI 文件所在目录,也就是执行外部命令所需文件所在的目录 share Nagios网页文件所在的目录 libexec Nagios 外部插件所在目录 var Nagios 日志文件、lock 等文件所在的目录 var/archives Nagios 日志自动归档目录 var/rw 用来存放外部命令文件的目录
安装Nagios 插件,同样先去官网下载安装包
# tar zxvf nagios-plugins-1.4.16.tar.gz # cd nagios-plugins-1.4.16 # ./configure --prefix=/usr/local/nagios # make && make install
!!!
注意Apache 和Php 不是安装nagios 所必须的,但是nagios提供了web监控界面,通过web监控界面可以清晰的看到被监控主机、资源的运行状态,因此,安装一个web服务是很必要的。
需要注意的是,nagios在nagios3.1.x版本以后,配置web监控界面时需要php的支持。这里我们下载的nagios版本为nagios-4.2.0,因此在编译安装完成apache后,还需要编译php模块,这里选取的php版本为php5版本。
你可以选择直接yum install 也可以自行安装
附上参考的安装步骤
# wget http://archive.apache.org/dist/httpd/httpd-2.2.23.tar.gz
# tar zxvf httpd-2.2.23.tar.gz
# cd httpd-2.2.23
# ./configure --prefix=/usr/local/apache2
# make && make install
若出现错误:

则在编译时入加 --with-included-apr 即可解决。
# wget http://cn2.php.net/distributions/php-5.4.10.tar.gz
# tar zxvf php-5.4.10.tar.gz
# cd php-5.4.10
# ./configure --prefix=/usr/local/php --with-apxs2=/usr/local/apache2/bin/apxs
# make && make install
apache的配置很重要,特别是认证
配置apache
找到apache 的配置文件/usr/local/apache2/conf/httpd.conf
找到:
User daemon
Group daemon
修改为
User nagios
Group nagios
然后找到
<IfModule dir_module>
DirectoryIndex index.html
</IfModule>
修改为
<IfModule dir_module>
DirectoryIndex index.html index.php
</IfModule>
接着增加如下内容:
AddType application/x-httpd-php .php
为了安全起见,一般情况下要让nagios 的web 监控页面必须经过授权才能访问,这需要增加验证配置,即在httpd.conf 文件最后添加如下信息:
#setting for nagios
ScriptAlias /nagios/cgi-bin "/usr/local/nagios/sbin"
<Directory "/usr/local/nagios/sbin">
AuthType Basic
Options ExecCGI
AllowOverride None
Order allow,deny
Allow from all
AuthName "Nagios Access"
AuthUserFile /usr/local/nagios/etc/htpasswd //用于此目录访问身份验证的文件
Require valid-user
</Directory>
Alias /nagios "/usr/local/nagios/share"
<Directory "/usr/local/nagios/share">
AuthType Basic
Options None
AllowOverride None
Order allow,deny
Allow from all
AuthName "nagios Access"
AuthUserFile /usr/local/nagios/etc/htpasswd
Require valid-user
</Directory>
同时
在上面的配置中,指定了目录验证文件htpasswd,下面要创建这个文件:
# /usr/local/apache2/bin/htpasswd -c /usr/local/nagios/etc/htpasswd name(随意指定)
PS:如果忘记密码或者因为其他情况不知道nagios默认的密码(一般情况下,默认用户和密码都是nagiosadmin),比如采用RDO安装openstack时,默认会安装nagios,mitaka版本下,使用nagios的默认密码无法通过验证,所以需要重设密码,密码重设方法:
htpasswd -c /usr/local/nagios/etc/htpasswd(这是我的实验环境的路径,如果通过RDO安装也可能在lib64目录下) name (指定用户名),然后重新输入两遍密码即可。
这样就在/usr/local/nagios/etc 目录下创建了一个htpasswd 验证文件,当通过http://192.168.122.232/nagios/ 访问时就需要输入用户名和密码了。
最后 重启apache
#service httpd restart
或
# /usr/local/apache2/bin/apachectl start
四 配置Nagios
在安装nagios后 访问浏览器http://192.168.122.232/nagios可以访问到nagios页面 但是却不能监控任何对象 需要进行详细配置
Nagios 安装完毕后,默认的配置文件在/usr/local/nagios/etc目录下。

每个文件或目录含义如下表所示:
| 文件名或目录名 | 用途 |
| cgi.cfg | 控制CGI访问的配置文件 |
| nagios.cfg | Nagios 主配置文件 |
| resource.cfg | 变量定义文件,又称为资源文件,在些文件中定义变量,以便由其他配置文件引用,如$USER1$ |
| objects | objects 是一个目录,在此目录下有很多配置文件模板,用于定义Nagios 对象 |
| objects/commands.cfg | 命令定义配置文件,其中定义的命令可以被其他配置文件引用 |
| objects/contacts.cfg | 定义联系人和联系人组的配置文件 |
| objects/localhost.cfg | 定义监控本地主机的配置文件 |
| objects/printer.cfg | 定义监控打印机的一个配置文件模板,默认没有启用此文件 |
| objects/switch.cfg | 定义监控路由器的一个配置文件模板,默认没有启用此文件 |
| objects/templates.cfg | 定义主机和服务的一个模板配置文件,可以在其他配置文件中引用 |
| objects/timeperiods.cfg | 定义Nagios 监控时间段的配置文件 |
| objects/windows.cfg | 监控Windows 主机的一个配置文件模板,默认没有启用此文件 |
在nagios的配置过程中涉及到的几个定义有:主机、主机组,服务、服务组,联系人、联系人组,监控时间,监控命令等,从这些定义可以看出,nagios各个配置文件之间是互为关联,彼此引用的。
成功配置出一台nagios监控系统,必须要弄清楚每个配置文件之间依赖与被依赖的关系,最重要的有四点:
第一:定义监控哪些主机、主机组、服务和服务组;
第二:定义这个监控要用什么命令实现;
第三:定义监控的时间段;
第四:定义主机或服务出现问题时要通知的联系人和联系人组。
为了能更清楚的说明问题,同时也为了维护方便,建议将nagios各个定义对象创建独立的配置文件:
- 创建hosts.cfg文件来定义主机和主机组
- 创建services.cfg文件来定义服务
- 用默认的contacts.cfg文件来定义联系人和联系人组
- 用默认的commands.cfg文件来定义命令
- 用默认的timeperiods.cfg来定义监控时间段
- 用默认的templates.cfg文件作为资源引用文件
a. templates.cfg文件
为了不必重复定义一些监控对象,Nagios引入了一个模板配置文件,将一些共性的属性定义成模板,以便于多次引用。这就是templates.cfg的作用。
下面详细介绍下templates.cfg文件中每个参数的含义:
1 define contact{ 2 name generic-contact ; 联系人名称 3 service_notification_period 24x7 ; 当服务出现异常时,发送通知的时间段,这个时间段"24x7"在timeperiods.cfg文件中定义 4 host_notification_period 24x7 ; 当主机出现异常时,发送通知的时间段,这个时间段"24x7"在timeperiods.cfg文件中定义 5 service_notification_options w,u,c,r ; 这个定义的是“通知可以被发出的情况”。w即warn,表示警告状态,u即unknown,表示不明状态; 6 ; c即critical,表示紧急状态,r即recovery,表示恢复状态; 7 ; 也就是在服务出现警告状态、未知状态、紧急状态和重新恢复状态时都发送通知给使用者。 8 host_notification_options d,u,r ; 定义主机在什么状态下需要发送通知给使用者,d即down,表示宕机状态; 9 ; u即unreachable,表示不可到达状态,r即recovery,表示重新恢复状态。 10 service_notification_commands notify-service-by-email ; 服务故障时,发送通知的方式,可以是邮件和短信,这里发送的方式是邮件; 11 ; 其中“notify-service-by-email”在commands.cfg文件中定义。 12 host_notification_commands notify-host-by-email ; 主机故障时,发送通知的方式,可以是邮件和短信,这里发送的方式是邮件; 13 ; 其中“notify-host-by-email”在commands.cfg文件中定义。 14 register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL CONTACT, JUST A TEMPLATE! 15 } 16 define host{ 17 name generic-host ; 主机名称,这里的主机名,并不是直接对应到真正机器的主机名; 18 ; 乃是对应到在主机配置文件里所设定的主机名。 19 notifications_enabled 1 ; Host notifications are enabled 20 event_handler_enabled 1 ; Host event handler is enabled 21 flap_detection_enabled 1 ; Flap detection is enabled 22 failure_prediction_enabled 1 ; Failure prediction is enabled 23 process_perf_data 1 ; 其值可以为0或1,其作用为是否启用Nagios的数据输出功能; 24 ; 如果将此项赋值为1,那么Nagios就会将收集的数据写入某个文件中,以备提取。 25 retain_status_information 1 ; Retain status information across program restarts 26 retain_nonstatus_information 1 ; Retain non-status information across program restarts 27 notification_period 24x7 ; 指定“发送通知”的时间段,也就是可以在什么时候发送通知给使用者。 28 register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE! 29 } 30 define host{ 31 name linux-server ; 主机名称 32 use generic-host ; use表示引用,也就是将主机generic-host的所有属性引用到linux-server中来; 33 ; 在nagios配置中,很多情况下会用到引用。 34 check_period 24x7 ; 这里的check_period告诉nagios检查主机的时间段 35 check_interval 5 ; nagios对主机的检查时间间隔,这里是5分钟。 36 retry_interval 1 ; 重试检查时间间隔,单位是分钟。 37 max_check_attempts 10 ; nagios对主机的最大检查次数,也就是nagios在检查发现某主机异常时,并不马上判断为异常状况; 38 ; 而是多试几次,因为有可能只是一时网络太拥挤,或是一些其他原因,让主机受到了一点影响; 39 ; 这里的10就是最多试10次的意思。 40 check_command check-host-alive ; 指定检查主机状态的命令,其中“check-host-alive”在commands.cfg文件中定义。 41 notification_period 24x7 ; 主机故障时,发送通知的时间范围,其中“workhours”在timeperiods.cfg中进行了定义; 42 ; 下面会陆续讲到。 43 notification_interval 10 ; 在主机出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟; 44 ; 如果你觉得,所有的事件只需要一次通知就够了,可以把这里的选项设为0 45 notification_options d,u,r ; 定义主机在什么状态下可以发送通知给使用者,d即down,表示宕机状态; 46 ; u即unreachable,表示不可到达状态; 47 ; r即recovery,表示重新恢复状态。 48 contact_groups ts ; 指定联系人组,这个“admins”在contacts.cfg文件中定义。 49 register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE! 50 } 51 define host{ 52 name windows-server ; The name of this host template 53 use generic-host ; Inherit default values from the generic-host template 54 check_period 24x7 ; By default, Windows servers are monitored round the clock 55 check_interval 5 ; Actively check the server every 5 minutes 56 retry_interval 1 ; Schedule host check retries at 1 minute intervals 57 max_check_attempts 10 ; Check each server 10 times (max) 58 check_command check-host-alive ; Default command to check if servers are "alive" 59 notification_period 24x7 ; Send notification out at any time - day or night 60 notification_interval 10 ; Resend notifications every 30 minutes 61 notification_options d,r ; Only send notifications for specific host states 62 contact_groups ts ; Notifications get sent to the admins by default 63 hostgroups windows-servers ; Host groups that Windows servers should be a member of 64 register 0 ; DONT REGISTER THIS - ITS JUST A TEMPLATE 65 } 66 define service{ 67 name generic-service ; 定义一个服务名称 68 active_checks_enabled 1 ; Active service checks are enabled 69 passive_checks_enabled 1 ; Passive service checks are enabled/accepted 70 parallelize_check 1 ; Active service checks should be parallelized; 71 ; (disabling this can lead to major performance problems) 72 obsess_over_service 1 ; We should obsess over this service (if necessary) 73 check_freshness 0 ; Default is to NOT check service 'freshness' 74 notifications_enabled 1 ; Service notifications are enabled 75 event_handler_enabled 1 ; Service event handler is enabled 76 flap_detection_enabled 1 ; Flap detection is enabled 77 failure_prediction_enabled 1 ; Failure prediction is enabled 78 process_perf_data 1 ; Process performance data 79 retain_status_information 1 ; Retain status information across program restarts 80 retain_nonstatus_information 1 ; Retain non-status information across program restarts 81 is_volatile 0 ; The service is not volatile 82 check_period 24x7 ; 这里的check_period告诉nagios检查服务的时间段。 83 max_check_attempts 3 ; nagios对服务的最大检查次数。 84 normal_check_interval 5 ; 此选项是用来设置服务检查时间间隔,也就是说,nagios这一次检查和下一次检查之间所隔的时间; 85 ; 这里是5分钟。 86 retry_check_interval 2 ; 重试检查时间间隔,单位是分钟。 87 contact_groups ts ; 指定联系人组 88 notification_options w,u,c,r ; 这个定义的是“通知可以被发出的情况”。w即warn,表示警告状态; 89 ; u即unknown,表示不明状态; 90 ; c即criticle,表示紧急状态,r即recover,表示恢复状态; 91 ; 也就是在服务出现警告状态、未知状态、紧急状态和重新恢复后都发送通知给使用者。 92 notification_interval 10 ; Re-notify about service problems every hour 93 notification_period 24x7 ; 指定“发送通知”的时间段,也就是可以在什么时候发送通知给使用者。 94 register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL SERVICE, JUST A TEMPLATE! 95 } 96 define service{ 97 name local-service ; The name of this service template 98 use generic-service ; Inherit default values from the generic-service definition 99 max_check_attempts 4 ; Re-check the service up to 4 times in order to determine its final (hard) state 100 normal_check_interval 5 ; Check the service every 5 minutes under normal conditions 101 retry_check_interval 1 ; Re-check the service every minute until a hard state can be determined 102 register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL SERVICE, JUST A TEMPLATE! 103 }
b. resource.cfg文件
resource.cfg是nagios的变量定义文件,文件内容只有一行:
$USER1$=/usr/local/nagios/libexec
其中,变量$USER1$指定了安装nagios插件的路径,如果把插件安装在了其它路径,只需在这里进行修改即可。需要注意的是,变量必须先定义,然后才能在其它配置文件中进行引用。
c. commands.cfg文件
此文件默认是存在的,无需修改即可使用,当然如果有新的命令需要加入时,在此文件进行添加即可。
1 #notify-host-by-email命令的定义 2 define command{ 3 command_name notify-host-by-email #命令名称,即定义了一个主机异常时发送邮件的命令。 4 command_line /usr/bin/printf "%b" "***** Nagios ***** Notification Type: $NOTIFICATIONTYPE$ Host: $HOSTNAME$ State: $HOSTSTATE$ Address: $HOSTADDRESS$ Info: $HOSTOUTPUT$ Date/Time: $LONGDATETIME$ " | /bin/mail -s "** $NOTIFICATIONTYPE$ Host Alert: $HOSTNAME$ is $HOSTSTATE$ **" $CONTACTEMAIL$ #命令具体的执行方式。 5 } 6 #notify-service-by-email命令的定义 7 define command{ 8 command_name notify-service-by-email #命令名称,即定义了一个服务异常时发送邮件的命令 9 command_line /usr/bin/printf "%b" "***** Nagios ***** Notification Type: $NOTIFICATIONTYPE$ Service: $SERVICEDESC$ Host: $HOSTALIAS$ Address: $HOSTADDRESS$ State: $SERVICESTATE$ Date/Time: $LONGDATETIME$ Additional Info: $SERVICEOUTPUT$ " | /bin/mail -s "** $NOTIFICATIONTYPE$ Service Alert: $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ **" $CONTACTEMAIL$ 10 } 11 #check-host-alive命令的定义 12 define command{ 13 command_name check-host-alive #命令名称,用来检测主机状态。 14 command_line $USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 5 15 # 这里的变量$USER1$在resource.cfg文件中进行定义,即$USER1$=/usr/local/nagios/libexec; 16 # 那么check_ping的完整路径为/usr/local/nagios/libexec/check_ping; 17 # “-w 3000.0,80%”中“-w”说明后面的一对值对应的是“WARNING”状态,“80%”是其临界值。 18 # “-c 5000.0,100%”中“-c”说明后面的一对值对应的是“CRITICAL”,“100%”是其临界值。 19 # “-p 1”说明每次探测发送一个包。 20 } 21 define command{ 22 command_name check_local_disk 23 command_line $USER1$/check_disk -w $ARG1$ -c $ARG2$ -p $ARG3$ #$ARG1$是指在调用这个命令的时候,命令后面的第一个参数。 24 } 25 define command{ 26 command_name check_local_load 27 command_line $USER1$/check_load -w $ARG1$ -c $ARG2$ 28 } 29 define command{ 30 command_name check_local_procs 31 command_line $USER1$/check_procs -w $ARG1$ -c $ARG2$ -s $ARG3$ 32 } 33 define command{ 34 command_name check_local_users 35 command_line $USER1$/check_users -w $ARG1$ -c $ARG2$ 36 } 37 define command{ 38 command_name check_local_swap 39 command_line $USER1$/check_swap -w $ARG1$ -c $ARG2$ 40 } 41 define command{ 42 command_name check_ftp 43 command_line $USER1$/check_ftp -H $HOSTADDRESS$ $ARG1$ 44 } 45 define command{ 46 command_name check_http 47 command_line $USER1$/check_http -I $HOSTADDRESS$ $ARG1$ 48 } 49 define command{ 50 command_name check_ssh 51 command_line $USER1$/check_ssh $ARG1$ $HOSTADDRESS$ 52 } 53 define command{ 54 command_name check_ping 55 command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5 56 } 57 define command{ 58 command_name check_nt 59 command_line $USER1$/check_nt -H $HOSTADDRESS$ -p 12489 -v $ARG1$ $ARG2$ 60 }
d. hosts.cfg文件
此文件默认不存在,需要手动创建,hosts.cfg主要用来指定被监控的主机地址以及相关属性信息,根据实验目标配置如下:
define host{ use linux-server #引用主机linux-server的属性信息,linux-server主机在templates.cfg文件中进行了定义。 host_name vserver #主机名 alias vserver #主机别名 address 192.168.122.232 #被监控的主机地址,这个地址可以是ip,也可以是域名。 } #定义一个主机组 define hostgroup{ hostgroup_name bsmart-servers #主机组名称,可以随意指定。 alias bsmart servers #主机组别名 members Nagios-Linux #主机组成员,其中“Nagios-Linux”就是上面定义的主机。 }
注意:在/usr/local/nagios/etc/objects 下默认有localhost.cfg 和windows.cfg 这两个配置文件,localhost.cfg 文件是定义监控主机本身的,windows.cfg 文件是定义windows 主机的,其中包括了对host 和相关services 的定义。所以在本次实验中,将直接在localhost.cfg 中定义监控主机(Nagios-Server),在windows.cfg中定义windows 主机(Nagios-Windows)。根据自己的需要修改其中的相关配置,详细如下:
1 define host{ 2 use linux-server ; Name of host template to use 3 ; This host definition will inherit all variables that are defined 4 ; in (or inherited by) the linux-server host template definition. 5 host_name vserver 6 alias vserver 7 address 127.0.0.1 8 } 9 define hostgroup{ 10 hostgroup_name linux-servers ; The name of the hostgroup 11 alias Linux Servers ; Long name of the group 12 members vserver ; Comma separated list of hosts that belong to this group 13 } 14 define service{ 15 use local-service ; Name of service template to use 16 host_name vserver 17 service_description PING 18 check_command check_ping!100.0,20%!500.0,60% 19 } 20 define service{ 21 use local-service ; Name of service template to use 22 host_name vserver 23 service_description Root Partition 24 check_command check_local_disk!20%!10%!/ 25 } 26 define service{ 27 use local-service ; Name of service template to use 28 host_name vserver 29 service_description Current Users 30 check_command check_local_users!20!50 31 } 32 define service{ 33 use local-service ; Name of service template to use 34 host_name vserver 35 service_description Total Processes 36 check_command check_local_procs!250!400!RSZDT 37 } 38 define service{ 39 use local-service ; Name of service template to use 40 host_name vserver 41 service_description Current Load 42 check_command check_local_load!5.0,4.0,3.0!10.0,6.0,4.0 43 } 44 define service{ 45 use local-service ; Name of service template to use 46 host_name vserver 47 service_description Swap Usage 48 check_command check_local_swap!20!10 49 } 50 define service{ 51 use local-service ; Name of service template to use 52 host_name vserver 53 service_description SSH 54 check_command check_ssh 55 notifications_enabled 0 56 } 57 define service{ 58 use local-service ; Name of service template to use 59 host_name vserver 60 service_description HTTP 61 check_command check_http 62 notifications_enabled 0 63 }
同时也根据参考文章附上windows的,注意 :由于我附上了windows的的配置但并没有添加windown的虚机 所以会在监控时出现相关报警信息
1 define host{ 2 use windows-server ; Inherit default values from a template 3 host_name Nagios-Windows ; The name we're giving to this host 4 alias My Windows Server ; A longer name associated with the host 5 address 192.168.1.113 ; IP address of the host 6 } 7 define hostgroup{ 8 hostgroup_name windows-servers ; The name of the hostgroup 9 alias Windows Servers ; Long name of the group 10 } 11 define service{ 12 use generic-service 13 host_name Nagios-Windows 14 service_description NSClient++ Version 15 check_command check_nt!CLIENTVERSION 16 } 17 define service{ 18 use generic-service 19 host_name Nagios-Windows 20 service_description Uptime 21 check_command check_nt!UPTIME 22 } 23 define service{ 24 use generic-service 25 host_name Nagios-Windows 26 service_description CPU Load 27 check_command check_nt!CPULOAD!-l 5,80,90 28 } 29 define service{ 30 use generic-service 31 host_name Nagios-Windows 32 service_description Memory Usage 33 check_command check_nt!MEMUSE!-w 80 -c 90 34 } 35 define service{ 36 use generic-service 37 host_name Nagios-Windows 38 service_description C: Drive Space 39 check_command check_nt!USEDDISKSPACE!-l c -w 80 -c 90 40 } 41 define service{ 42 use generic-service 43 host_name Nagios-Windows 44 service_description W3SVC 45 check_command check_nt!SERVICESTATE!-d SHOWALL -l W3SVC 46 } 47 define service{ 48 use generic-service 49 host_name Nagios-Windows 50 service_description Explorer 51 check_command check_nt!PROCSTATE!-d SHOWALL -l Explorer.exe 52 }
e. services.cfg文件
此文件默认也不存在,需要手动创建,services.cfg文件主要用于定义监控的服务和主机资源,例如监控http服务、ftp服务、主机磁盘空间、主机系统负载等等。
f. contacts.cfg文件
contacts.cfg是一个定义联系人和联系人组的配置文件,当监控的主机或者服务出现故障,nagios会通过指定的通知方式(邮件或者短信)将信息发给这里指定的联系人或者使用者。
1 define contact{ 2 contact_name name #联系人的名称,这个地方不要有空格 3 use generic-contact #引用generic-contact的属性信息,其中“generic-contact”在templates.cfg文件中进行定义 4 alias Admin 5 email name@emailadress.cn 6 } 7 8 define contactgroup{ 9 contactgroup_name ts #联系人组的名称,同样不能空格 10 alias Technical Support #联系人组描述 11 members name #联系人组成员,其中“david”就是上面定义的联系人,如果有多个联系人则以逗号相隔 12 }
g. timeperiods.cfg文件
此文件只要用于定义监控的时间段,下面是一个配置好的实例:
1 #下面是定义一个名为24x7的时间段,即监控所有时间段 2 define timeperiod{ 3 timeperiod_name 24x7 #时间段的名称,这个地方不要有空格 4 alias 24 Hours A Day, 7 Days A Week 5 sunday 00:00-24:00 6 monday 00:00-24:00 7 tuesday 00:00-24:00 8 wednesday 00:00-24:00 9 thursday 00:00-24:00 10 friday 00:00-24:00 11 saturday 00:00-24:00 12 } 13 #下面是定义一个名为workhours的时间段,即工作时间段。 14 define timeperiod{ 15 timeperiod_name workhours 16 alias Normal Work Hours 17 monday 09:00-17:00 18 tuesday 09:00-17:00 19 wednesday 09:00-17:00 20 thursday 09:00-17:00 21 friday 09:00-17:00 22 }
h. cgi.cfg文件
此文件用来控制相关cgi脚本,如果想在nagios的web监控界面执行cgi脚本,例如重启nagios进程、关闭nagios通知、停止nagios主机检测等,这时就需要配置cgi.cfg文件了。
由于nagios的web监控界面验证用户为name,所以只需在cgi.cfg文件中添加此用户的执行权限就可以了,需要修改的配置信息如下:
1 default_user_name=name 2 authorized_for_system_information=nagiosadmin,name 3 authorized_for_configuration_information=nagiosadmin,name 4 authorized_for_system_commands=name 5 authorized_for_all_services=nagiosadmin,name 6 authorized_for_all_hosts=nagiosadmin,name 7 authorized_for_all_service_commands=nagiosadmin,name 8 authorized_for_all_host_commands=nagiosadmin,name
i. nagios.cfg文件
nagios.cfg默认的路径为/usr/local/nagios/etc/nagios.cfg,是nagios的核心配置文件,所有的对象配置文件都必须在这个文件中进行定义才能发挥其作用,这里只需将对象配置文件在Nagios.cfg文件中进行引用即可。
1 log_file=/usr/local/nagios/var/nagios.log # 定义nagios日志文件的路径 2 cfg_file=/usr/local/nagios/etc/objects/commands.cfg # “cfg_file”变量用来引用对象配置文件,如果有更多的对象配置文件,在这里依次添加即可。 3 cfg_file=/usr/local/nagios/etc/objects/contacts.cfg 4 cfg_file=/usr/local/nagios/etc/objects/hosts.cfg 5 cfg_file=/usr/local/nagios/etc/objects/services.cfg 6 cfg_file=/usr/local/nagios/etc/objects/timeperiods.cfg 7 cfg_file=/usr/local/nagios/etc/objects/templates.cfg 8 cfg_file=/usr/local/nagios/etc/objects/localhost.cfg # 本机配置文件 9 cfg_file=/usr/local/nagios/etc/objects/windows.cfg # windows 主机配置文件 10 object_cache_file=/usr/local/nagios/var/objects.cache # 该变量用于指定一个“所有对象配置文件”的副本文件,或者叫对象缓冲文件 11 precached_object_file=/usr/local/nagios/var/objects.precache 12 resource_file=/usr/local/nagios/etc/resource.cfg # 该变量用于指定nagios资源文件的路径,可以在nagios.cfg中定义多个资源文件。 13 status_file=/usr/local/nagios/var/status.dat # 该变量用于定义一个状态文件,此文件用于保存nagios的当前状态、注释和宕机信息等。 14 status_update_interval=10 # 该变量用于定义状态文件(即status.dat)的更新时间间隔,单位是秒,最小更新间隔是1秒。 15 nagios_user=nagios # 该变量指定了Nagios进程使用哪个用户运行。 16 nagios_group=nagios # 该变量用于指定Nagios使用哪个用户组运行。 17 check_external_commands=1 # 该变量用于设置是否允许nagios在web监控界面运行cgi命令; 18 # 也就是是否允许nagios在web界面下执行重启nagios、停止主机/服务检查等操作; 19 # “1”为运行,“0”为不允许。 20 command_check_interval=10s # 该变量用于设置nagios对外部命令检测的时间间隔,如果指定了一个数字加一个"s"(如10s); 21 # 那么外部检测命令的间隔是这个数值以秒为单位的时间间隔; 22 # 如果没有用"s",那么外部检测命令的间隔是以这个数值的“时间单位”的时间间隔。 23 interval_length=60 # 该变量指定了nagios的时间单位,默认值是60秒,也就是1分钟; 24 # 即在nagios配置中所有的时间单位都是分钟。
五、验证
# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
当初先类似界面则验证通过

看到上面这些信息就说明没问题了,然后启动Nagios 服务。
六、启动
# /etc/init.d/nagios start
or
# service nagios start
# /usr/local/nagios/bin/nagios -d /usr/local/nagios/etc/nagios.cfg
当修改了配置文件让其生效时,需要重启/重载Nagios服务。
通过初始化脚本来重启nagios
# /etc/init.d/nagios reload
or
# /etc/init.d/nagios restart
or
# service nagios restart
or
通过web监控页重启nagios
可以通过web监控页的 "Process Info" -> "Restart the Nagios process"来重启nagios
接下来会重点研究 NSCA(被动监控),NRPE(远程监控插件), cacti(界面强化)